Java I/O, NIO and NIO.2 (自译)
Java I/O, NIO and NIO.2
PART Ⅰ Getting Started with I/O
Chapter 1 I/O Basics and APIs
NIO作为JDK 1.4的一部分被引入来支持操作系统的新的I/O规范。由于时间不够,没能把一些计划的特性加到这个release,被推迟到了JDK 5 and JDK 7。
这章介绍classic I/O, NIO, and more NIO (NIO.2)。接下来的章节深入研究它们的api。
Classic I/O
JDK1.0引进初步的I/O设施,用于访问文件系统(创建文件夹,删除文件等操作),随机访问文件目录(而不是按顺序),和源和目标之间以顺序方式的面向字节数据流。
File System Access and the File Class
file system是操作系统组件管理数据储存和后续检索。运行JVM的操作系统支持至少一个文件系统。例如,Unix或Linux结合所有安装(attached and prepared))的disks到一个虚拟文件系统。与此相反,Windows把一个分割的文件系统和每个活动的磁盘驱动器联系起来。
Windows和类似的操作系统可以管理多个文件系统。 每个文件系统都用一个驱动器说明符来标识,比如C:。 指定一条没有驱动器说明符的路径,路径是相对于当前文件系统。
一个 java.io.File 类实例抽象一个文件或者文件路径。这个实例提供文件系统访问来在这个path上执行任务比如移除下面的文件和文件夹。比如:
new File("temp").mkdir();
Accessing File Content via RandomAccessFile
文件内容可以按顺序或随机访问。随机访问可以加快搜索和排序功能。在 java. io.RandomAccessFile 类提供随机访问文件。例如:
RandomAccessFile raf = new RandomAccessFile("employees.dat", "r");
int empIndex = 10;
raf.seek(empIndex * EMP_REC_LEN);
// Read contents of employee record.
employees.dat文件被分割成固定长度的employees记录,每个记录 EMP_REC_LEN bytes长,被访问。第10个索引的employee被查找(第一个index 0)。这个任务通过seeking(设置file pointer)这个记录的第一个字节的字节位置,它处于记录长度乘索引。记录然后被访问。
Streaming Data via Stream Classes
Classic I/O 包含streams用于执行I/O操作。流是任意长度的有顺序的bytes sequence。bytes从应用的output stream流出到目的地,和从一个source的input stream流出到应用。
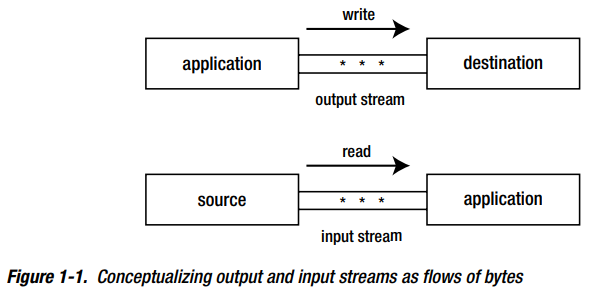
Java在 java.io 包提供类用于识别用于writing的stream destinations;例如byte arrays和files。也提供类识别各种stream sources用于reading。例子包括files和 thread pipes。
例如,你会用 FileInputStream打开一个存在的文件,并且用一个 input stream连接它。你会用各种 read() 方法通过input stream从file读取字节。最后,调用close() 关闭stream和文件。例如:
FileInputStream fis = null;
try
{
fis = new FileInputStream("image.jpg");
// Read bytes from file.
int _byte;
while ((_byte = fis.read()) != -1) // -1 signifies EOF
; // Process _byte in some way.
}
catch (IOException ioe)
{
// Handle exception.
}
finally
{
if (fis != null)
try
{
fis.close();
}
}
这个例子展示了打开文件一个文件的传统方法且创建一个输入流从文件中读取字节。然后它继续读取文件的内容。异常处理程序负责处理抛出的异常,由java.io.IOException表示。
不管有没有抛出异常,输入流和之下的文件必须关闭。这个动作发生在try声明的finally块。因为关闭文件的冗长,你可以选择用JDK 7的try-with-resources陈述来自动关闭,如下:
try (FileInputStream fis = new FileInputStream("image.jpg"))
{
// Read bytes from file.
int _byte;
while ((_byte = fis.read()) != -1) // -1 signifies EOF
; // Process _byte in some way.
}
catch (IOException ioe)
{
// Handle exception.
}
一些stream类用于过滤其他stream。例如,为了提升性能, BufferedInputStream 从其他stream读取一块bytes,从它的buffer返回字节直到buffer空为止,然后读取另一块。例如:
try (FileInputStream fis = new FileInputStream("image.jpg");
BufferedInputStream bis = new BufferedInputStream(fis))
{
// Read bytes from file.
int _byte;
while ((_byte = bis.read()) != -1) // -1 signifies EOF
; // Process _byte in some way.
}
catch (IOException ioe)
{
// Handle exception.
}
从image.jpg 读取的 file input stream被创建。这个stream被转换成buffered输入流构造器。随后的读在buffered input stream上执行,它在合适时候调用file input stream的read()。
Stream Classes and Standard I/O
很多操作系统支持标准I/O, preconnected streams被称为 standard input, standard output, and standard error。
标准输入默认从键盘输入。然而,也可以重定向从不同的源读输出到不同的目的地,比如文件。
JDK 1.0引入标准I/O支持通过添加InputStream and PrintStream类型的in, out, and err o对象到java.lang.System 类。你指定调用这些对象的方法来连接标准输入输出和error,如下:
int ch = System.in.read(); // Read single character from standard input.
System.out.println("Hello"); // Write string to standard output.
System.err.println("I/O error: " +
ioe.getMessage()); // Write string to standard error.
JDK 1.1 and the Writer/Reader Classes
JDK 1.0的I/O适合字节流,但不适合字符流因为不考虑字符编码。JDK 1.1引入了 writer/reader类克服这个问题,把字符编码考虑了在内。例如java.io 包含有s FileWriter and FileReader 类用于读写字符流。
NIO
现代操作系统提供精致的I/O服务(比如readiness selection)用于提升I/O性能与简化I/O。 Java Specification Request (JSR) 51 (www.jcp.org/en/jsr/detail?id=51) 被创建用于落地这个特性。
JSR 51的描述表明提供了APIs用于可伸缩I/O, fast buffered binary and character I/O ,正则表达式和字符集转换。这些APIs就是NIO。JDK1.4在以下APIs方面实现NIO:
- Buffers
- Channels
- Selectors
- Regular expression
- Charsets
regular expression and charset APIs被提供给简化常规与I/O有联系的tasks。
Buffers
Buffers(缓冲区)是NIO操作的基础。本质上,NIO全部都是关于把数据从Buffers移入或移出。
一个过程比如JVM执行I/O通过请求操作系统去排干buffer的内容来通过写操作存储。类似地,它请求操作系统用从存储设备读取的数据填充buffer。
考虑一个涉及磁盘驱动的读操作。操作系统发出一个指令到磁盘controller来读取磁盘的一块字节到一个操作系统的buffer。一旦操作完成,操作系统复制这个buffer contents到发生read()操作的指定的buffer。
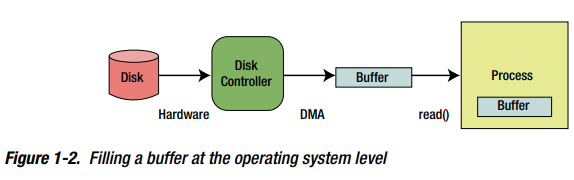
图1-2中一个程序向操作系统发起一个 read() 调用。依次地,操作系统请求磁盘controller从磁盘读取一块bytes。磁盘controller(也叫DMA controller)通过Direct Memory Access (DMA)直接把这些字节读到操作系统buffer,DMA是计算机系统的一个特性,允许某个硬件子系统不依赖 central processing unit (CPU) 直接访问 系统内存 (RAM) 。
从操作系统buffer复制 bytes到程序buffer是不那么高效的。让DMA controller直接复制到程序buffer会更有效,这个方法有2个问题:
- DMA controller特别是不能和JVM运行其上的user space(用户空间)连接,而是和 operating system’s kernel space(操作系统内核空间)连接。
- Block-oriented设备比如DMA controller使用固定大小的数据块工作。不同的是,JVM程序可能会请求一个不是block size倍数大小的数据。
因为这些问题,操作系统作为一个中介角色,当它在JVM程序和DMA controller切换时扯碎和重组数据。
装配/拆卸数据的任务可以更有效,通过让JVM程序在一个系统调用传递一个buffer addresses给操作系统。操作系统按顺序填充或者排干这些buffer,在一个读操作分散数据到多个buffer或者在写操作时从多个buffer聚集数据。这个聚集/分散的活动减少了JVM程序必须要做的系统调用(潜在地很昂贵)并且使操作系统优化数据处理因为系统知道buffer空间的总数。此外,当多个处理器或内核可用,操作系统可能允许buffers同时填充或者排干。
JDK 1.4的 java.nio.Buffer类抽象了JVM程序buffer的概念。作为java.nio.ByteBuffer和其他类的父类。因为I/O根本上是面向字节的,只有 ByteBuffer 实例可以用channels。大多数其他Buffer的子类方便于处理multibyte数据(例如characters or integers)。
Channels
强制CPU执行I/O任务并等待I/O完成(这样的CPU被叫做 I/O bound)是资源的浪费。将这些任务卸载到DMA controller可以改善性能,处理器可以做其他工作。
一个channel充当一个管道用于连接DMA controller来从硬盘有效排干或填充字节数据。JDK 1.4的java.nio.channels.Channel 接口,它的子接口和众多类实现了channel架构。
其中一个类是 java.nio.channels.FileChannel,抽象了一个channel用于读写映射操作文件。 FileChannel 的一个有趣的特性是支持file locking,在这些复杂的应用程序中,如数据库管理系统。
File locking让程序在访问文件的时候阻止或限制对文件的访问。尽管文件锁定可以应用到整个文件中,但它通常会缩小到一个更小的区域。一个锁的范围从一个起始字节偏移量开始到持续指定数量的字节。
FileChannel另一个有趣的特性是 memory-mapped file I/O,通过map() 方法,返回一个 java.nio.MappedByteBuffer 它的内容是文件的memory-mapped region。文件内容通过内存访问被访问。缓冲区复制和读-写系统调用被消除。
你可以调用java.nio.channels.Channels类或者经典I/O类比如 RandomAccessFile 的方法来获得一个channel。
Selectors
I/O被分类为block-oriented 或 stream-oriented。从一个文件读或写入一个文件是block-oriented I/O的例子。相比之下,从键盘读或写入到网络连接是stream-oriented I/O的例子。
Stream I/O 通常比block I/O慢。另外,输入往往是间歇的。例如,用户可能会输入字符流然后暂停,或者网络连接的短暂延迟导致视频断续播放。
很多操作系统允许 streams 被配置成nonblocking mode,一个线程不断地检查可用的输入,如果没有输入,就不阻塞。线程可以处理传入的数据或在数据来之前处理其他工作。
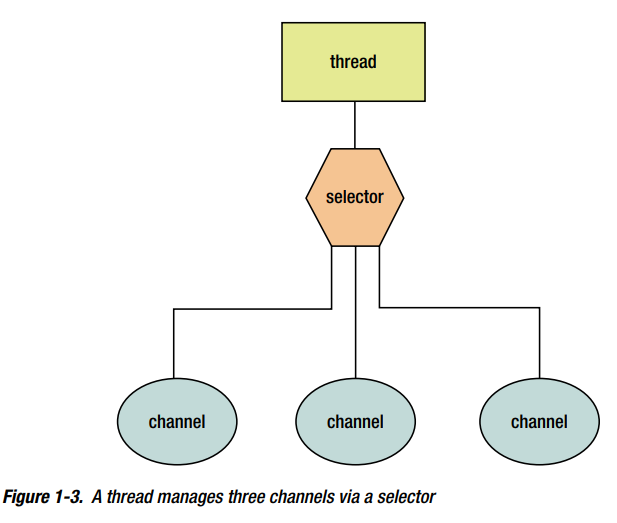
“polling for available input”(轮询可用输入)活动是浪费的,特别是线程需要监控许多输入流(比如在 web server context)。现代操作系统可以高效地做这个检查,被称为 readiness selection ,通常建立在非阻塞模式上。操作系统监控一个streams的集合并且返回给线程指示哪个streams准备好了做I/O操作。因此,一个单线程可以 multiplex(多路复用)许多活跃的streams,使通过普通代码在web server context管理巨量网络连接成为可能。
JDK 1.4通过提供selectors提供readiness selection,是java.nio.channels.Selector类的实例,可以检查一个或者多个channels并决定哪个channels准备好读写。通过这种方式,单个线程可以有效管理多个channels(因此,多个网络连接)。能使用更少的线程是有利的,因为线程的创建和线程上下文的切换对性能或内存使用来说都很昂贵。
Regular Expressions
正则表达式作为NIO一部分引入。虽然你想知道做这个的原理(正则表达式对I/O做了什么),正则表达式通常用于扫描从文件或其他来源读取的文本数据。需要尽可能快地执行这些扫描,要求将其包含在内。JDK 1.4提供了正则表达式通过 java.util.regex 包和它的Pattern and Matcher 。
Charsets
之前提到JDK 1.1引入writer/reader类把字符编码考虑在内。最初,比如java.io.InputStreamReader 的类协同 java.io.ByteToCharConverter类工作来执行基于编码的转换。 ByteToCharConverter 从JDK 6开始最终弃用了。在这个位置,更能干的包 java.nio.charset 和它的Charset, CharsetEncoder, CharsetDecoder, and related types被引入。
Formatter
JSR 51提到一个简单的 printf-style格式化工具。这样一个设施在准备数据去呈现的时候提供有效值。然而,JDK 1.4没有包含这个能力,因为它依赖许多参数列表,一个JDK 5前还没引入的语言特性。幸运的是,JDK 5 包含了java.util.Formatter ,他有丰富的格式化能力,和支持自定义格式化的相关类型,以及添加 printf() (and related format()) 方法到 PrintStream 类。
NIO.2
JSR 51指出NIO将会引入改善的文件系统接口克服遗留File类的众多问题。然而,缺乏时间导致这个特性没包含。同时,也不可能支持 asynchronous I/O和完成 socket channel功能。JSR 203 (www.jcp.org/en/jsr/detail?id=203) 随后落实了这些遗漏,在JDK 7登场。
注意:被官方JDK 7之前, big buffers (buffers with 64-bit addressability) 被认为用于 NIO.2。比如 BigByteBuffer and MappedBigByteBuffer类计划被包含在 java.nio 或其他的包。然而,如同在e “BigByteBuffer/Mapped BigByteBuffer” OpenJDK 讨论话题中解释的,这个能力被遗弃了取而代之的是追求“64-bit arrays or collections”。
Improved File System Interface
遗留的 File类有很多问题。例如renameTo() 方法跨操作系统不一致。同时,许多 File 的方法没有扩展;从服务器请求大目录列表导致 hang住。JSR 203的新操作系统接口修补了这些和其他的一些问题。例如,它支持对文件属性的批量访问,提供变更通知功能,提供了逃离到 file system-specific APIs的能力,和一个service provider接口用于可插拔文件系统实现。
Asynchronous I/O
Nonblocking mode通过阻止执行读写操作的线程在输入可用或输出被全部写入之前阻塞住,从而提高性能。然而,它不让应用决定它是否可以在不实际执行操作的情况下执行操作。例如,当一个非阻塞读操作成功了,应用程序不仅了解读取操作是可能的还已经阅读了一些必须管理的数据。这个 duality 是你不用把检查 stream readiness 的代码从数据执行代码分离,不用让你的代码明显复杂。
Asynchronous I/O 改善了这个问题,通过让线程开始操作并马上执行其他工作。线程指定一些 callback函数在操作完成了被调用。
Completion of Socket Channel Functionality
JDK 1.4添加了 DatagramChannel, ServerSocketChannel, and SocketChannel类到 java.nio.channels 包。然而,缺乏时间这些类不能支持绑定和选项配置。同时,也不支持o, channel-based multicast datagrams。JDK 7添加了绑定支持和选项配制到提到的类。同时,引入新的java.nio.channels .MulticastChannel接口。
Summary
I/O is fundamental to operating systems, computer languages, and language libraries. Java supports I/O through its classic I/O, NIO, and NIO.2 API categories.
Classic I/O provides APIs to access the file system, access file content randomly (as opposed to sequentially), stream byte-oriented data between sources and destinations, and support character streams.
NIO provides APIs to manage buffers, communicate buffered data over channels, leverage readiness selection via selectors, scan textual data quickly via regular expressions, specify character encodings via charsets, and support printf-style formatting.
NIO.2 provides APIs to improve the file system interface; support asynchronous I/O; and complete socket channel functionality by upgrading DatagramChannel, ServerSocketChannel, and SocketChannel, and by introducing a new MulticastChannel interface.
PART Ⅱ Classic I/O APIs
Chapter 2 File
Java使用 java.io.File 访问文件系统。
Constructing File Instances
一个 File 类实例包含一个文件或者目录路径的抽象表征。创建File实例,
File file1 = new File("/x/y");
File file2 = new File("C:\\temp\\x.dat");
第一行假设是 Unix/Linux 操作系统。window也可以,假设是当前驱动器。
注意:一个操作系统相关的分隔符(比如windows的\出现在路径的连续name之间 )
第二行假设是Windows系统,你也可以在windows用/。
都是绝对路径,从root开始;不需要其他信息定位文件。相比之下,相对路径不从root开始;需要另一个path的信息。
注意:java.io包的类默认解析相对路径在当前用户目录(working directory),由系统属性user.dir 指定,特别它是JVM被启动的路径。(调用java.lang.System类的 getProperty()方法获取系统属性)。
路径字符串到/从绝对路径的转换内部是依赖操作系统的。
注意:default name-separator character由系统属性 file.separator 定义,在File的public static separator and separatorChar fields 可用——第一个是 java.lang.String 第二个是char。
File提供额外构造器。例如:
- File(String parent, String child) creates a new
File instance from a parent path string and a child path string.
- File(File parent, String child) creates a new File
instance from a parent path File instance and a child path string
parent参数都被转化为parent path:
File file3 = new File("prj/books/", "io");
路径被合并为prj/books/io,如果parent是prj/books,会自动在最后加上/。
注意:因为File(String path), File(String parent, String child), and File(File parent, String child) 不检查无效路径参数(除了path或者child是null抛出 java.lang.NullPointerException ),你必须小心指定path。要力求所有操作系统都有效。例如,不使用硬编码(例如 C:),使用 listRoots()返回的root。最好,让你的path和user/working directory 相关(从 user.dir 返回的)。
Learning About Stored Abstract Paths
得到File对象后,你想询问他获取抽象存储路径,可以通过表2-1方法:
Table 2-1. File Methods for Learning About a Stored Abstract Path
| Method | Description |
|---|---|
| File getAbsoluteFile() | 返回文件对象 abstract path的 absolute form。这个方法等同于 new File(this.getAbsolutePath()) |
| String getAbsolutePath() | 返回绝对路径。当已经是绝对路径,返回和getPath()一样,当是空的 abstract path,返回当前用户目录字符串( user.dir )。否则,用操作系统方式解决。在 Unix/ Linux 操作系统,相对路径是在用户目录,window是在当前path命名的drive,如果没有drive是在用户目录。 |
| File getCanonicalFile() | 返回 canonical ( (simplest possible, absolute and unique)form。I/O错误发生时抛出 java.io.IOException (创建 canonical path需要文件系统查询);等同于 File(this.getCanonicalPath()). 。 |
| String getCanonicalPath() | 返回 canonical path string 。首先必要时转换为绝对路径,就像调用 getAbsolutePath() ,然后使用取决于操作系统的方式把它映射到 它的 unique form 。它特别地移除冗余 ,比如.. .符号,解析文件链接( Unix/Linux ),转换 drive letters 为标准形式(windows)。 |
| String getName() | 返回文件或文件夹名。是path name sequence最后的name。path name sequence为空返回空。 |
| String getParent() | 返回 parent path string ,如果没有parent,返回“null”(可以打印)。 |
| File getParentFile() | 返回parent文件夹;不是文件夹返回”null”。 |
| String getPath() | 返回 File’s separator field 分隔的字符串。 |
| boolean isAbsolute() | 绝对路径返回true;相对返回false。根据系统的。windows带有driver,后面有\,或者\\开头。Linux/Unix是/。 |
| String toString() | 同 getPath() |
Table 2-1 引用 IOException 。
Listing 2-1实例化File。
Listing 2-1. Obtaining Abstract Path Information
import java.io.File;
import java.io.IOException;
public class PathInfo
{
public static void main(final String[] args) throws IOException
{
if (args.length != 1)
{
System.err.println("usage: java PathInfo path");
return;
}
File file = new File(args[0]);
System.out.println("Absolute path = " + file.getAbsolutePath());
System.out.println("Canonical path = " + file.getCanonicalPath());
System.out.println("Name = " + file.getName());
System.out.println("Parent = " + file.getParent());
System.out.println("Path = " + file.getPath());
System.out.println("Is absolute = " + file.isAbsolute());
}
}
编译javac PathInfo.java,run java PathInfo . ,输出:
Absolute path = C:\prj\books\io\ch02\code\PathInfo\.
Canonical path = C:\prj\books\io\ch02\code\PathInfo
Name = .
Parent = null
Path = .
Is absolute = false
Canonical path没有.,没有parent。
继续 java PathInfo C:\reports\2015\..\2014\February ,输出:
Absolute path = C:\reports\2015\..\2014\February
Canonical path = C:\reports\2014\February
Name = February
Parent = C:\reports\2015\..\2014
Path = C:\reports\2015\..\2014\February
Is absolute = true
最后java PathInfo "" ,输出:
Absolute path = C:\prj\books\io\ch02\code\PathInfo
Canonical path = C:\prj\books\io\ch02\code\PathInfo
Name =
Parent = null
Path =
Is absolute = false
getName() and getPath() 返回空“”,因为empty path is empty 。
Learning About a Path’s File or Directory
你可以询问文件系统了解文件。
Table 2-2. File Methods for Learning About a File or Directory
| Method | Description |
|---|---|
| boolean exists() | 存在为true。 |
| boolean isDirectory() | 是存在的文件夹返回true。 |
| boolean isFile() | 一个normal的存在的文件返回true。normal指的是不是文件夹,满足其他操作系统的约束。例如不能是 symbolic link (符号链接)或 named pipe (命名管道)。Java创建的非文件夹文件都保证是一个normal文件。 |
| boolean isHidden() | 被隐藏返回true。隐藏的确切定义是依赖于操作系统的。 Unix/Linux是以.开头。windows是在文件系统被标记。 |
| long lastModified() | 上次更改的时间,文件不存在或者I/O错误是0。 返回的值是以毫秒为单位的,自从 Unix epoch (00:00:00 GMT, January 1, 1970)。 |
| long length() | file的length。是文件夹的返回值是 unspecified ,不存在是0。 |
示例如下。
Listing 2-2. Obtaining File/Directory Information
import java.io.File;
import java.io.IOException;
import java.util.Date;
public class FileDirectoryInfo
{
public static void main(final String[] args) throws IOException
{
if (args.length != 1)
{
System.err.println("usage: java FileDirectoryInfo pathname");
return;
}
File file = new File(args[0]);
System.out.println("About " + file + ":");
System.out.println("Exists = " + file.exists());
System.out.println("Is directory = " + file.isDirectory());
System.out.println("Is file = " + file.isFile());
System.out.println("Is hidden = " + file.isHidden());
System.out.println("Last modified = " +
new Date(file.lastModified()));
System.out.println("Length = " + file.length());
}
}
编译javac FileDirectoryInfo.java
run java FileDirectoryInfo x.dat
假设 x.dat 3个字节大。
输出:
About x.dat:
Exists = true
Is directory = false
Is file = true
Is hidden = false
Last modified = Sat Jul 25 15:49:41 CDT 2015
Length = 3
Listing File System Root Directories
File的方法File[] listRoots() 返回root文件夹。
注意: available file system roots的集合受系统级别操作影响,比如插入或拔出媒体,断开或卸载物理或虚拟磁盘驱动器。
Listing 2-3. Dumping Available File System Roots to Standard Output
public class DumpRoots
{
public static void main(String[] args)
{
File[] roots = File.listRoots();
for (File root: roots)
System.out.println(root);
}
}
编译&运行,输出:
Win 7
C:\
D:\
E:\
F:\
Linux
/
Obtaining Disk Space Information
一个 partition (分区)对于文件系统是系统特定的储存的一部分。获得分区空闲的空间大小很重要。在Java 6之前,唯一简便的方式来完成这个事情是通过创建不同大小的文件来猜。
Java 6添加了File类的 long getFreeSpace(), long getTotalSpace()和 long getUsableSpace() 方法,返回File分区空间信息,由File实例的abstract path描述:
- long getFreeSpace() 返回File对象abstract path鉴定的分区的未分配字节数。
- long getTotalSpace() 返回File对象abstract path鉴定的分区的size;当abstract path没有命名分区返回0。
- long getUsableSpace() 返回File对象abstract path鉴定的分区对当前JVM可用的字节数;当abstract path没有命名分区返回0。
虽然 getFreeSpace() 和 getUsableSpace() 似乎相等,他们在以下方面不同:不像getFreeSpace(), getUsableSpace() 检查写权限和其他的操作系统限制,得出一个更准确的估计。
注意: getFreeSpace() and getUsableSpace() 方法返回一个Java应用可以使用可用或未分配空间的提示(不是保证)。因为JVM外面的程序也能用分区空间,导致实际未分配或可用空间比返回值要小。
Listing 2-4. Outputting the Free, Usable, and Total Space on All Partitions
import java.io.File;
public class PartitionSpace
{
public static void main(String[] args)
{
File[] roots = File.listRoots();
for (File root: roots)
{
System.out.println("Partition: " + root);
System.out.println("Free space on this partition = " +
root.getFreeSpace());
System.out.println("Usable space on this partition = " +
root.getUsableSpace());
System.out.println("Total space on this partition = " +
root.getTotalSpace());
System.out.println("***");
}
}
}
编译运行,输出(Win 7):
Partition: C:\
Free space on this partition = 143271129088
Usable space on this partition = 143271129088
Total space on this partition = 499808989184
***
Partition: D:\
Free space on this partition = 0
Usable space on this partition = 0
Total space on this partition = 0
***
Partition: E:\
Free space on this partition = 733418569728
Usable space on this partition = 733418569728
Total space on this partition = 1000169533440
***
Partition: F:\
Free space on this partition = 33728192512
Usable space on this partition = 33728192512
Total space on this partition = 64021835776
***
Listing Directories
File声明了5个方法返回位于文件夹里的file和文件夹。
Table 2-3. File Methods for Obtaining Directory Content
| Method | Description |
|---|---|
| String[] list() | 路径不表示目录或者发生I/O错误,返回null。否则返回strings数组 |
| String[]list(FilenameFilter filter) | 只返回符合filter的Strings |
| File[] listFiles() | 把Strings数组转换为Files数组返回 |
| File[] listFiles(FileFilter filter) | 返回符合filter的File数组 |
| File[] listFiles(FilenameFilter filter) | 返回符合filter的File数组 |
FilenameFilter接口声明一个 boolean accept(File dir, String name) 方法。dir是path的parent部分(文件夹path),name是最后的文件夹的name或者这个path最后的文件名。
accept()使用参数决定是否符合规则,返回true就会在数组里包含。
Listing 2-5. Listing Specific Names
import java.io.File;
import java.io.FilenameFilter;
public class Dir
{
public static void main(final String[] args)
{
if (args.length != 2)
{
System.err.println("usage: java Dir dirpath ext");
return;
}
File file = new File(args[0]);
FilenameFilter fnf = new FilenameFilter()
{
@Override
public boolean accept(File dir, String name)
{
return name.endsWith(args[1]);
}
};
String[] names = file.list(fnf);
for (String name: names)
System.out.println(name);
}
}
编译运行:java Dir C:\windows exe 输出:
bfsvc.exe
explorer.exe
fveupdate.exe
HelpPane.exe
hh.exe
IsUninst.exe
kindlegen.exe
notepad.exe
regedit.exe
splwow64.exe
twunk_16.exe
twunk_32.exe
winhlp32.exe
write.exe
listFiles(FileFilter) 引入不对称。
java.io.FileFilter 声明一个accept(String path)方法,参数是完整的path。
注意:如果想有目录和文件夹分隔的path,用 FilenameFilter ;要使用完整的路径,用getParent() and getName() 。
Creating/Modifying Files and Directories
File也提供了创建文件,文件夹,和修改存在的文件文件夹。
Table 2-4. File Methods for Creating New and Manipulating Existing Files and Directories
| Method | Description |
|---|---|
| boolean mkdir() | 创建文件夹;成功返回true。 |
| boolean mkdirs() | 层级创建。成功返回true。 |
| boolean renameTo(File dest) | dest是null抛出空指针异常。成功为true。方法行为很多取决于操作系统。例如, rename 方法可能不能够把文件从一个文件系统移到另一个,可能不是原子操作,目标存在时,可能不成功。返回值一定要检查,看是否成功。 |
| boolean setLastModified(long time) | 设置上次修改的时间。成功为true。time是负数抛出 IllegalArgumentException 。时间可能会被 truncated。 |
假设你想写一个,可以有临时文件去保存快照的程序。使用createTempFile()创建临时文件。如果你没有指定储存路径,会保存到系统属性 java.io.tmpdir 。你可能想移除临时文件,deleteOnExit() 方法,在JVM没有崩溃或断电退出时删除临时文件。
Listing 2-6. Experimenting with Temporary Files
import java.io.File;
import java.io.IOException;
public class TempFileDemo
{
public static void main(String[] args) throws IOException
{
System.out.println(System.getProperty("java.io.tmpdir"));
File temp = File.createTempFile("text", ".txt");
System.out.println(temp);
temp.deleteOnExit();
}
}
Setting and Getting Permissions
Java 1.2添加 boolean setReadOnly() 方法到File,标记一个文件或文件夹为只读。然而恢复可写状态的方法没有。更重要的是,在Java 6之前, File没有办法管理抽象路径的读、写和执行权限。
Java 6添加之下方法:
- boolean setExecutable(boolean executable, boolean ownerOnly) false为全部用户
- boolean setExecutable(boolean executable) 设置拥有者的执行权限
- boolean setReadable(boolean readable, boolean ownerOnly)
- boolean setReadable(boolean readable)
- boolean setWritable(boolean writable, boolean ownerOnly)
- boolean setWritable(boolean writable)
除了这些方法,Java 6改造了 boolean canRead() 和boolean canWrite() 方法,引入 boolean canExecute() 方法返回xxx权限。
Listing 2-7. Checking a File’s or Directory’s Permissions
import java.io.File;
public class Permissions
{
public static void main(String[] args)
{
if (args.length != 1)
{
System.err.println("usage: java Permissions filespec");
return;
}
File file = new File(args[0]);
System.out.println("Checking permissions for " + args[0]);
System.out.println(" Execute = " + file.canExecute());
System.out.println(" Read = " + file.canRead());
System.out.println(" Write = " + file.canWrite());
}
}
Exploring Miscellaneous Capabilities
最后,File实现java.lang.Comparable 接口的 compareTo()方法,重写了 equals() 和 hashCode() 。
Table 2-5. File’s Miscellaneous Methods
| Method | Description |
|---|---|
| int compareTo(File path) | 字典比较两个path。方法的排序定义取决于操作系统。对 Unix/Linux,字母排序是有意义的。windows无意义。抽象路径相同返回0。调用 getCanonicalFile() 再比较。 |
| boolean equals(Object obj)) | 取决于操作系统。path一样。 |
| int hashCode() | 返回path 的哈希。计算取决于底层操作系统。在 Unix/Linux 等于path 字符串的哈希值异或 1234321。windows,是小写的path字符串。小写path不考虑 current locale 。 |
Listing 2-8. Comparing Files
import java.io.File;
import java.io.IOException;
public class Compare
{
public static void main(String[] args) throws IOException
{
if (args.length != 2)
{
System.err.println("usage: java Compare filespec1 filespec2");
return;
}
File file1 = new File(args[0]);
File file2 = new File(args[1]);
System.out.println(file1.compareTo(file2));
System.out.println(file1.getCanonicalFile()
.compareTo(file2.getCanonicalFile()));
}
}
exercise
1. What is the purpose of the File class?
2. What do instances of the File class contain?
3. What is a path?
4. What is the difference between an absolute path and a relative path?
5. How do you obtain the current user (also known as working) directory?
6. Define parent path.
7. File’s constructors normalize their path arguments. What does
normalize mean?
8. How do you obtain the default name-separator character?
9. What is a canonical path?
10. What is the difference between File’s getParent() and
getName() methods?
11. True or false: File’s exists() method only determines whether or
not a file exists.
12. What is a normal file?
13. What does File’s lastModified() method return?
14. What does File’s listRoots() method accomplish?
15. True or false: File’s list() method returns an array of Strings
where each entry is a file name rather than a complete path.
16. What is the difference between the FilenameFilter and
FileFilter interfaces?
17. True or false: File’s createNewFile() method doesn’t check for
file existence and create the file when it doesn’t exist in a single
operation that’s atomic with respect to all other file system activities
that might affect the file.
18. File’s createTempFile(String, String) method creates a
temporary file in the default temporary directory. How can you locate
this directory?
19. Temporary files should be removed when no longer needed after an
application exits (to avoid cluttering the file system). How do you
ensure that a temporary file is removed when the JVM ends normally
(it doesn’t crash and the power isn’t lost)?
20. Which one of the boolean canRead(), boolean canWrite(), and
boolean canExecute() methods was introduced by Java 6?
21. How would you accurately compare two File objects?
22. Create a Java application named Touch for setting a file’s or
directory’s timestamp to the current time. This application has the
following usage syntax: java Touch pathname.
Summary
Chapter 3 RandomAccessFile
File可以被创建和/或打开用于random access ,在文件关闭前,在多个位置可以发生混合读写操作。Java提供 java.io.RandomAccessFile 类支持这种随机访问。
Exploring RandomAccessFile
构造器:
- RandomAccessFile(File file, String mode) :创建和打开一个不存在的文件或打开存在的文件。由abstract path确定,根据mode创建和/或打开文件。
- RandomAccessFile(String path, String mode):创建和打开一个不存在的文件或打开存在的文件。由path确定,根据mode创建和/或打开文件。
constructor’s mode参数必须是 r,rw,rws,rwd其中之一,否则抛出java.lang. IllegalArgumentException ,参数意义如下:
r,通知构造器打开一个存在的文件只用于读。任何写的尝试抛出java.io.IOException。rw,如果不存在,通知构造器创建并打开一个新的file的时候用于读写或者打开一个存在的文件用于读写。rwd,如果不存在,通知构造器创建并打开一个新的file的时候用于读写或者打开一个存在的文件用于读写。另外,每个对于文件内容的更新必须同步写入底层储存设备。rws如果不存在,通知构造器创建并打开一个新的file的时候用于读写或者打开一个存在的文件用于读写。另外,每个对于文件内容或者 metadata的更新必须同步写入底层储存设备。
注意:文件的metadata是关于文件的但不是实际文件内容。metadata例如有:file的length,上次更改的时间。
rws和rwd同步写入,保证了关键数据在操作系统崩溃不会丢失。当文件不在本地设备上时是不能保证的。
注意:rws和rwd打开的文件要比rw模式打开的文件慢。
当r模式path打不开的时候(不存在或是文件夹),rw模式的path是只读权限的时候或者是文件夹,抛出 java.io.FileNotFoundException 。
RandomAccessFile raf = new RandomAccessFile("employee.dat", "r");
一个 random access file和一个file指针关联,一个游标指示下个要读/写的字节的位置。当一个存在文件被打开,file指针被设置为第一个字节,在offset 0 。当文件被创建时,file指针也被设为0。
读写操作在文件pointer开始,并把他推进已经读或写过的字节数。写超出了文件当前末尾的操作会导致文件被扩展。操作会继续直到File关闭。
RandomAccessFile的代表方法:
Table 3-1. RandomAccessFile Methods
| Method | Description |
|---|---|
| int readInt() | 从文件读返回 32-bit integer。从当前file指针开始读取4个字节。 如果字节读取依次是b1 b2 b3和b4 ,0 <= b1, b2, b3, b4 <= 255 ,结果等于 (b1 << 24) | (b2 << 16) | (b3 << 8) | b4. 这个方法在4个字节读完、检测到文件末尾、或抛出异常之前会阻塞。在读4个字节前到达文件末尾抛出 EOFException ,I/O错误抛出 IOException 。 |
| void seek(long pos) | 设置文件指针的当前offset(从文件开头开始用字节测量)。如果 offset 设置超出了文件尾,file的length不会变。只有通过写才行。pos是负值或者I/O错误抛出 IOException 。 |
| void setLength(long newLength) | 设置文件length。如果 length() 返回的比newLength大,file被 truncated。在这种情况下,如果 getFilePointer() 返回的offset比newLength大,在 setLength() 返回后,offset会等于 newLength。如果当前长度比newLength小,文件被扩展。这种情况下,扩展部分的文件内容没有被定义。I/O错误抛出 IOException 。 |
| int skipBytes(int n) | 尝试跳过n个字节。 This method skips over a smaller number of bytes (possibly zero) when the end of file is reached before n bytes have been skipped。在这种情况不抛出 EOFException 。n是负数,不跳。返回实际的跳跃数。I/O错误抛出 IOException 。 |
| void write(byte[] b) | 从当前文件指针开始写 byte array b 的 b.length bytes。I/O错误抛出 IOException 。 |
| void write(int b) | 写一个更低的8 bits的 b作为一个32 bits的integer到文件从当前文件指针开始。I/O错误抛出 IOException 。 |
| void writeChars(String s) | 写 s 作为 characters 的序列到文件从当前文件指针开始。I/O错误抛出 IOException |
| void writeInt(int i) | 写32 bits的integer到file从当前文件指针开始。 这四个字节是先用高字节写的。I/O错误抛出 IOException |
上面方法是不言而喻的。然而,getFD() 方法需要进一步启示。
注意:RandomAccessFile 的read开头的方法和skipBytes() 起源于 java.io.DataInput 接口,RandomAccessFile实现了它。另外,writer开头的方法源于java.io.DataOutput 接口,也实现了这个接口。
当文件被打开,底层操作系统创建一个基于操作系统的结构来代表文件。对这个结构的handle保存在java.io.FileDescriptor 类的一个实例, getFD()返回这个实例。
注意:一个handle是一个Java传递给底层操作系统来识别的标识符,在这种情况,是一个特定的打开的文件,当需要底层操作系统执行文件操作时候。
FileDescriptor 是一个小的类,声明了3个FileDescriptor 常量叫做in,out,error。这三个常量使System.in, System. out, and System.err 提供到标准输入输出错误流的访问。
FileDescriptor 也声明以下2个方法:
- void sync() 告诉底层操作系统去flush(empty)打开文件输出buffers的内容到关联的本地磁盘设备。
sync()返回所有修改了的数据和属性。当buffers不能被flushed或者因为操作系统不能保证所有buffers和物理媒介同步时, 抛出java. io.SyncFailedException。 - boolean valid() 决定file descriptor object是不是有效的。当 file descriptor object对象表示打开的文件或活动的I/O连接返回true;否则返回false。
写入到打开文件的数据被保存在底层操作系统的输出buffers。当buffers充满到了capacity(容量),操作系统清空它们到磁盘。buffers改善了性能因为磁盘访问比内存慢。
然而,当你写数据到rwd或rws模式打开的 random access file,每个写操作的数据都是直接写到磁盘。结果是,写操作比rw模式要慢。
假设一个场景,要结合通过output buffers写数据和直接写数据到磁盘。下面的例子落地了这个混合场景,用rw模式打开,选择性调用 FileDescriptor的sync() 方法。
RandomAccessFile raf = new RandomAccessFile("employee.dat", "rw");
FileDescriptor fd = raf.getFD();
// Perform a critical write operation.
raf.write(...);
// Synchronize with the underlying disk by flushing the operating system
// output buffers to the disk.
fd.sync();
// Perform a non-critical write operation where synchronization isn't
// necessary.
raf.write(...);
// Do other work.
// Close the file, emptying output buffers to the disk.
raf.close();
Using RandomAccessFile
RandomAccessFile 对建一个flat file database 很有用,一个单个文件被组织成records and fields。一个record保存单个entry(就像一个parts database的part),一个field保存entry的单个属性(就像a part number)。
注意:term field也用于引用类中声明的变量 。为了避免和重载术语混淆,把一个field变量想象成类似于一个record field属性。
flat file database 典型地组织内容为固定长度的records序列。每个record被进一步组织成一个或多个固定长度的records。
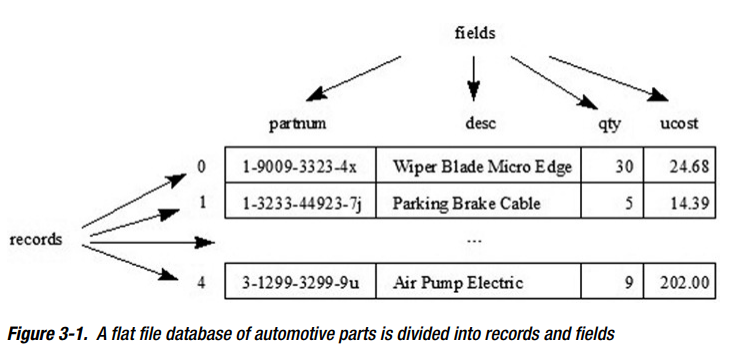
演示用RandomAccessFile 实现一个 flat file database:
Listing 3-1. Implementing the Parts Flat File Database
import java.io.IOException;
import java.io.RandomAccessFile;
public class PartsDB {
public final static int PNUMLEN = 20;
public final static int DESCLEN = 30;
public final static int QUANLEN = 4;
public final static int COSTLEN = 4;
private final static int RECLEN = 2 * PNUMLEN + 2 * DESCLEN + QUANLEN +
COSTLEN;
private RandomAccessFile raf;
public PartsDB(String path) throws IOException {
raf = new RandomAccessFile(path, "rw");
}
public void append(String partnum, String partdesc, int qty, int ucost)
throws IOException {
raf.seek(raf.length());
write(partnum, partdesc, qty, ucost);
}
public void close() {
try {
raf.close();
} catch (IOException ioe) {
System.err.println(ioe);
}
}
public int numRecs() throws IOException {
return (int) raf.length() / RECLEN;
}
public Part select(int recno) throws IOException {
if (recno < 0 || recno >= numRecs())
throw new IllegalArgumentException(recno + " out of range");
raf.seek(recno * RECLEN);
return read();
}
public void update(int recno, String partnum, String partdesc, int qty,
int ucost) throws IOException {
if (recno < 0 || recno >= numRecs())
throw new IllegalArgumentException(recno + " out of range");
raf.seek(recno * RECLEN);
write(partnum, partdesc, qty, ucost);
}
private Part read() throws IOException {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < PNUMLEN; i++)
sb.append(raf.readChar());
String partnum = sb.toString().trim();
sb.setLength(0);
for (int i = 0; i < DESCLEN; i++)
sb.append(raf.readChar());
String partdesc = sb.toString().trim();
int qty = raf.readInt();
int ucost = raf.readInt();
return new Part(partnum, partdesc, qty, ucost);
}
private void write(String partnum, String partdesc, int qty, int ucost)
throws IOException {
StringBuffer sb = new StringBuffer(partnum);
if (sb.length() > PNUMLEN)
sb.setLength(PNUMLEN);
else if (sb.length() < PNUMLEN) {
int len = PNUMLEN - sb.length();
for (int i = 0; i < len; i++)
sb.append(" ");
}
raf.writeChars(sb.toString());
sb = new StringBuffer(partdesc);
if (sb.length() > DESCLEN)
sb.setLength(DESCLEN);
else if (sb.length() < DESCLEN) {
int len = DESCLEN - sb.length();
for (int i = 0; i < len; i++)
sb.append(" ");
}
raf.writeChars(sb.toString());
raf.writeInt(qty);
raf.writeInt(ucost);
}
public static class Part {
private String partnum;
private String desc;
private int qty;
private int ucost;
public Part(String partnum, String desc, int qty, int ucost) {
this.partnum = partnum;
this.desc = desc;
this.qty = qty;
this.ucost = ucost;
}
String getDesc() {
return desc;
}
String getPartnum() {
return partnum;
}
int getQty() {
return qty;
}
int getUnitCost() {
return ucost;
}
}
}
PartsDB 先声明了常量确定string和32-bits integer field的length。然后声明常量用字节计算的record length。计算考虑到了字符在文件中占两个字节。
然后是field raf ,是RandomAccessFile 类型。这个field在随后的构造函数被分配为一个RandomAccessFile 类实例,他会创建/打开一个新的文件或者打开一个存在文件,因为是rwmode。
PartsDB 然后声明append(), close(), numRecs(), select(), and update() 。这个方法添加一个record到file,关闭file,返回file的record数,选择和返回一个特定的record,更新一个特定的record:
- append() 方法先调用
length() and seek()。确保在调用privatewrite()方法把record写入前,文件指针在文件末尾。 RandomAccessFile’s close()方法可以抛出IOException。因为异常很少见,选择在close()方法里处理掉异常,让方法签名简单。然而,错误发生会打印异常信息。numRecs()方法返回records数。这些记录从0编号到numRecs() -1。select()和update()方法的recno参数都在这个范围。select()方法调用privateread()返回recno决定的record实例(Part)。update()方法同样简单。和select()一样,把file指针定位到recno决定的record。和append()一样,调用write()写入参数替换record而不是添加。
使用 private write() 写入records。因为fields必须有精确的size,write()拉长比一个field size短的基于String的值,在右边加空格。必要时将这些值裁剪成field大小 。
使用private read() 读record。 read() 在给Part赋值时移除基于String值填充。
就其本身而言,PartsDB是无用的。做个实验体验一下:
Listing 3-2. Experimenting with the Parts Flat File Database
import java.io.IOException;
public class UsePartsDB {
public static void main(String[] args) {
PartsDB pdb = null;
try {
pdb = new PartsDB("parts.db");
if (pdb.numRecs() == 0) {
// Populate the database with records.
pdb.append("1-9009-3323-4x", "Wiper Blade Micro Edge", 30,
2468);
pdb.append("1-3233-44923-7j", "Parking Brake Cable", 5, 1439);
pdb.append("2-3399-6693-2m", "Halogen Bulb H4 55/60W", 22, 813);
pdb.append("2-599-2029-6k", "Turbo Oil Line O-Ring ", 26, 155);
pdb.append("3-1299-3299-9u", "Air Pump Electric", 9, 20200);
}
dumpRecords(pdb);
pdb.update(1, "1-3233-44923-7j", "Parking Brake Cable", 5, 1995);
dumpRecords(pdb);
} catch (IOException ioe) {
System.err.println(ioe);
} finally {
if (pdb != null)
pdb.close();
}
}
static void dumpRecords(PartsDB pdb) throws IOException {
for (int i = 0; i < pdb.numRecs(); i++) {
PartsDB.Part part = pdb.select(i);
System.out.print(format(part.getPartnum(), PartsDB.PNUMLEN, true));
System.out.print(" | ");
System.out.print(format(part.getDesc(), PartsDB.DESCLEN, true));
System.out.print(" | ");
System.out.print(format("" + part.getQty(), 10, false));
System.out.print(" | ");
String s = part.getUnitCost() / 100 + "." + part.getUnitCost() %
100;
if (s.charAt(s.length() - 2) == '.') s += "0";
System.out.println(format(s, 10, false));
}
System.out.println("Number of records = " + pdb.numRecs());
System.out.println();
}
static String format(String value, int maxWidth, boolean leftAlign) {
StringBuffer sb = new StringBuffer();
int len = value.length();
if (len > maxWidth) {
len = maxWidth;
value = value.substring(0, len);
}
if (leftAlign) {
sb.append(value);
for (int i = 0; i < maxWidth - len; i++)
sb.append(" ");
} else {
for (int i = 0; i < maxWidth - len; i++)
sb.append(" ");
sb.append(value);
}
return sb.toString();
}
}
main()方法先实例化PartsDB,使用 parts.db 作为database file的name。当没记录, numRecs() 返回0。然后通过append() 添加了几个record。
main() 方法然后dump这5个记录到标准输出流,更新 number是1的record的unit cost,再次将这些记录dump到标准输出流中以显示,然后关闭。
注意:使用基于integer的美分数量存储cost值。如果要用java.math.BigDecimal 对象来保存货币值,必须重构PartsDB以利用对象序列化的优势,还没做这个(discuss object serialization in Chapter 4 )。
main()依赖dumpRecords() helper方法来dump records,dumpRecords()依赖format()helper方法format field的值,因此能在正确对齐的列中显示。我可以用java.util.Formatter 代替 (see Chapter 11 )。
编译运行,输出:
1-9009-3323-4x | Wiper Blade Micro Edge | 30 | 24.68
1-3233-44923-7j | Parking Brake Cable | 5 | 19.95
2-3399-6693-2m | Halogen Bulb H4 55/60W | 22 | 8.13
2-599-2029-6k | Turbo Oil Line O-Ring | 26 | 1.55
3-1299-3299-9u | Air Pump Electric | 9 | 202.00
Number of records = 5
1-9009-3323-4x | Wiper Blade Micro Edge | 30 | 24.68
1-3233-44923-7j | Parking Brake Cable | 5 | 19.95
2-3399-6693-2m | Halogen Bulb H4 55/60W | 22 | 8.13
2-599-2029-6k | Turbo Oil Line O-Ring | 26 | 1.55
3-1299-3299-9u | Air Pump Electric | 9 | 202.00
Number of records = 5
Note :Check out Wikipedia’s “Flat file database” entry (https://en.wikipedia.org/wiki/Flat_file_database) to learn more about flat file databases.
exercise
The following exercises are designed to test your understanding of Chapter 3’s content:
1. What is the purpose of the RandomAccessFile class?
2. What is a file’s metadata?
3. What is the purpose of the "rwd" and "rws" mode arguments?
4. What is a file pointer?
5. What happens when you write past the end of the file?
6. True or false: When you call RandomAccessFile’s seek(long)
method to set the file pointer’s value, and when this value is greater
than the length of the file, the file’s length changes.
7. What does method void write(int b) accomplish?
8. What does FileDescriptor’s sync() method accomplish?
9. Define flat file database.
10. Write a small Java application named RAFDemo that opens file data in
read/write mode, uses void write(int b) to write byte value 127
followed by void writeChars(String s) to write string "Test"
(minus the quotes) to this file, resets the file pointer to the start of the
file, and read/outputs these values.
Summary
Chapter 4 Streams
连同java.io.File and java.io.RandomAccessFile,Java’s classic I/O也提供了 streams用于文件操作。stream是一个有顺序的任意长度的字节的序列。 字节从应用到目的地流过输出流,从源到应用流过输入流。
Stream Classes Overview
output stream类结构层次图:
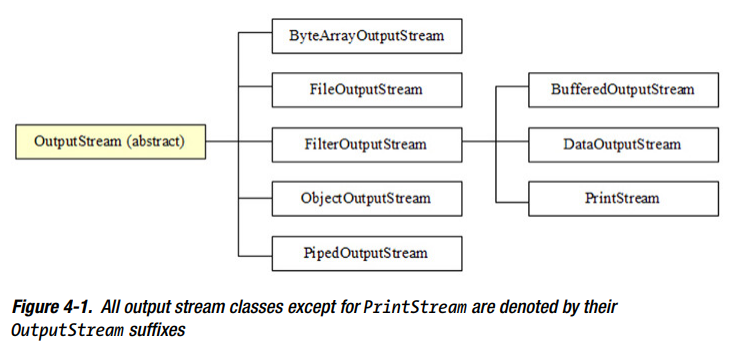
input stream类结构层次图:
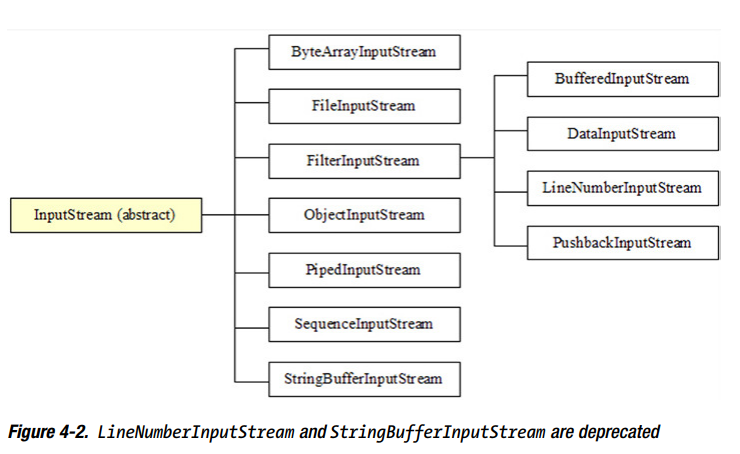
LineNumberInputStream and StringBufferInputStream 已被弃用,因为不支持不同的字符编码, 在Chapter 5 讨论代替它们的java.io.LineNumberReader and java.io.StringReader 。
注意:PrintStream是另一个因为不支持不同编码而应该被弃用的类;java.io.PrintWriter 是替代。然而,Oracle弃用这个类是存疑的,因为PrintStream 是java.lang.System class’s out and err class fields 类型,而且太多的遗留代码依赖于它。
其他Java包提供另外的 output stream and input stream类。例如, java.util.zip 提供4个输出流类将未压缩的数据压缩成各种格式,以及4个对应的输入流从相同的数据格式中解压压缩数据。
- CheckedOutputStream
- CheckedInputStream
- DeflaterOutputStream
- GZIPOutputStream
- GZIPInputStream
- InflaterInputStream
- ZipOutputStream
- ZipInputStream
同时,java.util.jar 提供一对流类用于写内容到JAR文件和读取JAR文件的内容:
- JarOutputStream
- JarInputStream
Touring the Stream Classes
下面开始 java.io’s output stream and input stream classes 的tour,从OutputStream and InputStream 开始。
OutputStream and InputStream
Java提供抽象的 OutputStream and InputStream 类描述I/O流。OutputStream 是所有output stream的超类。
Table 4-1. OutputStream Methods
| Method | Description |
|---|---|
| void close() | 关流和释放任何和流有关的操作系统资源。I/O错误发生抛出 java.io.IOException 。 |
| void flush() | 把任何缓冲的输出字节写到目的地来刷新输出流。如果输出流的目的地是底层操作系统提供的一个抽象(例如file),刷新这个流只保证先前写入流的字节被传递给底层操作系统用于write;不保证确实被写入物理设备比如一个磁盘驱动器。I/O错误发生抛出 java.io.IOException 。 |
| void write(byte[] b) | 从字节数组b写b个length字节到输入流。通常 write(b) 表现得像你指定了 write(b, 0, b.length)。b是null抛出 java.lang .NullPointerException ,I/O错误发生抛出 java.io.IOException |
| void write(byte[] b, int off, int len) | 从byte数组b的off offset开始,写len个字节到输入流。b是null抛出 java.lang .NullPointerException , IndexOutOfBoundsException 当off是负,len是负,或者off + bean>b.length;I/O错误发生抛出 java.io.IOException |
| void write(int b) | 写字节b到输入流。只有8个 ow-order bits被写;24个 high-order bits 被忽略。I/O错误发生抛出 java.io.IOException |
flush() 在长期运行的应用需要经常保持更改的时候很有用。记住flush() 只刷新字节到操作系统;不一定导致操作系统刷新字节到磁盘。
注意: close() 自动刷新输出流,如果应用在close被调用前结束,输入流自动关系,数据被刷新。
InputStream 是所有输入流的超类。
Table 4-2. InputStream Methods
| Method | Description |
|---|---|
| int available() | 返回从输入流读取的字节数量的估计,通过 read() 方法(或 skipped over via skip() )调用而不阻塞调用线程。I/O错误发生抛出 java.io.IOException 。用它的返回值来分配一个缓冲区来存放所有流的数据是不正确的,因为子类的实现可能不会返回流的总大小。 |
| void close() | 关闭输入流并释放任何和流有关的操作系统资源。I/O错误发生抛出 java.io.IOException 。 |
| void mark(int readlimit) | 在输入流中标记当前位置。随后调用 reset() ,定位流到最后一次标记的位置,然后随后的读操作读取相同的字节。 readlimit 参数告诉输入流在失效标记前,允许读取多少字节(因此这个流不能被重置到标记的位置 )。 |
| boolean markSupported() | 当这个输入流支持 mark() and reset() 返回true;否则,返回false。 |
| int read() | 读取返回(作为0-255的一个int值)输入流的下一个字节,到达流终点返回-1;这个方法会阻塞,直到input可用,流end被检测,或抛出异常。I/O错误发生抛出 java.io.IOException 。 |
| int read(byte[] b) | 从这个输入流读一定数目的字节,把他们存到字节数组b。返回实际读取的字节数(可能比b的length小但是永远不会超过),或者返回-1当到达流end(无字节可读)。这个方法会阻塞,直到input可用,流end被检测,或抛出异常。b是null抛出空指针,I/O错误发生抛出 java.io.IOException 。 |
| int read(byte[] b, int off, int len) | 从输入流读不超过len个字节,存在array b,从off开始。返回实际读取的字节数(可能比b的length小但是永远不会超过),或者返回-1当到达流end(无字节可读)。这个方法会阻塞,直到input可用,流end被检测,或抛出异常。。b是null抛出空指针;off是负,len是负,len比b.length-off大抛出 IndexOutOfBoundsException I/O错误发生抛出 java.io.IOException 。 |
| void reset() | 重定位输入流到最后一次 mark()的位置。输入流没被标记或标记失效抛出IOException 。 |
| long skip(long n) | 跳过并丢弃n字节的数据。这个方法可能跳过的数量会小一点(可0),例如,file end。返回实际的跳过数。n是负,不跳过。输入流不支持skip或者I/O错误抛出 IOException |
子类例如ByteArrayInputStream支持mark()标记当前位置,然后reset返回。
注意:不要忘了调用markSupported() 来看是不是支持mark() and reset()。
ByteArrayOutputStream and ByteArrayInputStream
字节数组在作为流目的地和源时很有用。ByteArrayOutputStream 类让你写一个字节流到字节数组;ByteArrayInputStream 让你从字节数组读取字节流。
ByteArrayOutputStream 声明2个构造器。每个构造器使用内部的字节数组创建 byte array output stream;这个array的copy可以通过调用 byte[] toByteArray() 返回:
- ByteArrayOutputStream() 使用内部的字节数组初始容量是32字节 创建一个byte array output stream。这个数组必要时增长。
- ByteArrayOutputStream(int size) 使用指定的长度创建byte array output stream。 <0抛出
java.lang.IllegalArgumentException。
下面的例子用ByteArrayOutputStream() 创建一个byte array output stream,使用默认size。
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ByteArrayInputStream 也有两个构造器。每个构造器基于指定字节数组创建a byte array input stream
- ByteArrayInputStream(byte[] ba) 使用ba数组创建(直接使用;不创建copy)。position为0,要读的字节数为ba.length。
- ByteArrayInputStream(byte[] ba, int offset, int count) position是offset,读取count个字节。
例子,
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
这两个流在你需要转换图片为字节数组,用某种方法处理字节,然后转换字节成图片。
一个例子:
String path = ... ; // Assume a legitimate path to an image.
Bitmap bm = BitmapFactory.decodeFile(path);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
if (bm.compress(Bitmap.CompressFormat.PNG, 100, baos))
{
byte[] imageBytes = baos.toByteArray();
// Do something with imageBytes.
bm = BitMapFactory.decodeStream(new ByteArrayInputStream(imageBytes));
}
FileOutputStream and FileInputStream
文件是常见的流目的地和源。
下面用FileOutputStream(String path)创建文件输出流。
FileOutputStream fos = new FileOutputStream("employee.dat");
Tip:FileOutputStream(String name) 重新存在的文件。要添加数据而不是覆盖存在的内容,调用带有 boolean append 的构造器,设置参数为true。
下面创建一个 FileInputStream(String name) 的文件输入流,employee.dat为source。
FileInputStream fis = new FileInputStream("employee.dat");
FileOutputStream and FileInputStream 在文件复制有用。
Listing 4-1. Copying a Source File to a Destination File
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Copy {
public static void main(String[] args) {
if (args.length != 2) {
System.err.println("usage: java Copy srcfile dstfile");
return;
}
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(args[0]);
fos = new FileOutputStream(args[1]);
int b; // I chose b instead of byte because byte is a reserved
// word.
while ((b = fis.read()) != -1)
fos.write(b);
} catch (FileNotFoundException fnfe) {
System.err.println(args[0] + " could not be opened for input, or "
+ args[1] + " could not be created for output");
} catch (IOException ioe) {
System.err.println("I/O error: " + ioe.getMessage());
} finally {
if (fis != null)
try {
fis.close();
} catch (IOException ioe) {
assert false; // shouldn't happen in this context
}
if (fos != null)
try {
fos.close();
} catch (IOException ioe) {
assert false; // shouldn't happen in this context
}
}
}
}
使用try-resource
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Copy1 {
public static void main(String[] args) {
if (args.length != 2) {
System.err.println("usage: java Copy srcfile dstfile");
return;
}
try (FileInputStream fis = new FileInputStream(args[0]);
FileOutputStream fos = new FileOutputStream(args[1])) {
int b; // I chose b instead of byte because byte is a reserved
// word.
while ((b = fis.read()) != -1)
fos.write(b);
} catch (FileNotFoundException fnfe) {
System.err.println(args[0] + " could not be opened for input, or "
+ args[1] + " could not be created for output");
} catch (IOException ioe) {
System.err.println("I/O error: " + ioe.getMessage());
}
}
}
PipedOutputStream and PipedInputStream
线程必须经常交流。一种方法是引入共享变量。另一种是通过PipedOutputStream and PipedInputStream 类使用piped streams(管道流)。PipedOutputStream 类让一个sending线程写一个字节流到一个PipedInputStream 类的实例,然后一个receiving线程读取这些字节。
警告:尝试使用来自一个single thread的 aPipedOutputStream object and a PipedInputStream object 是不推荐的,可能会死锁。
PipedOutputStream 声明2个构造器:
- PipedOutputStream() 创建一个 piped output stream ,还没有连接到 a piped input stream 。在使用前,它必须被连接到一个 piped input stream ,无论使用receiver or the sender 。
- PipedOutputStream(PipedInputStream dest) 创建piped output stream 连接到piped input stream dest 。写到piped output stream的字节可以从dest读出来。I/O错误抛出
IOException。
connect(PipedInputStream dest)方法,用于连接。
PipedInputStream 2个构造器:
- PipedInputStream() 用前必须连接。
- PipedInputStream(int pipeSize) 使用pipeSize指定管道大小。用前必须连接。
- PipedInputStream(PipedOutputStream src)
- PipedInputStream(PipedOutputStream src, int pipeSize)
connect(PipedOutputStream src) 方法用于连接。
创建一对管道流的最简单的方法是在同一个线程中任意顺序。例如:
PipedOutputStream pos = new PipedOutputStream();
PipedInputStream pis = new PipedInputStream(pos);
或者:
PipedInputStream pis = new PipedInputStream();
PipedOutputStream pos = new PipedOutputStream(pis);
也可以:
PipedOutputStream pos = new PipedOutputStream();
PipedInputStream pis = new PipedInputStream();
// ...
pos.connect(pis);
实例:
Listing 4-3. Piping Randomly Generated Bytes from a Sender Thread to a Receiver Thread
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
public class PipedStreamsDemo {
final static int LIMIT = 10;
public static void main(String[] args) throws IOException {
final PipedOutputStream pos = new PipedOutputStream();
final PipedInputStream pis = new PipedInputStream(pos);
Runnable senderTask = () -> {
try {
for (int i = 0; i < LIMIT; i++)
pos.write((byte)
(Math.random() * 256));
} catch (IOException ioe) {
ioe.printStackTrace();
} finally {
try {
pos.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
};
Runnable receiverTask = () -> {
try {
int b;
while ((b = pis.read()) != -1)
System.out.println(b);
} catch (IOException ioe) {
ioe.printStackTrace();
} finally {
try {
pis.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
};
Thread sender = new Thread(senderTask);
Thread receiver = new Thread(receiverTask);
sender.start();
receiver.start();
}
}
FilterOutputStream and FilterInputStream
Byte array, file, and piped streams传递没有变动过的字节给目标。也支持 filter streams来buffer, compress/ uncompress, encrypt/decrypt, or otherwise manipulate a stream’s byte sequence (that is input to the filter) 。
一个filter output stream拿到传递给 write()方法的数据((the input stream ),过滤,写过滤过的数据到下面的output stream,可能是 another filter output stream or a destination output stream such as a file output stream。
Filter output streams用OutputStream 子类FilterOutputStream 创建,单个构造器FilterOutputStream(OutputStream out) 。示例:
Listing 4-4. Scrambling a Stream of Bytes
import java.io.FilterOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class ScrambledOutputStream extends FilterOutputStream {
private int[] map;
public ScrambledOutputStream(OutputStream out, int[] map) {
super(out);
if (map == null)
throw new NullPointerException("map is null");
if (map.length != 256)
throw new IllegalArgumentException("map.length != 256");
this.map = map;
}
@Override
public void write(int b) throws IOException {
out.write(map[b]);
}
}
4-5打乱文件字节:
Listing 4-5. Scrambling a File’s Bytes
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Random;
public class Scramble {
public static void main(String[] args) {
if (args.length != 2) {
System.err.println("usage: java Scramble srcpath destpath");
return;
}
FileInputStream fis = null;
ScrambledOutputStream sos = null;
try {
fis = new FileInputStream(args[0]);
FileOutputStream fos = new FileOutputStream(args[1]);
sos = new ScrambledOutputStream(fos, makeMap());
int b;
while ((b = fis.read()) != -1)
sos.write(b);
} catch (IOException ioe) {
ioe.printStackTrace();
} finally {
if (fis != null)
try {
fis.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
if (sos != null)
try {
sos.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
static int[] makeMap() {
int[] map = new int[256];
for (int i = 0; i < map.length; i++)
map[i] = i;
// Shuffle map.
Random r = new Random(0);
for (int i = 0; i < map.length; i++) {
int n = r.nextInt(map.length);
int temp = map[i];
map[i] = map[n];
map[n] = temp;
}
return map;
}
}
Filter input streams,示例:
Listing 4-6. Unscrambling a Stream of Bytes
使用ScrambledInputStream 解密:
Listing 4-7. Unscrambling a File’s Bytes
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Random;
public class Unscramble {
public static void main(String[] args) {
if (args.length != 2) {
System.err.println("usage: java Unscramble srcpath destpath");
return;
}
ScrambledInputStream sis = null;
FileOutputStream fos = null;
try {
FileInputStream fis = new FileInputStream(args[0]);
sis = new ScrambledInputStream(fis, makeMap());
fos = new FileOutputStream(args[1]);
int b;
while ((b = sis.read()) != -1)
fos.write(b);
} catch (IOException ioe) {
ioe.printStackTrace();
} finally {
if (sis != null)
try {
sis.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
if (fos != null)
try {
fos.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
static int[] makeMap() {
int[] map = new int[256];
for (int i = 0; i < map.length; i++)
map[i] = i;
// Shuffle map.
Random r = new Random(0);
for (int i = 0; i < map.length; i++) {
int n = r.nextInt(map.length);
int temp = map[i];
map[i] = map[n];
map[n] = temp;
}
int[] temp = new int[256];
for (int i = 0; i < temp.length; i++)
temp[map[i]] = i;
return temp;
}
}
BufferedOutputStream and BufferedInputStream
FileOutputStream和FileInputStream有一个性能问题。 每个 file output stream write() 方法调用和 file input stream read() 方法调用导致 a native method调用操作系统程式,这些native methods减缓了I/O。
BufferedOutputStream and BufferedInputStream filter stream类提高了性能,通过最小化底层的output stream write() 调用和 input stream read() 方法调用。使用BufferedOutputStream’s write() and BufferedInputStream’s read() 代替,将Java缓冲区考虑进去:
- 当write buffer满了,write() 调用底层的output stream write()方法来排空buffer。随后调用
BufferedOutputStream的write()方法将字节保存在这个缓冲区中,直到它再次满为止。 - 当 read buffer是空的, read() 调用底层的 input stream read() 方法来充满buffer。随后调用
BufferedInputStream’s read() 从该buffer返回字节直到它再次为空。
BufferedOutputStream以下构造器
- BufferedOutputStream(OutputStream out) 创建一个buffered output stream把输出流到out。一个内部的buffer被创建用来保存写出的字节。
- BufferedOutputStream(OutputStream out, int size) 指定了长度。
FileOutputStream fos = new FileOutputStream("employee.dat");
BufferedOutputStream bos = new BufferedOutputStream(fos); // Chain bos
// to fos.
bos.write(0); // Write to employee.dat through the buffer.
// Additional write() method calls.
bos.close(); // This method call internally calls fos's close() method.
BufferedInputStream 有两个构造器:
- BufferedInputStream(InputStream in)
- BufferedInputStream(InputStream in, int size)
FileInputStream fis = new FileInputStream("employee.dat");
BufferedInputStream bis = new BufferedInputStream(fis); // Chain bis to fis.
int ch = bis.read(); // Read employee.dat through the buffer.
// Additional read() method calls.
bis.close(); // This method call internally calls fis's close() method.
DataOutputStream and DataInputStream
FileOutputStream and FileInputStream 对读取字节和字节数组很有用。然而,不支持读写primitive-type的值(比如integer)和strings。
于是Java提供了 DataOutputStream and DataInputStream filter stream 类。克服了这个限制,提供方法读写primitive-type和strings,用依赖于操作系统的方式:
- Integer values是用 big-endian 形式读写。
- Floating-point and double precision floating-point 根据 IEEE 754 标准读写,每个floatingpoint value 4 字节,每个double precision floating-point value8字节。
- Strings根据修改的UTF-8 版本读写,一个可变长度编码标准有效保存2字节 Unicode characters 。
DataOutputStream 有一个构造器,DataOutputStream(OutputStream out) 。因为实现了java.io.DataOutput ,DataOutputStream 也提供了到 java.io.RandomAccessFile 提供的相同命名的写方法的访问。
DataInputStream 一个构造器,DataInputStream(InputStream in) 。因为实现了 java.io.DataInput ,DataInputStream 也提供 java.io.RandomAccessFile 的相同命名的读方法的访问。
例子:
Listing 4-8. Outputting and then Inputting a Stream of Multibyte Values
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class DataStreamsDemo {
final static String FILENAME = "values.dat";
public static void main(String[] args) {
try (FileOutputStream fos = new FileOutputStream(FILENAME);
DataOutputStream dos = new DataOutputStream(fos)) {
dos.writeInt(1995);
dos.writeUTF("Saving this String in modified UTF-8 format!");
dos.writeFloat(1.0F);
} catch (IOException ioe) {
System.err.println("I/O error: " + ioe.getMessage());
}
try (FileInputStream fis = new FileInputStream(FILENAME);
DataInputStream dis = new DataInputStream(fis)) {
System.out.println(dis.readInt());
System.out.println(dis.readUTF());
System.out.println(dis.readFloat());
} catch (IOException ioe) {
System.err.println("I/O error: " + ioe.getMessage());
}
}
}
警告:当读一个序列DataOutputStream的方法写入的值,确保使用相同的方法调用序列。否则得到错误的数据。
Object Serialization and Deserialization
Java提供DataOutputStream and DataInputStream classes 来流化 primitive-type values and String objects。但你不能stream非string对象。你必须用object serialization and deserialization 来stream任意类型对象。
对象serialization是一个JVM机制,序列化对象状态变成一个字节流。对应的 deserialization 是相反的。
注意:对象state由实例fields组成,保存了原始类型值和其他对象的引用。当一个对象序列化,是这个state一部分的对象也会实例化(除非你阻止)。另外,这些对象的部分是对象的话也一样实例化。
Java支持默认 serialization and deserialization,自定义 serialization and deserialization 和externalization 。
Default Serialization and Deserialization
默认的是最简单的方式但是提供很少的control。虽然Java代你做了大部分事情,但是你也要2个任务必须做。
第一个任务要被序列化的类要实现java.io.Serializable 接口,实现的原因是避免无限序列化。
注意:Serializable 是一个空的标记接口(没有方法来实现),告诉JVM序列化是okay的。当序列化机制遭遇没有实现这个接口的对象,抛出java.io.NotSerializableException (一个IOException的非直接子类)。
Unlimited serialization是序列化整个object graph的过程。不支持它的原因:
- Security:
- Performance: 序列化利用了反射API,会降低应用程序的性能。无限序列化可能会损害应用程序的性能。
- Objects not amenable to serialization:
下面一个例子:
Listing 4-9. Implementing Serializable
import java.io.Serializable;
public class Employee implements Serializable
{
private String name;
private int age;
public Employee(String name, int age)
{
this.name = name;
this.age = age;
}
public String getName() { return name; }
public int getAge() { return age; }
}
java.lang.String也实现了Serializable。
第二个任务是用ObjectOutputStream 类,和它的writeObject() 方法来序列化,ObjectInputStream 的readObject() 方法反序列化。
注意:虽然没继承 FilterOutputStream 和 FilterInputStream ,上面那2个序列化的类也表现如同filter streams 。
ObjectOutputStream序列化对象state,构造器 ObjectOutputStream(OutputStream out), 当传递output stream reference到out,构造器尝试写一个 serialization header 到输出流。out是null抛异常阻止写入header。
writeObject(Object obj) 方法尝试写关于对象类的信息,紧接着写对象实例field的值。不会序列化static field,和 transient 标注的field(忽略)。
注意:ObjectOutputStream implements DataOutput ,提供了写primitive-type values and strings到对象输出流的方法。
ObjectInputStream 类反序列化。ObjectInputStream(InputStream in) 构造器。当传递 input stream reference 到in,尝试从输入流读取serialization header ,抛出空指针 IO异常,如果header不对就抛出java.io.StreamCorruptedException 。
readObject() 方法反序列化对象。
注意:类似上一个。
例子:
Listing 4-10. Serializing and Deserializing an Employee Object
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class SerializationDemo {
final static String FILENAME = "employee.dat";
public static void main(String[] args) {
ObjectOutputStream oos = null;
ObjectInputStream ois = null;
try {
FileOutputStream fos = new FileOutputStream(FILENAME);
oos = new ObjectOutputStream(fos);
Employee emp = new Employee("John Doe", 36);
oos.writeObject(emp);
oos.close();
oos = null;
FileInputStream fis = new FileInputStream(FILENAME);
ois = new ObjectInputStream(fis);
emp = (Employee) ois.readObject(); // (Employee) cast is necessary.
ois.close();
System.out.println(emp.getName());
System.out.println(emp.getAge());
} catch (ClassNotFoundException cnfe) {
System.err.println(cnfe.getMessage());
} catch (IOException ioe) {
System.err.println(ioe.getMessage());
} finally {
if (oos != null)
try {
oos.close();
} catch (IOException ioe) {
assert false; // shouldn't happen in this context
}
if (ois != null)
try {
ois.close();
} catch (IOException ioe) {
assert false; // shouldn't happen in this context
}
}
}
}
反序列化后不能不保证是同一个类(可能一个实例field被删除了)。当类不同抛出java.io.InvalidClassException 。
每个序列化的对象有一个标识符。标识符不匹配抛出InvalidClassException 。
也许您已经在类中添加了一个实例字段,你想让这个field有默认值而不是抛出 InvalidClassException ,通过添加static final long serialVersionUID = long integer value到class。long integer value 必须是唯一的作为一个stream unique identifier (SUID)。
反序列化时,会比较SUID,如果匹配,当遭遇兼容的class change不会抛出InvalidClassException (比如添加实例field)。但是不兼容的class变更还是抛出异常(比如修改field name)。
注意:当你以某种方式改变一个类的时候,必须重新计算SUID。
JDK提供serialver tool 来生成 SUID。例如:
serialver Employee
生成:
Employee: static final long serialVersionUID = 1517331364702470316L;
windows可视化界面:
serialver -show
Custom Serialization and Deserialization
如果你要序列化没实现Serializable 的类,一种解决方案是,继承这个类,让子类实现 Serializable ,子类构造器呼叫父类。
当父类没声明无参构造是不行的。例子:
Listing 4-11. Problematic Deserialization
public class Employee1 {
private String name;
Employee1(String name) {
this.name = name;
}
@Override
public String toString() {
return name;
}
}
public class SerEmployee extends Employee1 implements Serializable {
SerEmployee(String name)
{
super(name);
}
}
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class SerializationDemo {
private final static String PATH = "E:\\SpringSourceCode\\src\\main\\resources\\image.txt";
public static void main(String[] args) {
ObjectOutputStream oos = null;
ObjectInputStream ois = null;
try {
oos = new ObjectOutputStream(new FileOutputStream(PATH));
SerEmployee se = new SerEmployee("John Doe");
System.out.println(se);
oos.writeObject(se);
oos.close();
oos = null;
System.out.println("se object written to file");
ois = new ObjectInputStream(new FileInputStream(PATH));
se = (SerEmployee) ois.readObject();
System.out.println("se object read from file");
System.out.println(se);
} catch (ClassNotFoundException cnfe) {
cnfe.printStackTrace();
} catch (IOException ioe) {
ioe.printStackTrace();
} finally {
if (oos != null)
try {
oos.close();
} catch (IOException ioe) {
assert false; // shouldn't happen in this context
}
if (ois != null)
try {
ois.close();
} catch (IOException ioe) {
assert false; // shouldn't happen in this context
}
}
}
}
输出
John Doe
java.io.InvalidClassException: com.jasu.nio._04_Streams.SerEmployee; no valid constructor
at java.io.ObjectStreamClass$ExceptionInfo.newInvalidClassException(ObjectStreamClass.java:157)
at java.io.ObjectStreamClass.checkDeserialize(ObjectStreamClass.java:862)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2034)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1567)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:427)
at com.jasu.nio._04_Streams.SerializationDemo.main(SerializationDemo.java:31)
因为Employee1 没有声明无参构造器。你可以用adapter pattern解决这个问题((https://en.wikipedia.org/wiki/Adapter_pattern )。
此外的例子:
Listing 4-12. Solving Problematic Deserialization
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
class Employee
{
private String name;
Employee(String name)
{
this.name = name;
}
@Override
public String toString()
{
return name;
}
}
class SerEmployee implements Serializable
{
private Employee emp;
private String name;
SerEmployee(String name)
{
this.name = name;
emp = new Employee(name);
}
private void writeObject(ObjectOutputStream oos) throws IOException
{
oos.writeUTF(name);
}
private void readObject(ObjectInputStream ois)
throws ClassNotFoundException, IOException
{
name = ois.readUTF();
emp = new Employee(name);
}
@Override
public String toString()
{
return name;
}
}public class SerializationDemo
{
public static void main(String[] args)
{
ObjectOutputStream oos = null;
ObjectInputStream ois = null;
try
{
oos = new ObjectOutputStream(new FileOutputStream("employee.dat"));
SerEmployee se = new SerEmployee("John Doe");
System.out.println(se);
oos.writeObject(se);
oos.close();
oos = null;
System.out.println("se object written to file");
ois = new ObjectInputStream(new FileInputStream("employee.dat"));
se = (SerEmployee) ois.readObject();
System.out.println("se object read from file");
System.out.println(se);
}
catch (ClassNotFoundException cnfe)
{
cnfe.printStackTrace();
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
finally
{
if (oos != null)
try
{
oos.close();
}
catch (IOException ioe)
{
assert false; // shouldn't happen in this context
}
if (ois != null)
try
{
ois.close();
}public class SerializationDemo
{
public static void main(String[] args)
{
ObjectOutputStream oos = null;
ObjectInputStream ois = null;
try
{
oos = new ObjectOutputStream(new FileOutputStream("employee.dat"));
SerEmployee se = new SerEmployee("John Doe");
System.out.println(se);
oos.writeObject(se);
oos.close();
oos = null;
System.out.println("se object written to file");
ois = new ObjectInputStream(new FileInputStream("employee.dat"));
se = (SerEmployee) ois.readObject();
System.out.println("se object read from file");
System.out.println(se);
}
catch (ClassNotFoundException cnfe)
{
cnfe.printStackTrace();
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
finally
{
if (oos != null)
try
{
oos.close();
}
catch (IOException ioe)
{
assert false; // shouldn't happen in this context
}
if (ois != null)
try
{
ois.close();
}catch (IOException ioe)
{
assert false; // shouldn't happen in this context
}
}
}
}
输出:
John Doe
se object written to file
se object read from file
John Doe
Externalization
Java支持 externalization 。不像默认/自定义serialization/deserialization , externalization提供序列化反序列化的完整控制。
注意:Externalization 帮你改善基于反射的序列化反序列化性能,给你完全控制那些field参与序列化。
通过java.io.Externalizable支持Externalization。接口有以下方法:
- void writeExternal(ObjectOutput out)
- void readExternal(ObjectInput in)
如果类实现 Externalizable ,例子:
Listing 4-13. Refactoring Listing 4-9’s Employee Class to Support Externalization
import java.io.Externalizable;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
public class Employee implements Externalizable
{
private String name;
private int age;
public Employee()
{
System.out.println("Employee() called");
} public Employee(String name, int age)
{
this.name = name;
this.age = age;
}
public String getName() { return name; }
public int getAge() { return age; }
@Override
public void writeExternal(ObjectOutput out) throws IOException
{
System.out.println("writeExternal() called");
out.writeUTF(name);
out.writeInt(age);
}
@Override
public void readExternal(ObjectInput in)
throws IOException, ClassNotFoundException
{
System.out.println("readExternal() called");
name = in.readUTF();
age = in.readInt();
}
}
输出:
writeExternal() called
Employee() called
readExternal() called
John Doe
36
PrintStream
在全部的stream类里,PrintStream 是古怪的:按命名约定应该叫 PrintOutputStream 。这个filter output stream 类写输入数据项的字符串形式到底层输出流。
注意:PrintStream 会使用默认字符编码转化string为字节(5章讨论)。PrintStream 不支持不同的编码,你该用等价的 PrintWriter 代替。然而因为standard I/O,你需要了解PrintStream 。
PrintStream 实例是print streams ,它的方法print() and println() ,打印integers, floating-point values, and other data items 的字符串形式到下面的输出流。
注意: line terminator (也叫 line separator ),不一定newline(也通常被称为换行 ),line separator 是系统属性line.separator. windows是回车码(13)也就是 \r ,紧接着实际的newline/line feed code(10),\n,linux只返回newline/line feed code 。
警告:不要在你用 print() or println() 方法输出的字符串上硬编码 \n escape sequence 。这样是不稳定的。
有3个有用的特点:
- 不像其他stream,不会从底层抛出
IOException。而是有checkError() 方法 - 可以被创建来自动刷新输出到底层输出流。字节写入自动flush() ,println()被调用,或者一个newline被写。
- 声明了一个
format(String format, Object... args)形式用于得到格式化输出。是用的Formatter类,11章介绍。也有便利的printf(String format, Object... args)方法。
Revisiting Standard I/O
System.in, System.out, and System.err are formally described by the following class fields in the System class:
- public static final InputStream in
- public static final PrintStream out
- public static final PrintStream err
对应standard input, standard output, and standard error streams 。
当你调用 System.in.read(), 来自于绑定到in的source。当标准输入时,Java初始化以引用键盘或文件流被重定向到文件。 out/err 设计屏幕或文件。你可以编程式指定input source, output destination, and error destination 通过System的方法:
- void setIn(InputStream in)
- void setOut(PrintStream out)
- void setErr(PrintStream err)
RedirectIO application例子:
Listing 4-14. Programmatically Specifying the Standard Input Source and Standard Output/Error Destinations
import java.io.FileInputStream;
import java.io.IOException;
import java.io.PrintStream;
public class RedirectIO
{
public static void main(String[] args) throws IOException
{
if (args.length != 3)
{
System.err.println("usage: java RedirectIO stdinfile " +
"stdoutfile stderrfile");
return;
}
System.setIn(new FileInputStream(args[0]));
System.setOut(new PrintStream(args[1]));
System.setErr(new PrintStream(args[2]));
int ch;
while ((ch = System.in.read()) != -1)
System.out.print((char) ch);
System.err.println("Redirected error output");
}
}
run java RedirectIO RedirectIO.java out.txt err.txt 。
Exercise
The following exercises are designed to test your understanding of Chapter 4’s content:
1. What is a stream?
2. What is the purpose of OutputStream’s flush() method?
3. True or false: OutputStream’s close() method automatically
flushes the output stream.
4. What is the purpose of InputStream’s mark(int) and reset()
methods?
5. How would you access a copy of a ByteArrayOutputStream
instance’s internal byte array?
6. True or false: FileOutputStream and FileInputStream provide
internal buffers to improve the performance of write and read
operations.
7. Why would you use PipedOutputStream and PipedInputStream?
8. Define filter stream.
9. What does it mean for two streams to be chained together?
10. How do you improve the performance of a file output stream or a file
input stream?
11. How do DataOutputStream and DataInputStream support
FileOutputStream and FileInputStream?
12. What is object serialization and deserialization?
13. What three forms of serialization and deserialization does Java
support?
14. What is the purpose of the Serializable interface?
15. What does the serialization mechanism do when it encounters an
object whose class doesn’t implement Serializable?
16. Identify the three stated reasons for Java not supporting unlimited
serialization.
17. How do you initiate serialization? How do you initiate deserialization?
18. True or false: Class fields are automatically serialized.
19. What is the purpose of the transient reserved word?
20. What does the deserialization mechanism do when it attempts to
deserialize an object whose class has changed?
21. How does the deserialization mechanism detect that a serialized
object’s class has changed?
22. How can you add an instance field to a class and avoid trouble when
deserializing an object that was serialized before the instance field
was added? What JDK tool can you use to help with this task?
23. How do you customize the default serialization and deserialization
mechanisms without using externalization?
24. How do you tell the serialization and deserialization mechanisms to
serialize or deserialize the object’s normal state before serializing or
deserializing additional data items?
25. How does externalization differ from default and custom serialization
and deserialization?
26. How does a class indicate that it supports externalization?
27. True or false: During externalization, the deserialization mechanism
throws InvalidClassException with a “no valid constructor”
message when it doesn’t detect a public noargument constructor.
28. What is the difference between PrintStream’s print() and
println() methods?
29. What does PrintStream’s noargument void println() method
accomplish?
30. How do you redirect the standard input, standard output, and standard
error streams?
31. Improve Listing 4-1’s Copy application (performance wise) by using
BufferedInputStream and BufferedOutputStream. Copy
should read the bytes to be copied from the buffered input stream and
write these bytes to the buffered output stream.
32. Create a Java application named Split for splitting a large file into
a number of smaller partx files (where x starts at 0 and increments;
for example, part0, part1, part2, and so on). Each partx file
(except possibly the last partx file, which holds the remaining bytes)
will have the same size. This application has the following usage
syntax: java Split path. Furthermore, your implementation must
use the BufferedInputStream, BufferedOutputStream, File,
FileInputStream, and FileOutputStream classes.
Summary
Java uses streams to perform I/O operations. A stream is an ordered sequence of bytes of an arbitrary length. Bytes flow over an output stream from an application to a destination and flow over an input stream from a source to an application.
The java.io package provides several classes that identify various stream destinations and sources. These classes are descendants of the abstract OutputStream and InputStream classes. FileOutputStream and BufferedInputStream are examples.
This chapter explored OutputStream and InputStream, followed by the byte array, file, piped, filter, buffered, data, object, and print streams. While covering object streams, it introduced the topics of serialization and externalization. The chapter concluded by revisiting standard I/O.
Chapter 5 Writers and Readers
Java的streams对字节序列流很有用,但是对字符流不好,因为字节流和字符流是两种东西:一个字节是8-bit data item ,一个字符是16-bit data item 。char and java.lang. String 天生的处理字符而不是字节。
更重要的是byte streams 不了解character sets (字符集,整型值之间的映射,称为代码点,和符号,如Unicode )和 character encodings (字符集合的成员之间的映射,以及为效率编码这些字符的字节序列,比如UTF-8 )
A BRIEF HISTORY OF CHARACTER SETS AND CHARACTER ENCODINGS
如果你需要 stream characters ,你需要用Java’s writer and reader 类,它们支持character I/O (用chart工作而不是byte)。此外, writer and reader 也考虑了字符编码。
Writer and Reader Classes Overview
层次结构:
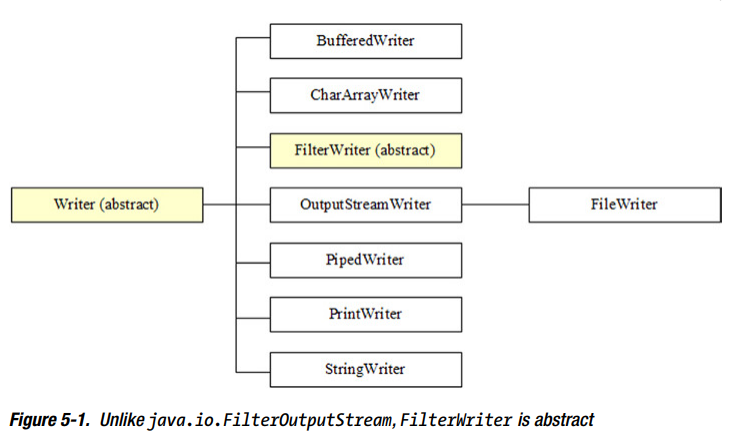
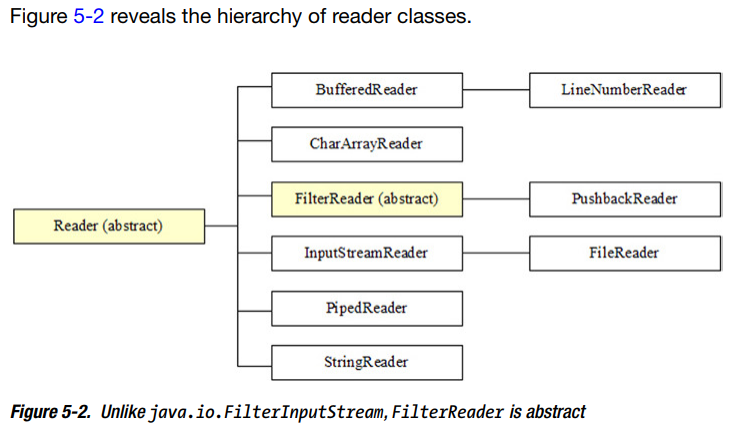
FilterWriter and FilterReader是抽象的。BufferedWriter and BufferedReader 不继承 FilterWriter and FilterReader ,这是和stream层次不一样的地方。
output stream and input stream 是1.0引入的,FilterOutputStream and FilterInputStream 本该是抽象的,但是已经不能变了已经被使用了。1.1’s writer and reader 就有时间改变这些错误。
注意:关于 BufferedWriter and BufferedReader 直接继承Writer and Reader 而不是 FilterWriter and FilterReader ,这种变化与性能有关 。调用BufferedOutputStream’s write() methods and BufferedInputStream’s read() 方法导致调用FilterOutputStream’s write() methods and FilterInputStream’s read() 方法。BufferedWriter and BufferedReader 不继承Filexxxxer会有更好的性能。
Writer and Reader
Writer and java.io.OutputStream 的不同点:
- Writer声明了几个append() 方法添加字符到writer。因为Writer implements the java.lang.Appendable接口,和
java.util.Formatter类协作,来输出格式化的string。 - writer声明额外的 write() 方法,和便利的
write(String str)方法
Reader and java.io.InputStream 的不同点:
- Reader 声明read(char[]) and read(char[], int, int)
- Reader 没有声明available() 方法
- 声明了一个 boolean ready() 方法,当下一个read() 调用被保证不被阻塞输出就返回true。
- 声明了一个int read(CharBuffer target) 方法,从一个 character buffer 读取字符( CharBuffer in Chapter 6 )。
OutputStreamWriter and InputStreamReader
OutputStreamWriter 是一个输入的字符序列和要流出的字节流的桥梁。被写到这个writer的字符根据默认或指定编码被编码成字节。
注意: default character encoding 可以从file.encoding 系统属性拿到。
每一个 OutputStreamWriter’s write() 方法的调用都会导致一个encoder 在给出的字符上被调用。生成的字节在buffer累积,在被写入下面的输出流之前。传递给write的方法没有被buffered。
OutputStreamWriter有4个构造器,包括下面2个:
- OutputStreamWriter(OutputStream out)
- OutputStreamWriter(OutputStream out, String charsetName) 指定编码
注意:OutputStreamWriter 依赖 java.nio.charset. Charset and java.nio.charset.CharsetEncoder 抽象类执行字符编码。
例子:
FileOutputStream fos = new FileOutputStream("polish.txt");
OutputStreamWriter osw = new OutputStreamWriter(fos, "8859_2");
char ch = '\u0323'; // Accented N.
osw.write(ch);
InputStreamReader类是一个进来的字节流和出去的字符序列的桥梁。每个InputStreamReader’s read() 的调用导致一个或多个字节从底层输入流被读。为了效率可能会读更多的字节。
4个构造器,其中2个:
- InputStreamReader(InputStream in)
- InputStreamReader(InputStream in, String charsetName)
注意:OutputStreamWriter and InputStreamReader 声明了getEncoding() 方法,返回使用的编码
FileWriter and FileReader
FileWriter 是一个方便类,写字符到文件。它继承OutputStreamWriter ,一个这个类的实例等同于下面
FileOutputStream fos = new FileOutputStream(path);
OutputStreamWriter osw;
osw = new OutputStreamWriter(fos, System.getProperty("file.encoding"));
FileReader是一个方便类,从文件读取字符。继承InputStreamReader ,一个这个类的实例等同于:
FileInputStream fis = new FileInputStream(path);
InputStreamReader isr;
isr = new InputStreamReader(fis, System.getProperty("file.encoding"));
FileWriter nor FileReader 都没提供它们自己的方法,你可以调用继承方法。
例子:
Listing 5-1. Demonstrating the FileWriter and FileReader Classes
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class FWFRDemo
{
final static String MSG = "Test message";
public static void main(String[] args) throws IOException
{
try (FileWriter fw = new FileWriter("temp"))
{
fw.write(MSG, 0, MSG.length());
}
char[] buf = new char[MSG.length()];
try (FileReader fr = new FileReader("temp"))
{
fr.read(buf, 0, MSG.length());
System.out.println(buf);
}
}
}
BufferedWriter and BufferedReader
BufferedWriter 写文本到字符输出流( Writer 实例),缓冲字符,以提供高效的写单个字符、数组和字符串。构造函数:
- BufferedWriter(Writer out)
- BufferedWriter(Writer out, int size)
size可以指定,或者默认的8,192 bytes 。
BufferedWriter包含一个便利的void newLine() 方法,写一个行分隔符字符串,来打断这一行。
BufferedReader 从字符输入流(Reader 实例)读取文本,缓冲字符以便有效读取字符、数组和行。构造函数:
- BufferedReader(Reader in)
- BufferedReader(Reader in, int size)
size可以指定,或者默认8,192 bytes 。
有个方便的 String readLine() 方法,读取行文本,不包括任何换行符。
例子:
Listing 5-2. Demonstrating the BufferedWriter and BufferedReader Classes
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class BWBRDemo
{
static String[] lines =
{
"It was the best of times, it was the worst of times,",
"it was the age of wisdom, it was the age of foolishness,",
"it was the epoch of belief, it was the epoch of incredulity,",
"it was the season of Light, it was the season of Darkness,",
"it was the spring of hope, it was the winter of despair."
};
public static void main(String[] args) throws IOException
{
try (BufferedWriter bw = new BufferedWriter(new FileWriter("temp")))
{
for (String line: lines)
{
bw.write(line, 0, line.length());
bw.newLine();
}
}
try (BufferedReader br = new BufferedReader(new FileReader("temp")))
{
String line;
while ((line = br.readLine()) != null)
System.out.println(line);
}
}
}
Exercise
The following exercises are designed to test your understanding of Chapter 5’s content:
1. Why are Java’s stream classes not good at streaming characters?
2. What does Java provide as the preferred alternative to stream classes
when it comes to character I/O?
3. True or false: Reader declares an available() method.
4. What is the purpose of the OutputStreamWriter class? What is the
purpose of the InputStreamReader class?
5. How do you identify the default character encoding?
6. What is the purpose of the FileWriter class? What is the purpose of
the FileReader class?
7. What method does BufferedWriter provide for writing a line
separator?
8. It’s often convenient to read lines of text from standard input, and the
InputStreamReader and BufferedReader classes make this task
possible. Create a Java application named CircleInfo that, after
obtaining a BufferedReader instance that is chained to standard
input, presents a loop that prompts the user to enter a radius, parses
the entered radius into a double value, and outputs a pair of messages
that report the circle’s circumference and area based on this radius.
Summary
Java’s stream classes are good for streaming sequences of bytes, but they’re not good for streaming sequences of characters because bytes and characters are two different things. A byte represents an 8-bit data item and a character represents a 16-bit data item. Also, Java’s char and String types naturally handle characters instead of bytes. More importantly, byte streams have no knowledge of character sets and their encodings.
Java provides writer and reader classes to stream characters. They support character I/O (they work with char instead of byte) and take character encodings into account. The abstract Writer and Reader classes describe what it means to be a writer and a reader.
Writer and Reader are subclassed by OutputStreamWriter and InputStreamReader, which bridge the gap between character and byte streams. These classes are subclassed by the FileWriter and FileReader convenience classes, which facilitate writing/reading characters to/from files. Writer and Reader are also subclassed by BufferedWriter and BufferedReader, which buffer characters for efficiency.
PART Ⅲ New I/O APIs
Chapter 6 Buffers
NIO是基于buffer的,它的内容通过channels被发送到 I/O services 或者从 I/O services 接收。
Introducing Buffers
一个buffer是一个对象,存储固定数量的发送到或从 I/O service(操作系统执行输入输出的组件)接收的数据。它处于应用和channel之间,channel写缓冲数据到service,或者从service读取数据存到buffer。
缓冲区具有四个属性:
- Capacity: 可以存在buffer的data item的总数。创建时指定,并且之后不能更改。
- Limit: 第一个不能被读写的元素的以0为基准的索引。换句话说,它表明了buffer里的 “live” data items 。
- Position: 下一个可以被读的data item或者data item 可以被写位置的以0为基准的索引。
- Mark: 当buffer的 reset() 方法被调用时设置位置的以0为基准的索引。Mark开始未被定义。
这4个属性联系如下:0 <= mark <= position <= limit <= capacity
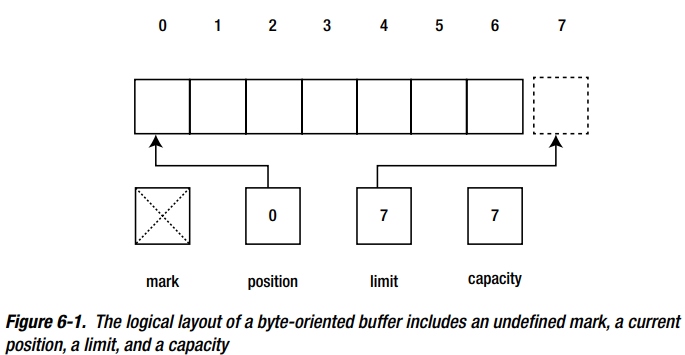
buffer最多可以存储7个元素。Mark初始未被定义,position被设置为0,limit被设置为容量(7),你只可以访问0-6 positions。
Buffer and its Children
Buffer’s 的方法:
Table 6-1. Buffer Methods
| Method | Description |
|---|---|
| Object array() | 返回支持这个buffer的array。这个方法用于允许 array-backed buffers 更效率地传递给 native code 。具体的子类重写这个方法提供更强大的类型返回值。当buffer由一个只读数组支撑返回 java.nio.ReadOnlyBufferException ,不可访问数组返回 java.lang.UnsupportedOperationException 。 |
| int arrayOffset() | 返回buffer支持数组内第一个buffer元素的offset。当buffer由一个数组支撑, buffer position p 对应array index p + arrayOffset() 。在调用此方法前调用 hasArray() 确保buffer有可访问的支撑数组。只读抛出 ReadOnlyBufferException ,不可访问抛出 UnsupportedOperationException 。 |
| int capacity() | 返回数组的容量 |
| Buffer clear() | 清空buffer。position设置为0,limit被设置为容量,mark被丢弃。这个方法不删除buffer的数据,但是方法名就像删除了似得,因为大部分要使用这个方法的情况都是删除。 |
| Buffer flip() | 翻转这个buffer。limit被设置为当前position,然后position被设置为0。Mark被定义的话会被丢弃。 |
| boolean hasArray() | 如果 buffer 由array支撑且不是只读返回true;否则false。返回true时, array() and arrayOffset() 都可以安全调用。 |
| boolean hasRemaining() | 如果至少一个元素残留在buffer返回true(就是,在当前position和limit之间)。否则,返回false。 |
| boolean isDirect() | 当buffer是 direct byte buffer 返回true。否则false |
| boolean isReadOnly() | buffer read-only返回true。 |
| int limit() | 返回limit |
| Buffer limit(int newLimit) | 设置limit为newLimit。当position大于newLimit,position被设置为newLimit。当mark被定义为大于newLimit,mark被丢弃。newLimit是负的或者大于容量抛出 java.lang.IllegalArgumentException ;否则返回这个buffer。 |
| Buffer mark() | 设置Mark到它的position,返回buffer。 |
| int position() | 返回position |
| Buffer position (int newPosition) | 设置position为newPosition。当Mark被定义大于newPosition,Mark被丢弃。为负或大于当前limit抛出 IllegalArgumentException ;否则返回buffer。 |
| int remaining() | 返回当前position和limit之间元素的数量 |
| Buffer reset() | 重置buffer的position到先前的Mark位置。调用这个方法不会改变和丢弃mark的值。mark没设置抛出 java.nio.InvalidMarkException ;否则返回buffer。 |
| Buffer rewind() | 倒回去,然后返回这个buffer。position被设为0,mark被丢弃。 |
上面方法很多都返回buffer实例,所以可以链式编程。例如:
buf.mark();
buf.position(2);
buf.reset();
可以用:
buf.mark().position(2).reset();
6-1也表明所有buffer都可以读,但是不是所有都能被写——例如,一个由memory-mapped file支撑的buffer是只读的。一定不能写只读的buffer;否则抛出ReadOnlyBufferException 。试图写的时候调用isReadOnly() 看是否可以写。
警告:Buffers不是线程安全的。你想从多线程访问buffer必须采取同步。
java.nio 包有几个抽象类拓展了Buffer,除了Boolean之外,每个基本类型都有一个 : ByteBuffer, CharBuffer, DoubleBuffer, FloatBuffer, IntBuffer, LongBuffer, and ShortBuffer。此外,也有MappedByteBuffer 。
注意:操作系统执行面向字节的I/O,你使用 ByteBuffer来创建byte-oriented buffers 。其他primitive-type buffer 类让你创建multibyte view buffers (discussed later ),然后你可以概念性地对字符,双精度浮点,32-bits integer等等执行I/O。然而,I/O操作是字节的流运行的。
演示例子:
Listing 6-1. Demonstrating a Byte-Oriented Buffer
import java.nio.Buffer;
import java.nio.ByteBuffer;
public class BufferDemo
{
public static void main(String[] args)
{
Buffer buffer = ByteBuffer.allocate(7);
System.out.println("Capacity: " + buffer.capacity());
System.out.println("Limit: " + buffer.limit());
System.out.println("Position: " + buffer.position());
System.out.println("Remaining: " + buffer.remaining());
System.out.println("Changing buffer limit to 5");
buffer.limit(5);
System.out.println("Limit: " + buffer.limit());
System.out.println("Position: " + buffer.position());
System.out.println("Remaining: " + buffer.remaining());
System.out.println("Changing buffer position to 3");
buffer.position(3);
System.out.println("Position: " + buffer.position());
System.out.println("Remaining: " + buffer.remaining());
System.out.println(buffer);
}
}
不能实例化buffer因为是抽象的,而是用ByteBuffer 类的 allocate() 方法分配一个7字节的buffer。
输出:
Capacity: 7
Limit: 7
Position: 0
Remaining: 7
Changing buffer limit to 5
Limit: 5
Position: 0
Remaining: 5
Changing buffer position to 3
Position: 3
Remaining: 2
java.nio.HeapByteBuffer[pos=3 lim=5 cap=7]
最后的buffer是一个 java.nio.HeapByteBuffer 实例。
Buffers in Depth
这节深入探索buffer创建,读写,flipping,marking, Buffer subclass operations ,byte ordering和direct buffers 。
注意:虽然 primitive-type buffer类有相似的能力,ByteBuffer 是最大最全能通用的。毕竟,字节是操作系统用来传递data items的最小单元。
Buffer Creation
ByteBuffer and the other primitive-type buffer类声明了很多方法创建一个该类型的buffer。例如ByteBuffer:
-
ByteBuffer allocate(int capacity): 分配一个新的指定容量的byte buffer。position是0,limit是容量,mark未定义,每个元素被初始化为0。有一个支撑数组,offset是0。容量为负抛出
IllegalArgumentException。 -
ByteBuffer allocateDirect(int capacity): 分配一个新的指定容量的direct byte buffer (discussed later) 。position是0,limit是容量,mark未定义,每个元素被初始化为0。它是否有一个支撑数组是未知的。容量为负抛出
IllegalArgumentException。在JDK 7之前,这个方法分配的direct buffers 和page边界对齐。在JDK 7,实现改变了,不再是页面对齐的。减少了创建大量buffers应用的内存需求。(To learn about an operating system’s paging memory-management mechanism, which is based on pages, check out Wikipedia’s “Paging” topic at https://en.wikipedia.org/wiki/Paging )
-
ByteBuffer wrap(byte[] array): 将一个字节数组封装到buffer。新buffer是数组支撑的;就是,改变buffer就会改变数组,反之亦然。容量和limit是array.length ,position为0,Mark未定义。array的offset是0。
-
ByteBuffer wrap(byte[] array, int offset, int length) 将一个字节数组封装到buffer。新buffer是数组支撑的。新buffer的容量为array.length,position被设置为offset,limit被设置为offset+length,mark未定义。数组offset是0。是offset是负,或大于array.length或者当length是负或大于array.length - offset 抛出
java.lang. IndexOutOfBoundsException。
下面两种方式创建buffer:
ByteBuffer buffer = ByteBuffer.allocate(10);
byte[] bytes = new byte[200];
ByteBuffer buffer2 = ByteBuffer.wrap(bytes);
buffer = ByteBuffer.wrap(bytes, 10, 50);
上面这个创建了一个buffer,position=10,limit=50,capacity=200。虽然看起来buffer只能访问这个数组的子串,但你可以通过 array() 方法访问这些支撑数组(就是byte[] array() )。并且hasArray() 返回true。(当 hasArray() 返回true,你需要调用arrayOffset() 得到数组里第一个data item的offset)
例子:
Listing 6-2. Creating Byte-Oriented Buffers via Allocation and Wrapping
import java.nio.ByteBuffer;
public class BufferDemo
{
public static void main(String[] args)
{
ByteBuffer buffer1 = ByteBuffer.allocate(10);
if (buffer1.hasArray())
{
System.out.println("buffer1 array: " + buffer1.array());
System.out.println("Buffer1 array offset: " +
buffer1.arrayOffset());
System.out.println("Capacity: " + buffer1.capacity());
System.out.println("Limit: " + buffer1.limit());
System.out.println("Position: " + buffer1.position());
System.out.println("Remaining: " + buffer1.remaining());
System.out.println();
}
byte[] bytes = new byte[200];
ByteBuffer buffer2 = ByteBuffer.wrap(bytes);
buffer2 = ByteBuffer.wrap(bytes, 10, 50);
if (buffer2.hasArray())
{
System.out.println("buffer2 array: " + buffer2.array());
System.out.println("Buffer2 array offset: " +
buffer2.arrayOffset());
System.out.println("Capacity: " + buffer2.capacity());
System.out.println("Limit: " + buffer2.limit());
System.out.println("Position: " + buffer2.position());
System.out.println("Remaining: " + buffer2.remaining());
}
}
}
编译运行,输出:
buffer1 array: [B@659e0bfd
Buffer1 array offset: 0
Capacity: 10
Limit: 10
Position: 0
Remaining: 10
buffer2 array: [B@2a139a55
Buffer2 array offset: 0
Capacity: 200
Limit: 60
Position: 10
Remaining: 50
除了管理保存在外部数组的数据元素外(via the wrap() 方法),buffer也能管理保存在其他buffers的数据。当你创建一个buffer管理另一个buffer的data,被创建的buffer被认为是view buffer。在两个buffer中所做的更改都反映在另一个buffer中。
View buffers 用Buffer子类的duplicate()方法创建。产生的view buffer相当于原始buffer; 两个buffer共享相同的data items且容量相同。然而,每个buffer有它自己的 position, limit, and mark 。当被duplicated 的buffer是read-only或者direct,view buffer 也是read-only或者direct。
考虑以下:
ByteBuffer buffer = ByteBuffer.allocate(10);
ByteBuffer bufferView = buffer.duplicate();
两个buffer共享array。此时,position, limit, and (undefined) mark 是一样的。然而,这些属性可以彼此独立于另一个buffer。
也可以调用ByteBuffer’s asxBuffer() 创建view buffers。例如,LongBuffer asLongBuffer() 返回一个view buffer将字节buffer概念化为长整型的buffer。
注意:Read-only view buffers可以调用比如ByteBuffer asReadOnlyBuffer() 的方法创建。任何view buffer改变的尝试导致 ReadOnlyBufferException 。然而,原始buffer内容(假设不是只读)可以变,只读的view buffer将反映这些变化 。
Buffer Writing and Reading
ByteBuffer and the other primitive-type buffer类声明了几个重载的 put() and get() 方法用于写 data items 和从buffer读 data items 。这些方法在需要索引参数的时候是绝对的不需要索引时是相对的。
例如,ByteBuffer声明绝对的ByteBuffer put(int index, byte b) 方法在索引index存储byte b,以及byte get(int index) 方法获取index位置的字节。也声明了相对的 ByteBuffer put(byte b) 方法在当前buffer的position存b然后增加position,以及相对的byte get() 获取buffer当前position的字节并且增加当前position。
绝对的put() and get()方法当索引是负或超出或者等于limit抛出IndexOutOfBoundsException 。相对的 put() 在当前position大于或等于limit时抛出java.nio.BufferOverflowException ,相对的get() 方法在当前position大于或等于limit时抛出java.nio.BufferUnderflowException 。另外,两种put()方法都在只读时抛出 ReadOnlyBufferException 。
例子:
Listing 6-3. Writing Bytes to and Reading Them from a Buffer
import java.nio.ByteBuffer;
public class BufferDemo
{
public static void main(String[] args)
{
ByteBuffer buffer = ByteBuffer.allocate(7);
System.out.println("Capacity = " + buffer.capacity());
System.out.println("Limit = " + buffer.limit());
System.out.println("Position = " + buffer.position());
System.out.println("Remaining = " + buffer.remaining());
buffer.put((byte) 10).put((byte) 20).put((byte) 30);
System.out.println("Capacity = " + buffer.capacity());
System.out.println("Limit = " + buffer.limit());
System.out.println("Position = " + buffer.position());
System.out.println("Remaining = " + buffer.remaining());
for (int i = 0; i < buffer.position(); i++)
System.out.println(buffer.get(i));
}
}
编译运行输出:
Capacity = 7
Limit = 7
Position = 0
Remaining = 7
Capacity = 7
Limit = 7
Position = 3
Remaining = 4
10
20
30
如图:
随后的调用get() 方法没有改变position,还是3。
技巧:为获得最高效率,你可以执行批量数据传输,使用ByteBuffer put(byte[] src), ByteBuffer put(byte[] src, int offset, int length), ByteBuffer get(byte[] dst), and ByteBuffer get(byte[] dst, int offset, int length) 来读写字节数组。
Flipping Buffers
在填充buffer后,你必须准备它用于通过channel排干。您通过缓冲区时,通道将访问未定义的数据,超出当前位置。
要解决这个问题,你可以reset position为0,但是channel怎么知道什么时候到达插入的数据的末尾呢?解决办法是使用limit属性,它表明了buffer活动区间的end。基本上,设置limit到当前position,然后重置current position为0。
你可以执行以下代码完成这个任务,也会清除所有定义的mark:
buffer.limit(buffer.position()).position(0);
然而,有一个更简便的做法:
buffer.flip();
两种情况,buffer都准备好去排干了。
假设buffer.flip() 在listing 6-3最后执行,figure 6-3 表明了 flip() 之后的buffer状态:
调用 buffer.remaining() 返回3。这个值表明了能用于排干的字节数。
Listing 6-4 给出另一个buffer-flipping示范,使用了character buffer。
Listing 6-4. Writing Characters to and Reading Them from a Character Buffer
import java.nio.CharBuffer;
public class BufferDemo
{
public static void main(String[] args)
{
String[] poem =
{
"Roses are red",
"Violets are blue",
"Sugar is sweet",
"And so are you."
};
CharBuffer buffer = CharBuffer.allocate(50);
for (int i = 0; i < poem.length; i++)
{
// Fill the buffer.
for (int j = 0; j < poem[i].length(); j++)
buffer.put(poem[i].charAt(j));
// Flip the buffer so that its contents can be read.
buffer.flip();
// Drain the buffer.
while (buffer.hasRemaining())
System.out.print(buffer.get());
// Empty the buffer to prevent BufferOverflowException.
buffer.clear();
System.out.println();
}
}
}
输出:
Roses are red
Violets are blue
Sugar is sweet
And so are you.
注意:rewind()和 flip() 类似但是忽略limit。并且,调用flip()2次也不会得到buffer的初始状态,而是size为0。调用put() 抛出BufferOverflowException ,调用get()抛出BufferUnderflowException ,get(int i)抛出 IndexOutOfBoundsException 。
Marking Buffers
使用mark() 标记buffer,随后调用reset()返回标记位置。例如,假设你执行了ByteBuffer buffer = ByteBuffer.allocate(7);, 然后buffer.put((byte) 10).put((byte) 20).put((byte) 30).put((byte) 40);, 然后buffer.limit(4);. 。当前position和limit都为4。
继续,假设你执行了 buffer.position(1).mark(). position(3) 。6-4显示了buffer的状态:
如果你把buffer发到一个channel,字节40会被发送(因为position(3) 现在的position是3),然后position会提到4。如果你接着执行buffer.reset() ;然后把buffer发送给channel,position会被设置到mark (1) ,bytes 20, 30, and 40 (所有从当前位置到limit的字节),会被发到channel(以这个顺序)。
代码:
Listing 6-5. Marking the Current Buffer Position and Resetting the Current Position to the Marked Position
import java.nio.ByteBuffer;
public class BufferDemo
{
public static void main(String[] args)
{
ByteBuffer buffer = ByteBuffer.allocate(7);
buffer.put((byte) 10).put((byte) 20).put((byte) 30).put((byte) 40);
buffer.limit(4);
buffer.position(1).mark().position(3);
System.out.println(buffer.get());
System.out.println();
buffer.reset();
while (buffer.hasRemaining())
System.out.println(buffer.get());
}
}
输出:
40
20
30
40
警告:不要混淆reset() 和clear() 。clear() 方法标记buffer为空而 reset() 改变buffer的当前position到先前mark的位置,或者没标记就抛出 InvalidMarkException 。
Buffer Subclass Operations
ByteBuffer and the other primitive-type buffer类声明了compact() 方法,对压缩buffer很有用,通过复制当前position到limit的所有bytes到buffer的开头。index p = position() 的字节被复制到index 0, index p + 1 的字节复制到index 1,…直到 index limit() - 1 被复制到index n = limit() - 1 - p 。buffer的当前position被设置为n+1,limit被设置为容量。mark被定义就丢弃。
你从一个buffer写数据后调用compact,来解决不是所有buffer内容都被写入的场景。考虑下面:
buf.clear(); // Prepare buffer for use
while (in.read(buf) != -1)
{
buf.flip(); // Prepare buffer for draining.
out.write(buf); // Write the buffer.
buf.compact(); // Do this in case of a partial write.
}
compact() 方法调用移动没有被写的buffer数据到buffer开头,然后下次read()可以添加读数据到buffer的数据,而不是重写。
你偶尔可能需要比较buffer的等同或顺序。所有的buffer除了 MappedByteBuffer 都重写了equals() and compareTo() 来执行比较———MappedByteBuffer继承ByteBuffer没重写。
System.out.println(bytBuf1.equals(bytBuf2));
System.out.println(bytBuf1.compareTo(bytBuf2));
equals(), same element type , same number of remaining elements ,two sequences of remaining elements ,不取决于starting positions。
compareTo() ,比较顺序,比较sequences of remaining elements lexicographically ,不考虑starting position 。
Byte Ordering
Nonbyte primitive types except for Boolean 由几个字节组成:一个字符或short integer占2个字节,32-bit integer或者一个浮点值占4字节,long integer或双精度浮点值占8字节。这些多字节类型的值被存在连续的内存位置的序列。然而,这些字节的排序可能因操作系统而异。
例如,32-bit long integer 0x10203040 。This value’s four bytes could be stored in memory (from low address to high address) as 10, 20, 30, 40 ;这种编排方式叫 big endian order (the most-significant byte, the “big” end, is stored at the lowest address) 。也可以用40, 30, 20, 10 存;叫little endian order (the least-significant byte, the “little” end, is stored at the lowest address)。
Java提供 java.nio.ByteOrder 类帮你处理字节排序在多字节值互写的时候。声明了ByteOrder nativeOrder() 返回操作系统的ByteOrder 实例。这个实例是 ByteOrder’s BIG_ENDIAN and LITTLE_ENDIAN constants 的其中之一,没有其他的,你可以比较 nativeOrder()的返回值和常数。
多字节类也有提供。
order() 返回的 ByteOrder 可能考虑buffer的创建方式。view buffer的order不能被变。
ByteBuffer 不同与多字节类在字节排序上。默认字节排序总是 big endian ,即使操作系统是little endian 。因为Java’s default byte order 是 big endian ,让类文件和序列化的对象存储数据一致。
声明了 ByteBuffer order(ByteOrder bo) 来改变字节排序。
改变的字节排序对例如 LongBuffer asLongBuffer() 形成的view buffer是可见的。
Direct Byte Buffers
不像多字节buffers, byte buffers 可以作为channel-based I/O 的sources和targets。这不应该是一个惊喜因为操作系统在内存区域执行IO是连续的8字节的序列(不是浮点和32-bit integer)。
操作系统可以直接访问进程的地址空间。例如,操作系统可以直接访问JVM进程地址空间来执行基于字节数组的数据传输操作。然而,JVM可能不会连续地存储字节数组或者它的垃圾收集器把字节数组移动到另一个位置。由于这些限制, direct byte buffers 被创建。
direct byte buffer,是一个byte buffer ,与 channels 和native code 交互来执行I/O。direct byte buffer 尝试在内存区域储存字节元素,channel通过native code用字节元素来执行 direct (raw) access ,告诉操作系统直接排干/填充内存区域。
Direct byte buffers是JVM上最有效的执行I/O的方法。尽管你也可以传递nondirect byte buffers给通道,可能产生性能问题,因为nondirect byte buffers不总是能够充当native I/O operations的target。
当传递了一个 nondirect byte buffer ,channel可能需要创建一个临时的direct byte buffer ,复制nondirect byte buffer的内容到direct byte buffer,在临时的direct byte buffer上执行I/O操作,并且复制临时 direct byte buffer的内容到nondirect byte buffer 。临时direct byte buffer会被垃圾收集。
虽然优化了I/O,创建 direct byte buffer可能很昂贵因为在JVM堆之外的内存需要由操作系统分配,建立/拆除这个内存会比这个buffer在堆内的时间更长。
通过ByteBuffer’s allocateDirect() 得到direct byte buffer。
Exercise
The following exercises are designed to test your understanding of Chapter 6’s content:
1. What is a buffer?
2. Identify a buffer’s four properties.
3. What happens when you invoke Buffer’s array() method on a
buffer backed by a read-only array?
4. What happens when you invoke Buffer’s flip() method on a buffer?
5. What happens when you invoke Buffer’s reset() method on a
buffer where a mark has not been set?
6. True or false: Buffers are thread-safe.
7. Identify the classes that extend the abstract Buffer class.
8. How do you create a byte buffer?
9. Define view buffer.
10. How is a view buffer created?
11. How do you create a read-only view buffer?
12. Identify ByteBuffer’s methods for storing a single byte in a byte
buffer and fetching a single byte from a byte buffer.
13. What causes BufferOverflowException or
BufferUnderflowException to occur?
14. What is the equivalent of executing buffer.flip();?
15. True or false: Calling flip() twice returns you to the original state.
16. What is the difference between Buffer’s clear() and reset()
methods?
17. What does ByteBuffer’s compact() method accomplish?
18. What is the purpose of the ByteOrder class?
19. Define direct byte buffer.
20. How do you obtain a direct byte buffer?
21. Why could it be expensive to create a direct byte buffer?
22. Create a ViewBufferDemo application that populates a byte buffer
with the values 0, 0x6e, 0, 0x69, 0, 0x6f; creates a character view
buffer; and iterates over the view buffer, outputting each character.
Summary
A buffer is an NIO object that stores a fixed amount of data to be sent to or received from an I/O service. It sits between an application and a channel that writes the buffered data to the service or reads the data from the service and deposits it into the buffer.
Buffers possess capacity, limit, position, and mark properties. These four properties are related as follows: 0 <= mark <= position <= limit <= capacity.
Buffers are implemented by abstract classes that derive from the abstract Buffer class. These classes include ByteBuffer, CharBuffer, DoubleBuffer, FloatBuffer, IntBuffer, LongBuffer, and ShortBuffer. Furthermore, ByteBuffer is subclassed by the abstract MappedByteBuffer class.
In this chapter, you learned how to create buffers (including view buffers), write and read buffer contents, flip buffers, mark buffers, and perform additional operations on buffers such as compaction. You also learned about byte ordering and direct byte buffers.
Chapter 7 Channels
Channel协同buffer执行高性能I/O。这章介绍channel类型。
Introducing Channels
channel是一个对象代表一个到 hardware device, a file, a network socket, an application component, or another entity(能读写和执行其他I/O操作)的一个 open connection 。channels效率地在byte buffers 和操作系统 I/O service sources or destinations之间传递数据。
注意:Channels是访问 I/O services 的gateways 。Channels使用byte buffers作为端点传递和接收数据。
在操作系统文件句柄( file handle ,Windows)/文件描述符(file descriptor ) 与 Channel之间总存在一一对应。当你在file context使用channel,channel总是被连接到一个打开的文件描述符。尽管channel比 file descriptors更抽象,他们仍然能够对操作系统的I/O设施进行建模。
Channel and Its Children
通过java.nio.channels and java.nio.channels.spi 提供channel支持。应用程序与位于前包中的类型进行交互 ;定义新的selector providers的开发人员使用后包。
所有的channels都是最终实现了java.nio.channels.Channel 接口的类的实例。Channel声明下面的方法:
- void close(): 关闭channel。当channel已经关闭,调用close()无效。如果另一个线程已经调用了close(),一个新的close()调用会在第一个调用结束之前阻塞住,之后 close() 没有效果地返回。I/O错误抛出
java.io.IOException。在channel关闭后,任何在它上面尝试I/O操作都会抛出java.nio. channels.ClosedChannelException。 - boolean isOpen(): 返回channel的开闭状态。
这些方法表明只有两个操作是对所有channel通用:关闭channel和确定打开或关闭状态。为了支持I/O,channel被扩展为java.nio.channels. WritableByteChannel 和java.nio.channels.ReadableByteChannel 接口:
- WritableByteChannel 声明了一个抽象的int write(ByteBuffer buffer) 方法,从buffer到一个序列的字节到当前channel。返回实际被写的字节数量。当channel没有开放写抛出
java.nio.channels.NonWritableChannelException,channel关闭了抛出java.nio. channels.ClosedChannelException,写的时候另一个线程关闭了channel抛出java.nio.channels.AsynchronousCloseException,当写操作执行的时候当前线程被另一个线程打断了(从而关闭通道并设置当前线程的中断状态)抛出java.nio.channels.ClosedByInterruptException,I/O error 抛出IOException。 - ReadableByteChannel 声明了抽象read(ByteBuffer buffer) 方法,从当前channel读取字节到buffer。返回实际读取的字节数(没有字节可读返回-1)。当channel没开放读抛出
java.nio.channels. NonReadableChannelException,channel关闭了抛出ClosedChannelException,读的时候另一个线程关闭了channel抛出java.nio.channels.AsynchronousCloseException,当读操作执行的时候当前线程被另一个线程打断了抛出java.nio.channels.ClosedByInterruptException,从而关闭通道并设置当前线程的中断状态;I/O error 抛出IOException。
注意:一个只实现了WritableByteChannel or ReadableByteChannel的channel类是单向的。从可写的byte channel读或者从可读的byte channel写都导致异常抛出。
你可以使用 instanceof 操作符确定一个channel实例实现了那个接口。因为测试这两个接口很尴尬,Java提供 java.nio.channels.ByteChannel 接口,是一个空的标记接口继承了这两个接口。当你要了解一个channel是不是双向的,使用channel instanceof ByteChannel 会很方便。
Channel也被扩展为java.nio.channels.InterruptibleChannel 接口。 InterruptibleChannel接口描述了一个可以被异步closed and interrupted 的channel。接口重写了父接口close() 方法的header,表示了这个方法的channel约束的附加规定:任何在这个channel线程的I/O操作被阻塞都会收到AsynchronousCloseException (IOException 的派生)。
实现这个接口的channel可异步closeable:当一个线程带一个可中断channel上在I/O操作阻塞了,另一个线程可以调用channel的close()方法。这导致被阻塞的线程收到一个被抛出的 AsynchronousCloseException 实例。
实现这个接口的channel也是interruptible:当一个线程带一个可中断channel上在I/O操作阻塞了,另一个线程可以调用channel的interrupt()方法。这样会使channel关闭,被阻塞的线程收到ClosedByInterruptException 实例,并有它的nterrupt status set 。(当一个线程的 interrupt status 被设置,并且在channel上调用阻塞的I/O操作 ,channel被关闭,线程马上收到ClosedByInterruptException 实例;它的中断状态将保持设置 )
NIO的设计者当阻塞线程被打断选择关闭channel,因为他们不能找到一个方式去可靠处理打断的I/O操作,通过操作系统用相同的方式。保证确定性行为的唯一方式就是关闭channel。
技巧:你可以用类似 channel instanceof InterruptibleChannel 来确定 channel 是不是支持asynchronous closing and interruption。
除了channels,有2种方式获取channel:
java.nio.channels包提供了一个Channels utility类,它有2个方法从streams得到channel。下面每个方法,当channel是关闭的,stream也是关闭的,并且channel没有被 buffered。- WritableByteChannel newChannel(OutputStream outputStream) 对给定输出流返回一个writable byte channel
- ReadableByteChannel newChannel(InputStream inputStream) 对给定输入流返回一个 readable byte channel
- 很多 classic I/O 类被改造支持channel创建。例如,
java.io.RandomAccessFile声明了FileChannel getChannel() 方法得到一个 file channel ,java.net.Socket声明了 SocketChannel getChannel() 方法返回一个socket channel。
例子:
Listing 7-1. Copying Bytes from an Input Channel to an Output Channel
@Test
public void testUseChannelCopyFile() throws IOException {
try (ReadableByteChannel src = Channels.newChannel(System.in);
WritableByteChannel dest = Channels.newChannel(System.out)) {
copyAlt(src, dest);
}
}
static void copy(ReadableByteChannel src, WritableByteChannel dest) throws IOException {
ByteBuffer buffer = ByteBuffer.allocateDirect(2048);
while (src.read(buffer) != -1) {
buffer.flip();
dest.write(buffer);
buffer.compact();
}
buffer.flip();
while (buffer.hasRemaining()) {
dest.write(buffer);
}
}
static void copyAlt(ReadableByteChannel src, WritableByteChannel dest) throws IOException {
ByteBuffer buffer = ByteBuffer.allocateDirect(2048);
while (src.read(buffer) != -1) {
buffer.flip();
while (buffer.hasRemaining()) {
dest.write(buffer);
}
buffer.clear();
}
}
7-1展示了2种方法从标准输入流复制字节到标准输出流。在copy() 方法,目的是最小化操作系统I/O调用(通过write() 调用),尽管更多的数据最终作为compact() 方法调用的结果被复制。第二种方法,copyAlt() ,目标是消除数据复制,尽管可能会出现更多的操作系统I/O调用。
copy() and copyAlt() 方法首先分配direct byte buffer (上章最后一节),然后一个while循环持续从source channel读字节,直到end-of-input (read() returns -1 )。随着读取,buffer被 flipped 然后可以被排干。下面是方法的分歧点:
- copy() 方法的while循环只调用了write()一次。因为 write() 可能没完全排干buffer, compact() 被调用在下次读之前compact buffer。Compaction 确保没被写的buffer内容在下次读操作不会被覆盖。循环之后,flip buffer,准备排干任何剩下的内容,然后用 hasRemaining() and write() 完成buffer的排干。
- copyAlt() 方法while循环里还有个while循环,使用hasRemaining() and write() 持续排干buffer,直到buffer清空。然后clear() ,清空buffer然后在下次read调用可以被充满。
注意:认识到单个write() 方法调用不能输出buffer的全部内容是很重要的。类似地,单个的 read() 也可能不会完全充满buffer。
Channels in Depth
本节深入了解exploring scatter/gather I/O, file channels, socket channels, and pipes 。
Scatter/Gather I/O
Channel提供了跨多个buffer执行单一I/O操作的功能。也就是scatter/gather I/O(也叫vectored I/O)。
在写操作的context,几个buffer的内容按顺序被集中(排干),然后通过channel送到目的地。这些buffers不需要有等同的容量。在读操作的context,channel的内容按顺序被分散(填充)到多个buffer;每个buffer被填充到limit,直到channel空了或buffer全部空间都用了。
注意:现代操作系统提供了API支持vectored I/O 消除系统调用(或至少减少),因此提高性能。例如,Win32/Win64 APIs 提供了ReadFileScatter() and WriteFileGather() 。
Java提供java.nio.channels.ScatteringByteChannel 接口支持 scattering,以及java.nio.channels.GatheringByteChannel 接口来支持gathering 。
ScatteringByteChannel 提供以下方法:
- long read(ByteBuffer[] buffers, int offset, int length)
- long read(ByteBuffer[] buffers)
GatheringByteChannel 方法:
- long write(ByteBuffer[] buffers, int offset, int length)
- long write(ByteBuffer[] buffers)
例子:
Listing 7-2. Demonstrating Scatter/Gather
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.Channels;
import java.nio.channels.GatheringByteChannel;
import java.nio.channels.ScatteringByteChannel;
/**
* @author @Jasu
* @date 2018-08-03 10:47
*/
public class ChannelDemo1 {
public static void main(String[] args) throws IOException {
ScatteringByteChannel src;
FileInputStream fis = new FileInputStream("E:\\SpringSourceCode\\src\\main\\resources\\image.txt");
src = (ScatteringByteChannel) Channels.newChannel(fis);
ByteBuffer buffer1 = ByteBuffer.allocateDirect(5);
ByteBuffer buffer2 = ByteBuffer.allocateDirect(3);
ByteBuffer[] buffers = {buffer1, buffer2};
src.read(buffers);
buffer1.flip();
while (buffer1.hasRemaining()) {
System.out.println(buffer1.get());
}
System.out.println();
buffer2.flip();
while (buffer2.hasRemaining()) {
System.out.println(buffer2.get());
}
buffer1.rewind();
buffer2.rewind();
GatheringByteChannel dest;
FileOutputStream fos = new FileOutputStream("E:\\SpringSourceCode\\src\\main\\resources\\imageCopy.txt");
dest = (GatheringByteChannel) Channels.newChannel(fos);
buffers[0] = buffer2;
buffers[1] = buffer1;
dest.write(buffers);
}
}
通过实例化java.io.FileInputStream 并把这个实例传递给 ReadableByteChannel newChannel(InputStream inputStream) 获取了一个scattering byte channel 。返回的 ReadableByteChannel 被转换为ScatteringByteChannel 因为这个实例确实是 a file channel (discussed later ),它实现了ScatteringByteChannel 。
然后,创建了一对direct byte buffers,容量不同。然后这两个buffer被存在了数组,数组被传递到read(ByteBuffer[]) 来填充。
填充之后, flip buffer然后输出内容到标准输出。输出后,rewound buffer准备通过一个聚集操作排干buffer。
实例化java.io.FileOutputStream 传递给Channels的WritableByteChannel newChannel(OutputStream outputStream) 方法。返回的 WritableByteChannel 被强转为GatheringByteChannel 。
最后,分配这些buffers到buffer数组,和它们最开始的分配顺序相反,传递数组到write(ByteBuffer[]) 来排干。
原文件
12345abcdefg
输出
49
50
51
52
53
97
98
99
输出文件
abc12345
File Channels
之前提到, RandomAccessFile 声明了FileChannel getChannel() 返回一个file channel实例,描述了一个到文件的 open connection。其实FileInputStream and FileOutputStream也提供了相同的方法。与之不同,java.io.FileReader and java.io.FileWriter 没有提供活动file channel的方式。
警告:从FileInputStream’s getChannel() 返回的file channel是只读的,FileOutputStream’s getChannel() 返回的是只写的。…. ,否则异常。
抽象java.nio.channels.FileChannel 类描述了一个file channel。这个类实现了 InterruptibleChannel 接口,file channels是interruptible 。还实现了ByteChannel, GatheringByteChannel, and ScatteringByteChannel 接口,你可以写到它,从它读,在下面的文件执行scatter/gather I/O。然而,还有更多。
注意:不像buffers线程不安全,file channels是线程安全的。
一个file channel维护一个当前position到文件,FileChannel 让你得到和改变这个position。它还允许您请求将缓存的数据强制发送到磁盘,读写文件内容,得到channel下的文件的大小, truncate文件,尝试锁住全部文件或者仅一个文件区域,执行memory-mapped file I/O ,使用操作系统可能优化的方式直接传输数据到另一个channel。
Table 7-1. FileChannel Methods
| Method | Description |
|---|---|
| void force(boolean metadata) | 请求把所有对这个file channel的更新提交到存储设备。当这个方法返回,当文件处于本地存储设备的时候,所有基于channel对文件的修改都被提交。然而,当文件不在本地(例如 网络文件系统 ),应用不能确定修改是不是被提交了。(不保证其他地方定义的方法做出的更改会被提交。比如,通过 mapped byte buffer 的改变可能不会被提交) metadata值表明是否更新要包含文件的metadata(比如 modification time and last access time)。true可能会调用底层的write到操作系统,(如果操作系统在维护metadata,比如 last access time ),即使channel是以只读打开的。 抛异常 ClosedChannelException IOException |
| long position() | 返回file channel维护的以0为基准的当前file position。抛异常 ClosedChannelException IOException |
| FileChannel position(long newPosition) | 设置这个file channel的当前file position到newPosition。参数是从文件开头开始的字节计数。不能为负。但是可以超出当前文件size,如果超过了,read会返回end of file。写操作会成功,会在当前文件末尾和new position之间使用需求数量的(未定义)字节值填充字节。offset为负抛出 java.lang.IllegalArgumentException 。 ClosedChannelException , IOException |
| int read(ByteBuffer buffer) | 从file channel读取字节到给定buffer。读取字节的最大数量是调用方法时buffer剩余的字节数量。字节会从buffer的当前position开始复制到buffer。调用会阻塞如果其他线程也尝试从这个channel读。读完后,buffer的position会指到读取字节的末尾。buffer的limit没有变。返回实际读取的字节数,抛出和 ReadableByteChannel 一样的异常。 |
| int read(ByteBuffer dst, long position) | 和上面一样,但是从文件的position位置读,position是负抛出 IllegalArgumentException 。 |
| long size() | 返回file channel下的文件的(in bytes)size。 ClosedChannelException , IOException |
| FileChannel truncate(long size) | Truncate 这个file channel下的文件到size。任何超出 size 的字节都被从文件移除。当没有字节超出给定size,文件内容没被改变。当 current file position 超过了size,它被设置为size。 |
| int write(ByteBuffer buffer) | 从给定buffer写一个序列的字节到file channel。字节从channel的 current file position 开始写,除非是append模式,这个模式position会先提到文件末尾。file会增长(必要时)来容纳写入的字节,然后文件position随着被实际写入的字节更新。另外的表现得和 WritableByteChannel 的方法一样。方法返回实际写的字节数,抛出和 WritableByteChannel 一样的异常。 |
| int write(ByteBuffer src, long position) | 等同上个方法,从position开始写。 |
force(boolean) 方法确保所有更改写入本地文件系统上的文件。这个能力对例如事务的critical任务很关键,你要维护数据完整性和可靠恢复。然而,对远程文件系统没有保证。
传true到 force(boolean) 导致metadata也被同步到磁盘。因为metadata对文件恢复通常不关键,你可以传false,它是个额外的I/O操作。
FileChannel 对象支持current file position的概念,决定了下个要读或写入的data item的位置。 position() 返回当前position,position(long newPosition) 设置当前position到newPosition。
read() and write() 方法有两种形式。相对的形式,不带position参数,确保在方法调用后当前文件的position的更新。绝对的形式带有position参数,不会更新position。绝对形式的读写更效率因为不需要更新channel的state。
如果你尝试执行一个绝对的读文件末尾,参数是size()的返回值,会返回-1表明到达文件末尾。如果你尝试执行一个绝对的读文件末尾,参数是size()的返回值导致文件增长来容纳写入的字节。在先前文件末尾和第一个新写入字节之间的字节的值是系统特定的,可能形成一个hole。
一个hole发生在文件,当分配给文件的磁盘空间数量比文件size要小的时候。现代操作系统通常只对写入文件的数据分配空间。当数据被写入不连续的区域,holes出现。当文件被读,holes通常表现为zero-filled(补0)但是不占磁盘空间。
truncate(long size) 方法对减小文件size很有用。截断所有超出size的数据。当size比文件size大或者相等,文件不变。
Listing 7-3. Demonstrating a File Channel
public class ChannelDemo2 {
public static void main(String[] args) throws IOException {
RandomAccessFile raf = new RandomAccessFile("temp", "rw");
FileChannel fc = raf.getChannel();
long pos;
System.out.println(pos = fc.position());
System.out.println(fc.size());
String msg = "er34 we3e 34awe";
ByteBuffer buffer = ByteBuffer.allocateDirect(msg.length()*2);
buffer.asCharBuffer().put(msg);
fc.write(buffer);
fc.force(true);
System.out.println("————————————————————————————————————");
System.out.println(fc.position());
System.out.println(fc.size());
buffer.clear();
fc.position(pos);
fc.read(buffer);
buffer.flip();
while (buffer.hasRemaining()) {
System.out.print(buffer.getChar());
}
}
}
先创建了randomly-accessible File temp,然后从file得到一个file channel,输出position和size,都是0。
然后分配一个direct buffer,存放messgae,把buffer作为character buffer,调用put()保存buffer里的message,随后输出到文件。
调用force(true),托付底层操作系统把数据存到存储设备。
然后输出当前position和size,然后clear buffer,重置file position到message被写入前的位置(0),读取先前写的内容到buffer。然后flip buffer输出内容。
输出
Position = 0
size: 0
position: 46
size: 46
This is a test message.
再次运行
Position = 0
size: 46
position: 46
size: 46
This is a test message.
Locking Files
lock全部或部分文件的能力是重要的,但这个特性Java 1.4才有。这个能力让JVM进程阻止其他进程访问整个或者部分文件直到它结束了整个或者部分文件的操作。
虽然可以锁整个文件,但通常希望锁更小的一部分。例如,数据库管理系统可以锁更新中的单个行而不是锁整个表,因此读取请求可以被授予,从而提高吞吐量 。
和files有联系的locks也叫 file locks 。每个文件锁从文件中一个确切的字节位置开始,和一个指定的从这个位置开始的length(byte)。它们一起定义了由锁控制的区域。 文件锁让进程协调对文件中各个区域的访问。
有2种文件锁:exclusive (排它锁)和shared (共享锁)。一个exclusive lock 给单个writer进程访问一个文件区域;它阻止其他文件锁同时适用与该区域。一个shared lock 给出多个reader进程的其中之一访问相同的文件区域;它不阻止其他共享锁但是阻止排它锁同时适用此区域。
Exclusive and shared locks 普遍使用于一个文件主要是读偶尔更新的场景。一个需要读取文件的进程,需要一把shared lock,锁到整个文件或者期望的子区域。第二个需要读的进程也需要一把共享锁,锁到期望区域。两个进程都能读文件而互不干扰。
假设第三个进程想执行更新。要这么做,需要一个排它锁。这个进程会阻塞住,直到所有的和它的区域重叠的排他/共享锁被释放。一旦更新进程抢到排它锁(Once the exclusive lock was granted to the updater process ),任何请求共享锁的reader进程都会阻塞住,直到排它锁被释放。更新进程更新了文件,读进程也不会观测到不一致的数据。
对 file locking 还有几件事要注意 :
- 当操作系统不支持共享锁,一个共享锁的请求默默地提升到了排它锁。虽然正确性可以肯定,性能可能会受到影响。
- Locks是适用于per-file的基础上的。不适用于基于per-thread或者 per-channel。JVM上的2个线程,通过不同的channel,一个到相同区域的排它锁都可以授权访问。然而,如果是不同JVM的线程,第二个线程会阻塞。Locks最终由操作系统的文件系统进行公断,而且几乎总是在进程层面。不在线程层面公断。锁和file关联的,不和文件句柄或channel关联。
FileChannel声明4个方法得到共享/排它锁:
-
FileLock lock(): 得到这个file channel底下文件的排它锁。这个方便方法等同于执行
fileChannel.lock(0L, Long. MAX_VALUE, false);;返回一个
java.nio.channels.FileLock对象代表被锁区域。可抛出ClosedChannelException,NonWritableChannelException ,java.nio.channels.OverlappingFileLockException当任意一个和请求区域重叠锁已经被JVM持有,或另一个在这个方法被阻塞了并尝试锁住同文件的重叠区域;java.nio.channels.FileLockInterruptionException 当等待获取锁时被打断;AsynchronousCloseException 当等待获取锁时channel被关闭;IOException 等。 -
FileLock lock(long position, long size, boolean shared): 在这个channel的文件的区域加锁。
-
FileLock tryLock(): 尝试不阻塞地获得排他锁。等同于
fileChannel.tryLock(0L, Long.MAX_VALUE, false); 返回一个 FileLock ,代表被锁的区域或者null,当锁和其他操作系统进程重叠的时候。抛出 ClosedChannelException ,OverlappingFileLockException 当重叠区域的锁被JVM持有,或另一个在这个方法被阻塞了并尝试锁住同文件的重叠区域。 IOException -
FileLock tryLock(long position, long size, boolean shared):
lock()当要锁的区域已经被锁会block(除非都是共享锁)。对比之下,tryLock() 会迅速返回一个null值(当要和其他操作系统的进程的独占锁重叠)
都返回 FileLock 实例,封装了一个file的被锁的区域。 FileLock’s methods :
- FileChannel channel(): 当得到锁返回file channel,当file channel没得到锁返回null
- void close(): 调用release() 方法释放锁
- boolean isShared(): 是不是共享锁
- boolean isValid(): 是valid lock返回true,否则false。锁是valid的直到它被释放或者关联的file channel被关闭,无论哪个在前
- boolean overlaps(long position, long size): 返回是不是和被锁区域重叠
- long position(): 返回被锁区域的第一个字节的位置。返回值可能比文件size要大。
- void release(): 释放锁。如果锁是valid的,调用这个方法释放锁,把对象变成invalid。如果锁是,invalid ,调用这个方法无效。
- long size(): 返回文件锁的的length(字节)
- String toString(): 返回string描述range,type和validity 。
FileLock实例和一个FileChannel 实例关联,但是FileLock实例代表的file lock,和underlying file 关联而不是和file channel关联。不小心的话,当你用完后没释放锁可能会遇到冲突(甚至可能死锁)。要避免这些问题,你要采用一种模式比如下面的,确保lock总是被释放:
FileLock lock = fileChannel.lock();
try
{
// interact with the file channel
}
catch (IOException ioe)
{
// handle the exception
}
finally
{
lock.release();
}
例子:
Listing 7-4. Demonstrating File Locking
public class ChannelDemo3 {
final static int MAXQUERIES = 150000;
final static int MAXUPDATES = 150000;
final static int RECLEN = 16;
static ByteBuffer buffer = ByteBuffer.allocate(RECLEN);
static IntBuffer intBuffer = buffer.asIntBuffer();
static int counter = 1;
public static void main(String[] args) throws IOException {
boolean writer = false;
if (args.length != 0) {
writer = true;
RandomAccessFile raf = new RandomAccessFile("E:\\SpringSourceCode\\src\\main\\resources\\image.txt", (writer) ? "rw" : "r");
FileChannel fc = raf.getChannel();
if (writer) {
update(fc);
} else {
query(fc);
}
}
}
private static void query(FileChannel fc) throws IOException {
for (int i = 0; i < MAXQUERIES; i++) {
System.out.println("acquiring shared lock");
FileLock lock = fc.lock(0, RECLEN, true);
try {
buffer.clear();
fc.read(buffer, 0);
int a = intBuffer.get(0);
int b = intBuffer.get(1);
int c = intBuffer.get(2);
int d = intBuffer.get(3);
System.out.println("Reading" + a + ", " + b + ", " + c + ", " + d);
if (a * 2 != b || a * 3 != c || a * 4 != d) {
System.out.println("error");
return;
}
} finally {
lock.release();
}
}
}
private static void update(FileChannel fc) throws IOException {
for (int i = 0; i < MAXUPDATES; i++) {
System.out.println("acquiring exclusive lock");
FileLock lock = fc.lock(0, RECLEN, false);
try {
intBuffer.clear();
int a = counter;
int b = counter * 2;
int c = counter * 3;
int d = counter * 4;
System.out.println("Writing" + a + ", " + b + ", " + c + ", " + d);
intBuffer.put(a);
intBuffer.put(b);
intBuffer.put(c);
intBuffer.put(d);
counter++;
buffer.clear();
fc.write(buffer, 0);
} finally {
lock.release();
}
}
}
}
7-4描述了应用要么更新要么查询文件。因为file lock应用于进程级别而不是线程级别。你需要启动2个application。一个writer,一个reader。
ChannelDemo3 类先定义常数和变量。然后分配了一个byte buffer,得到int-based view buffer 。
main() 决定了是writer还是reader。
注意: ChannelDemo reader 进程越多,ChannelDemo writer 进程运行越慢。
Mapping Files into Memory
FileChannel声明了map() 方法可以在打开的文件的一个region和一个包装了这个region的java.nio.MappedByteBuffer实例之间创建一个 virtual memory mapping 。mapping机制提供了一个效率的访问文件的方式,因为没有执行I/O调用的时间消耗。
注意:Virtual memory 是一种memory,virtual addresses(也叫artificial addresses )代替(physical (RAM memory) addresses 。Check out Wikipedia’s “Virtual Memory” topic (http://en.wikipedia.org/wiki/ Virtual_memory) to learn more about virtual memory.
map() 方法有如下签名:
MappedByteBuffer map(FileChannel.MapMode mode, long position, long size)
mode参数定义映射类型,是 FileChannel.MapMode 的枚举类型:
- READ_ONLY: 任何更改的尝试抛出java.nio.ReadOnlyBufferException
- READ_WRITE: 对resulting buffer 的更改最终传播到文件;Changes 可能不对映射了同一文件的程序可见。
- PRIVATE: 对resulting buffer 的更改不会传播到文件,对其他映射同一文件的程序不可见。而是,更改会造成buffer修改部分的 private copies 会被创建。当buffer被垃圾回收,更改就丢失。
指定的映射模式受到调用着FileChannel对象访问权限的限制。例如,如果 file channel是只读打开的,请求READ_WRITE mode, map()抛出NonWritableChannelException 。类似地 NonReadableChannelException 。
技巧:调用MappedByteBuffer’s isReadOnly() 方法看你能不能更改 mapped file 。
position and size 参数定义开始位置和映射区域范围。不是负的。不能超过Integer.MAX_VALUE 。
指定的range不能超过文件size,因为文件会被变得更大来接收range。例如,如果你size为Integer.MAX_VALUE ,文件会超过2G。同时,对于只读映射, map() 可能抛出IOException 。
返回的MappedByteBuffer 对象表现得像一个memory-mapped buffer。但是内容保存在文件。在这个对象调用get() ,得到当前文件内容,甚至这些内如被外部程序更改的时候。类似地,如果你有写权限, 调用 put() 更新文件,更改对外部程序可用。
注意:因为mapped byte buffers 是direct byte buffers ,分配给它们的内存空间存在于JVM堆之外。
MappedByteBuffer buffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 50, 100);
这个例子映射一个子范围,从50到149。下面是全部文件
MappedByteBuffer buffer =
fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileChannel.size());
没有unmap() 方法。一旦映射建立了,它会在垃圾收集前一直存在(或者程序关闭)。因为a mapped byte buffer 没有连接到建立它的 file channel ,当file channel关闭mapping 不会销毁。
MappedByteBuffer 方法继承于java.nio.ByteBuffer 。有以下方法:
- MappedByteBuffer load(): 尝试加载全部映射文件到内存。这会使大文件访问更快因为 virtual memory manager 不需要在文件的部分被通过mapped buffer请求的时候加载文件的部分到内存(by reading from/writing to their locations )。load() 做了最大努力,可能不成功因为额外程序会使 virtual memory manager 移除文件部分的内容来为加载内容到物理空间的请求留出空间。另外,load() 是expensive time-wise ,他会使virtual memory manager 执行I/O;完成这个方法要花费时间
- boolean isLoaded(): 当全部映射文件内容被加载到内存返回true ;否则false。如果返回true,你可以用很少或没有的I/O操作来访问文件。如果返回false,buffer access 仍然可能很快,mapped content完全居于内存。考虑isLoaded() 为暗示映射字节缓冲区的状态。
- MappedByteBuffer force(): 让对mapped byte buffer 的更改写入储存。当使用mapped byte buffers 的时候,你应该用这个方法而不是file channel’s force() 方法,因为channel可能没意识到通过mapped byte buffer 做出的更改。在 READ_ONLY and PRIVATE mappings 这个方法没用。
Listing 7-5. Demonstrating File Mapping
public class ChannelDemo4 {
public static void main(String[] args) throws IOException {
if (args.length != 1) {
System.out.println("arg is 1");
return;
}
RandomAccessFile raf = new RandomAccessFile(args[0], "rw");
FileChannel fc = raf.getChannel();
long size = fc.size();
System.out.println("Size: " + size);
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, size);
while (mbb.remaining() > 0) {
System.out.print((char) mbb.get());
}
System.out.println();
System.out.println();
for (int i = 0; i < mbb.limit() / 2; i++) {
byte b1 = mbb.get(i);
byte b2 = mbb.get(mbb.limit() - i - 1);
mbb.put(i, b2);
mbb.put(mbb.limit() - i - 1, b1);
}
mbb.flip();
while (mbb.hasRemaining()) {
System.out.print((char) mbb.get());
}
fc.close();
}
}
输出:
Size: 67
Roses are red,
Violets are blue,
Sugar is sweet,
And so are you!
!uoy era os dnA
,teews si raguS
,eulb era steloiV
,der era sesoR
Transferring Bytes Among Channels
为了优化执行批量传输的常规做法, FileChannel 添加了2个方法避免了对中间buffers的需求:
- long transferFrom(ReadableByteChannel src, long position, long count)
- long transferTo(long position, long count, WritableByteChannel target)
transferFrom(ReadableByteChannel, long, long) ,从给定可读字节channel传输字节到channels file。src source channel, position 指定文件传输到文件的开始位置,count 指定了要传输的非负最大值。
返回实际被传输的字节数。
transferTo(long, long, WritableByteChannel) 从channel的file传输字节到给定可写channel。
当使用transferTo() ,position plus count 大于file size时,传输在文件末停止。 transferFrom() ,当src是file,到达文件名会停止。
Listing 7-6. Demonstrating Channel Transfer
import java.io.FileInputStream;
import java.io.IOException;
import java.nio.channels.Channels;
import java.nio.channels.FileChannel;
import java.nio.channels.WritableByteChannel;
/**
* @author @Jasu
* @date 2018-08-08 15:07
*/
public class ChannelDemo5 {
public static void main(String[] args) throws IOException {
if (args.length != 2) {
System.err.println("usage: java ChannelDemo filespec");
return;
}
try (FileInputStream fis = new FileInputStream(args[0])) {
FileChannel inChannel = fis.getChannel();
WritableByteChannel outChannel = Channels.newChannel(System.out);
inChannel.transferTo(0, inChannel.size(), outChannel);
}
}
}
Socket Channels
先前提到, Socket 声明了 SocketChannel getChannel() 方法返回socket channel 实例,描述了一个到socket的 open connection 。不像sockets,socket channels是selectable 的,可以 function in nonblocking mode。这些能力提高大型应用程序的可伸缩性和灵活性 (例如web servers)。
Socket channels 由java.nio.channels 的抽象 ServerSocketChannel, SocketChannel, and DatagramChannel 类描述。每个类最终继承java.nio.channels. SelectableChannel 和实现 InterruptibleChannel ,这使得ServerSocketChannel, SocketChannel, and DatagramChannel的实例selectable and interruptible 。SocketChannel and DatagramChannel 实现了ByteChannel, GatheringByteChannel, and ScatteringByteChannel 接口,你可以在底下的sockets上读取,写到,执行scatter/gather I/O 。
注意:不像buffers是线程不安全的,server socket channels, socket channels, and datagram channels 是线程安全的。
每个 ServerSocketChannel, SocketChannel, and DatagramChannel 实例从java.net.ServerSocket , Socket, or java.net.DatagramSocket 创建一个对等的socket对象。每个类都被改造为能使用channel。你可以调用ServerSocketChannel’s, SocketChannel’s, or DatagramChannel’s socket() 方法获取对等的socket对象。
注意:当在从socket()返回的 socket instance 上调用getChannel() 方法,返回关联的 socket channel。然而在从ServerSocket, Socket, or DatagramSocket 实例化返回的socket上调用getChannel() 返回null。
Understanding Nonblocking Mode
Java’s socket类创建的sockets的阻塞性质是对Java面向网络应用扩展性的严重限制。例如, ServerSocket类的Socket accept() 方法,在传入的连接到来之前会阻塞住,在到来时创建和返回Socket实例让server和客户端交流。如果这个方法不阻塞,扩展性会改善因为server可以去完成其他有用的工作而不是必须等着。
abstract SelectableChannel类是ServerSocketChannel, SocketChannel, and DatagramChannel的共同祖先。SelectableChannel 不仅让socket channel在一个selector context 工作,也让socket channels 选择以阻塞/非阻塞模式工作,一个线程可以不阻塞地在输入不可用时检查输入或在output buffer 为空时发送输出。
注意:SelectableChannel 将与selectors相关的功能与非阻塞模式相关联,因为非阻塞模式最常用于结合selector-based multiplexing 。
SelectableChannel 提供以下方法 enable blocking or nonblocking ,决定channel是不是阻塞的,和得到 blocking lock:
- SelectableChannel configureBlocking(boolean block): 指定调用 selectable channel的blocking status。true为阻塞。返回 selectable channel 或者抛出异常:ClosedChannelException ;java.net.channels.IllegalBlockingModeException 当block是true,但channel已经被注册了一个或多个selectors, IOException 。
- boolean isBlocking(): 新建的channel默认是阻塞的。
- Object blockingLock(): 返回configureBlocking() 使用的加锁对象。返回对象在adaptors 的实现很有用,需要当前阻塞模式的值在一个短暂的时间不改变。
设置或重置一个selectable channel的阻塞状态是琐碎的。使非阻塞可用,传false到configureBlocking() ,例如:
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false); // enable nonblocking mode
虽然非阻塞 sockets通常用于 server-oriented 应用,它们在客户端也很有用。例如,一个GUI-based应用可以利用非阻塞sockets保持用户接口响应,当和多个服务器同时交流的时候。
blockingLock() 方法让你阻止其他线程改变socket channel的阻塞/非阻塞状态。这个方法返回的对象是 channel implementation使用在改变状态时用于加锁的对象。只有持有这个对象锁的线程可以改变status,并且这个锁通常由synchronized 关键字获得。考虑下面的例子:
Exploring Server Socket Channels
ServerSocketChannel是3个 socket channel类中最简单的。方法包含以下方法:
- static ServerSocketChannel open(): 尝试打开一个 server-socket channel ,最初不绑定;它必须在连接被接受前通过它的其中一个peer socket’s bind() methods 来指定地址。IOException ,channel打不开
- ServerSocket socket(): 返回和这个 server socket channel 关联的 peer ServerSocket 实例
- SocketChannel accept(): 接收对这个channel’s socket的连接。如果这个channel是非阻塞的,当没有等待的连接会立即返回null,或者返回代表了连接的 socket channel。如果阻塞的,accept() 在直到一个新连接可用或者发生I/O错误前是完全阻塞的。accept() 返回的socket channel无论 server socket channel是阻塞还是非阻塞都是阻塞的。抛出ClosedChannelException ;AsynchronousCloseException ;java.nio.channels. NotYetBoundException 。
一个server socket channel 在 TCP/IP stream protocol表现为一个server 。你使用 server socket channels 来监听传入的客户端的连接。
调用static open() 工厂方法创建一个新的server socket channel 。如果一切顺利, open() 返回一个ServerSocketChannel 实例,和一个未绑定的 peer ServerSocket 对象关联。你可以调用 socket()得到这个对象,然后调用 ServerSocket’s bind() 方法绑定server socket (根本上是 server socket channel )到一个指定地址。
然后你调用ServerSocketChannel’s accept() 方法接受传入的连接。取决于你配置server socket channel为阻塞/非阻塞,方法要么是立刻返回null或者一个到传入连接的socket channel,要么在有传入连接之前阻塞住。
注意:你也可以选择在socket() 返回的 peer ServerSocket 对象上调用 accept() 。然而,这个 accept() 总是阻塞的。
例子:
Listing 7-7. Demonstrating ServerSocketChannel
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
/**
* @author @Jasu
* @date 2018-08-08 17:03
*/
public class ChannelServer {
public static void main(String[] args) throws IOException {
System.out.println("starting server");
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress(9999));
ssc.configureBlocking(false);
String msg = "Local Address: " + ssc.socket().getLocalSocketAddress();
System.out.println(msg);
ByteBuffer buffer = ByteBuffer.wrap(msg.getBytes());
while (true) {
System.out.print(".");
SocketChannel sc = ssc.accept();
if (sc != null) {
System.out.println();
System.out.println("Receive connection from " + sc.socket().getRemoteSocketAddress());
buffer.rewind();
sc.write(buffer);
sc.close();
} else {
try{
Thread.sleep(100);
} catch (InterruptedException e) {
//shouldn't happen
assert false;
}
}
}
}
}
buffer rewind 然后内容被写到 socket channel 。
Exploring Socket Channels
SocketChannel 是这3个 socket channel 类最常用的,建模一个面向连接的流协议 (就像TCP/IP )。这个类有以下方法:
- static SocketChannel open(): 尝试打开一个socket channel。打不开抛出IOException 。
- static SocketChannel open(InetSocketAddress remoteAddr): 尝试open a socket 并把他连接到remoteAddr。这个方便方法是调用open() ,在 resulting socket channel 上调用 connect() (传入地址),然后返回channel 。AsynchronousCloseException ;ClosedByInterruptException ;java.nio.channels.UnresolvedAddressException ;java.nio.channels.UnsupportedAddressTypeException ;IOException
- Socket socket(): 返回关联这个 socket channel 的peer Socket 。
- boolean connect(SocketAddress remoteAddr): 尝试把这个 socket channel的socket对象连接到remote address。如果这个channel是非阻塞的,这种方法的调用启动一个非阻塞连接操作。如果连接马上建立,就像在本地连接中发生的一样 ,方法返回true。否则,方法返回false,并且连接操作必须随后被完成,通过反复调用 finishConnect() 直到这个返回返回true。java.nio.channels.AlreadyConnectedException ;java.nio.channels. ConnectionPendingException ;ClosedChannelException ;AsynchronousCloseException ;ClosedByInterruptException ;UnresolvedAddressException ;UnsupportedAddressTypeException ;IOException 。
- boolean isConnectionPending(): 当一个连接操作正在等待完成返回true;否则返回false。
- boolean finishConnect(): 完成一个连接socket channel的过程。当 socket channel被完全连接返回true;否则false。java.nio.channels. NoConnectionPendingException ;ClosedChannelException ; AsynchronousCloseException ; ClosedByInterruptException ;IOException
- boolean isConnected(): 当channel’s socket 是open的且连接好的返回true;否则false。
A socket channel 表现如同TCP/IP stream protocol 的客户端。使用socket channels启动连接监听服务器。
调用任意open() 方法创建一个new socket channel。在幕后,创建了peer socket对象。 调用SocketChannel’s socket() 方法返回这个 peer object 。你也可以调用peer Socket object 对象上的getChannel() 返回original socket channel 。
从无参 open() 方法得到的socket channel 没有被连接。尝试从这个socket channel读写抛出java.nio.channels.NotYetConnectedException 。在socket channel或者peer socket上调用 connect() 来连接socket。
在socket channel被连接后,直到关闭都保持连接。调用SocketChannel’s boolean isConnected() 看是否连接了。
带有一个 java.net.InetSocketAddress 参数的open()让你连接到让你连接到另一个在指定的远程地址的主机,如下:
SocketChannel sc = SocketChannel.open(new InetSocketAddress("localhost", 9999));
等同于
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 9999);
当在一个阻塞的socket channel,通过peer Socket object或者通过SocketChannel’s connect()/second open() 方法,调用connect() 的线程在 socket channel被连接之前会阻塞。然而,当socket channel 不是阻塞的,connect() 马上返回,通常是false代表连接没建立(虽然也可能对 local loopback connection返回true),因为在 socket channel 执行I/O之前,必须建立连接,你需要重复调用finishConnect() 直到返回true。
Listing 7-8. Demonstrating SocketChannel
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
/**
* @author @Jasu
* @date 2018-08-09 11:47
*/
public class ChannelClient {
public static void main(String[] args) throws IOException {
SocketChannel sc = SocketChannel.open();
sc.configureBlocking(false);
InetSocketAddress addr = new InetSocketAddress("localhost", 9999);
sc.connect(addr);
while (!sc.finishConnect()) {
System.out.println("waiting for connecting");
}
ByteBuffer buffer = ByteBuffer.allocate(200);
while (sc.read(buffer) >= 0) {
buffer.flip();
while (buffer.hasRemaining()) {
System.out.println((char) buffer.get());
buffer.clear();
}
}
sc.close();
}
}
server
starting server
Local Address: /0:0:0:0:0:0:0:0:9999
..................................................................................................
Receive connection from /127.0.0.1:52506
..................................
Receive connection from /127.0.0.1:52512
..........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
Receive connection from /127.0.0.1:52523
.............................................................................
Receive connection from /127.0.0.1:52530
..........................................
Receive connection from /127.0.0.1:52537
...............................................................................................................................................
client
Local Address: /0:0:0:0:0:0:0:0:9999
Exploring Datagram Channels
DatagramChannel 建模connectionless packet-oriented protocol (such as UDP/IP )。这个类有以下方法:
- static DatagramChannel open(): 尝试打开一个datagram channel ,打不开抛出IOException 。
- DatagramSocket socket(): 返回和这个 datagram channel 关联的peer DatagramSocket 实例。
- DatagramChannel connect(SocketAddress remoteAddr): 尝试把这个datagram channel的 socket object 连接到remoteAddr。channel’s socket 被配置只从remoteAddr接收datagrams或者发送到remoteAddr。一旦连接,不能从任何另外地址接收或发送到另外地址。一个datagram socket 保存连接直到显示地断开或关闭。方法如果成功返回datagram channel。ClosedChannelException ;AsynchronousCloseException ;ClosedByInterruptException ;IOException ;
- boolean isConnected(): 当这个channel’s socket 是打开且连接状态返回true;否则false。
- DatagramChannel disconnect(): 从这个channel’s socket 断开。这个方法可以在任何时刻调用并且不会影响正在执行的读写操作。当没 socket没连接或者channel关闭了,方法无效。
- SocketAddress receive(ByteBuffer buffer): 通过channel接收datagram。如果datagram 马上可用,或者channel是阻塞的datagram将可用,datagram被复制到给定byte buffer 并且返回它的source address。如果channel是非阻塞的并且datagram不立即可用,方法立刻返回null。datagram 被传输到给定byte buffer ,从当前position开始,就像一个常规的读操作。如果buffer里剩下的字节比需要保持datagram的字节少,余下的datagram 默默被丢弃。当channel不阻塞且没有datagram可用,返回 datagram’s source address or null 。ClosedChannelException ;AsynchronousCloseException ;ClosedByInterruptException ;IOException
- int send(ByteBuffer buffer, SocketAddress destAddr): 通过channel发送datagram 。如果channel是非阻塞的并且在underlying output buffer 有足够空间,或者channel是阻塞的足够空间可用,在given buffer里剩余的bytes 作为 a single datagram 被传输到 given destination address 。datagram 从 byte buffer 被传输,就像一个常规写操作。返回被发送的字节数量,它是source buffer 里剩余的字节数,当channel 是非阻塞的,如果对于datagram的underlying output buffer 的空间不足,会返回0。ClosedChannelException ;AsynchronousCloseException ;ClosedByInterruptException ;IOException 。
另外,有几个read() and write() 你可能喜欢用。不像send() and receive() 是不需要datagram channel 被连接的, read() and write() 需要连接。
调用static open() 获得DatagramChannel instance 。new datagram channel 和 peer DatagramSocket object 关联,你可以调用DatagramChannel’s socket() 方法获得这个对象。
datagram channel 可以表现为client (the sender) 也可以是server (the listener) 。做为listener ,datagram channel 必须绑定到一个port 和一个optional address。得到DatagramSocket object,调用bind() ,如下:
DatagramChannel dc = DatagramChannel.open();
DatagramSocket ds = dc.socket();
ds.bind(new InetSocketAddress(9999)); // bind to port 9999
receive() 方法复制进来的 datagram’s data payload 到参数里的 byte buffer ,返回的socket address 是datagram’s source address 。如果channel是阻塞的,receive() 在packet到来或者一些事件导致异常之前sleep。如果是非阻塞,当datagram不可用返回null。如果datagram 比buffer大,多余的字节被默默移除。
send() 方法发送 given byte buffer’s content ,从buffer的当前position开始到buffer的limit,发送到参数指定的destination address/ port number 。如果datagram channel是阻塞的,send() 会在datagram is queued for sending 或者事件导致异常抛出之前sleep。如果channel不是阻塞的,返回2个值的一个:被发送buffer content的 entire length 或者是0表示buffer content 没被发送(当传输前没有空间保存整个datagram,什么也不发送 )
注意:Datagram protocols 是不可靠的。首先,不保证交付。因此,send() 返回的非零值不代表datagram到达了目的地。同时,underlying network 可能将数据报片段分割成多个小数据包 。当datagram是分割的,很可能一个或者多个数据包没有到达目的地。因为receiver不能组装所有的包,整个datagram 被丢弃。因此, data payloads 应该被限制在最高几百字节。
stock ticker 例子,你需要用datagram channel对应给定公司提供最近的 stock prices 。客户端会提交company’s stock symbol (such as MSFT for Microsoft )作为datagram payload ,接收datagram响应的payload 提供了requested stock prices。因为需要latest information ,当response datagram没来到,会重新请求。
Listing 7-9. Using DatagramChannel to Implement a Stock Ticker Server
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.SocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.DatagramChannel;
/**
* @author @Jasu
* @date 2018-08-09 16:14
*/
public class StockTickerServer {
final static int PORT = 9999;
public static void main(String[] args) throws IOException {
System.out.println("server starting and listening on port " + PORT + " for incoming requests...");
DatagramChannel dcServer = DatagramChannel.open();
dcServer.socket().bind(new InetSocketAddress(PORT));
ByteBuffer symbol = ByteBuffer.allocate(4);
ByteBuffer payload = ByteBuffer.allocate(16);
while (true) {
payload.clear();
symbol.clear();
SocketAddress sa = dcServer.receive(symbol);
if (sa == null) {
return;
}
System.out.println("Received request from " + sa);
String stockSymbol = new String(symbol.array(), 0, 4);
System.out.println("Symbol: " + stockSymbol);
if (stockSymbol.toUpperCase().equals("MSFT")) {
payload.putFloat(0, 37.40f); // open share price
payload.putFloat(4, 37.22f); // low share price
payload.putFloat(8, 37.48f); // high share price
payload.putFloat(12, 37.41f); // close share price
} else {
payload.putFloat(0, 0.0f);
payload.putFloat(4, 0.0f);
payload.putFloat(8, 0.0f);
payload.putFloat(12, 0.0f);
}
dcServer.send(payload, sa);
}
}
}
使用four-byte floating-point values代表price。
注意:为了方便,用 floating-point表示,不是个好做法,应该使用java.math.BigDecimal 。也不要把price嵌入到源码 ,而是从外部的 server or database 获取。
tests sa for null 的if对应用是不必要的,但是可以用于配置非阻塞模式。
在输出一个识别请求的消息后,判断是不是MSTF。最后发送payload datagram payload 继续循环。
Client:
Listing 7-10. Using DatagramChannel to Implement a Stock Ticker Client
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.SocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.DatagramChannel;
/**
* @author @Jasu
* @date 2018-08-09 16:14
*/
public class StockTickerServer {
final static int PORT = 9999;
public static void main(String[] args) throws IOException {
System.out.println("server starting and listening on port " + PORT + " for incoming requests...");
DatagramChannel dcServer = DatagramChannel.open();
dcServer.socket().bind(new InetSocketAddress(PORT));
ByteBuffer symbol = ByteBuffer.allocate(4);
ByteBuffer payload = ByteBuffer.allocate(16);
while (true) {
payload.clear();
symbol.clear();
SocketAddress sa = dcServer.receive(symbol);
if (sa == null) {
return;
}
System.out.println("Received request from " + sa);
String stockSymbol = new String(symbol.array(), 0, 4);
System.out.println("Symbol: " + stockSymbol);
if (stockSymbol.toUpperCase().equals("MSFT")) {
payload.putFloat(0, 37.40f); // open share price
payload.putFloat(4, 37.22f); // low share price
payload.putFloat(8, 37.48f); // high share price
payload.putFloat(12, 37.41f); // close share price
} else {
payload.putFloat(0, 0.0f);
payload.putFloat(4, 0.0f);
payload.putFloat(8, 0.0f);
payload.putFloat(12, 0.0f);
}
dcServer.send(payload, sa);
}
}
}
客户端是直接发送的。
Pipes
java.nio.channels 包有一个Pipe 类。Pipe描述了一对channels,实现了unidirectional pipe (单向管道),是在两个实体间单方向传递数据的管道,比如两个file channels 或两个socket channels 之间。Pipe类似于java.io.PipedInputStream and java.io.PipedOutputStream 类———see Chapter 4 。
Pipe内嵌声明了 SourceChannel and SinkChannel 类分别充当readable and writable byte channels 。 Pipe 也声明以下方法:
- static Pipe open(): open一个new pipe
- SourceChannel source(): 返回pipe的source channel (数据来源)
- SinkChannel sink(): 返回pipe的sink channel(数据被发送到的地方)
Listing 7-11. Producing and Consuming Bytes via a Pipe
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.Pipe;
import java.nio.channels.ReadableByteChannel;
import java.nio.channels.WritableByteChannel;
/**
* @author @Jasu
* @date 2018-08-09 17:36
*/
public class ChannelDemo6 {
final static int BUFSIZE = 10;
final static int LIMIT = 3;
public static void main(String[] args) throws IOException {
final Pipe pipe = Pipe.open();
new Thread(() -> {
WritableByteChannel src = pipe.sink();
ByteBuffer buffer = ByteBuffer.allocate(BUFSIZE);
for (int i = 0; i < LIMIT; i++) {
buffer.clear();
for (int j = 0; j < BUFSIZE; j++) {
buffer.put((byte) (Math.random() * 256));
}
buffer.flip();
try {
while (src.write(buffer) > 0) ;
} catch (IOException ioe) {
System.out.println(ioe.getMessage());
}
}
try {
src.close();
} catch (IOException e) {
e.printStackTrace();
}
}, "sender").start();
new Thread(() -> {
ReadableByteChannel dst = pipe.source();
ByteBuffer buffer = ByteBuffer.allocate(BUFSIZE);
try {
while (dst.read(buffer) >= 0) {
buffer.flip();
while (buffer.remaining() > 0) {
System.out.println(buffer.get() & 255);
}
buffer.clear();
}
} catch (IOException e) {
System.out.println(e.getMessage());
}
}, "receiver").start();
}
}
sender task调用Pipe’s sink() 得到writable byte channel 。然后分配用于储存要被写的内容的byte buffer。然后一对for循环用于发送byte-oriented data到writable byte channel。每一个外部for循环迭代先clear buffer,准备用于内循环填充buffer。然后被flipped准备排干,通过传递buffer到 writable byte channel’s write() 方法。因为单次方法调用可能不会排干全部buffer,write() 在循环里调用直到返回0,0意味着没有更多的内容可以写。 channel然后被关闭,所以receiver task 从channel 读的时候不会阻塞,它希望获得更多的数据 。
receiver task调用 Pipe’s source() 得到readable byte channel ,然后分配buffer存储read content。
然后是while循环持续从channel读直到read() 返回-1,表明channel到达了流的end。如果sender’s run() 方法没有关闭channel,这个方法不会到达流的end。此时,buffer被flipped用于排干。然后通过打印 byte values 到标准输出流排干了buffer。每个字节bitwise ANDed with 255 防止输出负值。根本上,get() 返回8-bit integer value ,在System.out.println()时转换为 32-bit integer 。这个转换应用了符号扩展( sign extension ),这意味着一些字节值变成负的32-bit integers 。但是bitwise ANDing the byte value with 255 ,保证不会转化为负值。最后buffer被clear用于填充,循环继续。
输出
245
56
137
166
52
183
252
166
246
124
163
11
159
68
203
118
157
70
54
148
186
17
12
203
75
223
224
175
205
47
EXERCISES
The following exercises are designed to test your understanding of Chapter 7’s content:
1. What is a channel?
2. What capabilities does the Channel interface provide?
3. Identify the three interfaces that directly extend Channel.
4. True or false: A channel that implements InterruptibleChannel is
asynchronously closeable.
5. Identify the two ways to obtain a channel.
6. Define scatter/gather I/O.
7. What interfaces are provided for achieving scatter/gather I/O?
8. Define file channel.
9. True or false: File channels don’t support scatter/gather I/O.
10. Define exclusive lock and shared lock.
11. What is the fundamental difference between FileChannel’s lock()
and tryLock() methods?
12. What does the FileLock lock() method do when either a lock
is already held that overlaps this lock request or another thread is
waiting to acquire a lock that will overlap with this request?
13. Specify the pattern that you should adopt to ensure that an acquired
file lock is always released.
14. What method does FileChannel provide for mapping a region of a
file into memory?
15. Identify the three file-mapping modes.
16. Which file-mapping mode corresponds to copy-on-write?
17. Identify the FileChannel methods that optimize the common
practice of performing bulk transfers.
18. True or false: Socket channels are selectable and can function in
nonblocking mode.
19. Identify the three classes that describe socket channels.
20. True or false: Datagram channels are not thread-safe.
21. Why do socket channels support nonblocking mode?
22. How would you obtain a socket channel’s associated socket?
23. How do you obtain a server socket channel?
24. Create a Copy application that uses the ByteBuffer and
FileChannel classes in partnership with FileInputStream and
FileOutputStream to copy a source file to a destination file.
Summary
Channels partner with buffers to achieve high-performance I/O. A channel is an object that represents an open connection to a hardware device, a file, a network socket, an application component, or another entity that’s capable of performing write, read, and other I/O operations. Channels efficiently transfer data between byte buffers and operating system-based I/O service sources or destinations.
Java supports channels by providing the Channel interface, its WritableByteChannel and ReadableByteChannel subinterfaces, the Channels class, and other types in the java.nio.channels package. While exploring this package, you learned about scatter/gather I/O, file channels (in terms of the FileChannel class with emphasis on its file locking, memory-mapped file I/O, and byte-transfer capabilities), socket channels, and pipes.
Chapter 8 Selectors
I/O要么是block-oriented (such as file I/O)要么是stream-oriented (such as network I/O)。Streams通常比block devices (such as fixed disks) 慢,并且读写操作通常造成调用线程在输入可用或输出被完全写出之前阻塞住。为了弥补,现代操作系统让streams以非阻塞模式操作,这让一个线程不阻塞地读写数据成为可能。操作完全成功或表明部分成功。不管怎样,线程可以去执行其他有用的工作而不是等待。
Nonblocking mode doesn’t let an application determine if it can perform an operation without actually performing the operation。例如,当一个非阻塞read线程成功,应用知道读操作是可能的也知道读了一些必须管理的数据。这个duality防止你把检查读流从 data-processing代码分离,不会让你的代码明显复杂。
非阻塞模式充当执行 readiness selection 的基础,这将把工作转交给操作系统,在不实际执行操作的情况下checking for I/O stream readiness来执行写、读和其他操作。 操作系统被指示观测一组streams,并返回一些迹象表明哪些流准备好执行一个特定操作(such as read )或一些特定操作(such as accept and read )。这个能力让一个线程multiplex(多路复用)一个潜在的巨大数量的active streams,通过使用操作系统提供的 readiness information。用这种方式,network servers 可以处理很大数量的网络连接;他们极大地扩展了。
注意:现代操作系统让readiness selection对应用可用,通过例如 POSIX select() 的系统调用。
Selectors 让你在Java context得到readiness selection。
Selector Fundamentals
一个selector对象是abstract java.nio. channels.Selector类的子类创建的对象。selector维护一个channels的set ,检查来确定那个channel准备好了用于reading, writing, completing a connection sequence, accepting another connection, or some combination of these tasks。实际的工作是委托给操作系统的,通过POSIX select()或类似系统调用。
注意:检查一个channel的能力在一些东西还没就绪的时候(such as bytes are not available for reading )是不需要等待的,同时也不用必须执行操作虽然检查是可伸缩性的关键。一个single thread可以管理很大数目的channels,这减少了代码复杂性和潜在的线程issues。
Selectors是使用 selectable channels 的,是最终继承java.nio.channels.SelectableChannel的类,描述了一个channel可以被selector multiplexed。Socket channels, server socket channels, datagram channels, and pipe source/sink channels 是 selectable channels ,因为java.nio.channels. SocketChannel, java.nio.channels.ServerSocketChannel, java.nio. channels.DatagramChannel, java.nio.channels.Pipe.SinkChannel, and java.nio.channels.Pipe.SourceChannel 由SelectableChannel派生。不同的是,file channels不是 selectable channels ,因为java.nio. channels.FileChannel 在祖先不包含SelectableChannel 。
一个或多个之前创建的selectable channels是用一个selector注册的。每个注册返回一个abstract SelectionKey类的子类的实例, 它是个token代表了channel和selector之间的关系。key跟踪两个操作的set:interest set and ready set 。 interest set 识别 在下一次调用选择器的选择方法时,要对其进行测试的operation categories。 ready set 识别 key’s channel 被发现且准备好的 operation categories。当 selection method 被调用, 通过检查所有selector注册的channels 来更新selector的相关keys。应用然后可以获得一个keys的set ,它的channels已经被找到并且iterate over these keys to service each channel that has become ready 。
注意:一个selectable channel可以不止一个selector 注册。它不知道它当前注册的selectors。
要用selectors ,要先建一个。调用 Selector’s Selector open() 方法,成功返回Selector 实例
Selector selector = Selector.open();
你可以在创建selector 之前或之后创建 selectable channels 。然而,在用selector 注册channel前,你需要保证每个channel是非阻塞模式。注册方法:
SelectionKey register(Selector sel, int ops)
SelectionKey register(Selector sel, int ops,
Object att)
每个方法需要你传入一个先前创建的selector,一个bitwise ORed combination of the following SelectionKey int-based constants ,它表示interest set :
- OP_ACCEPT: Operation-set bit for socket-accept operations.
- OP_CONNECT: Operation-set bit for socket-connect operations
- OP_READ: Operation-set bit for read operations
- OP_WRITE: Operation-set bit for write operations.
第二个方法也让你传入一个任意的 java.lang.Object 或者一个子类实例(或者null)到att。 non-null object 被称作attachment ,是一个意识到given channel 或附加additional information 到channel的方便方式。它保存在这个方法返回的SelectionKey实例。
一旦成功,每个方法返回SelectionKey 实例,把selectable channel 和selector联系起来。一旦失败,抛出异常。例如, java.nio.channels.ClosedChannelException ;java.nio.channels. IllegalBlockingModeException 。
以下代码扩充了上面的代码片段,通过配置先前创建的channel为非阻塞模式,用selector注册channel。selection methods test the channel for accept, read, and write readiness :
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, SelectionKey.OP_ACCEPT |
SelectionKey.OP_READ |
SelectionKey.OP_WRITE);
此时,应用典型地进入一个无限循环,在这里完成下面工作:
- 执行selection operation
- 获得选定的keys,然后在选定的keys上执行迭代器。
- 遍历这些键并执行channel 操作
一个 selection operation 是调用Selector’s selection的 methods 之一完成的。例如, int select() 执行一个阻塞 selection operation 。在一个channel被选择之前,或者这个channel的wakeup() 被调用前,或者在当前线程被打断前(无论哪个在前)都不会返回。
注意:Selector 也声明了int select(long timeout) 方法,在一个channel被选择之前,或者这个channel的wakeup() 被调用前,或者在当前线程被打断前,或者超出timeout之前(无论哪个在前)都不会返回。另外,Selector声明了int selectNow() ,是select()的非阻塞模式。
select() 方法返回自从上次调用变为就绪的channels 。例如,如果你调用 select() ,他返回1因为1个channel变得就绪,如果再次调用select() 并且第二个channel也变得就绪了,select() 会再次返回1。如果你还没有为第一个现成的channel提供服务, 你现在有2个channel要服务。然而,在两次 select() 调用之间,只有一个channel 变得就绪。
selected keys 的set (the ready set)调用Selector’s Set selectedKeys() 方法获取。调用set的iterator() 获取迭代器。
最后,应用迭代keys。每次遍历返回一个SelectionKey 实例。一些SelectionKey’s boolean isAcceptable(), boolean isConnectable(), boolean isReadable(), and boolean isWritable() 的组合被调用来决定key 是否表明channel准备好accept a connection, is finished connecting, is readable, or is writable 。
注意:前面提到的方法提供了一个便利方法来指定表达式,比如key.readyOps() & OP_READ != 0 。SelectionKey’s int readyOps() 方法返回key的 ready set 。返回的set只包含对key的channel的 有效operation bits 。例如,不会返回一个operation bit 表明只读的channel准备好写了。注意每个selectable channel 也声明了int validOps() 方法,返回对channel有效的operations 的bitwise ORed set 。
一旦应用决定channel准备好执行一个特定操作,它可以调用SelectionKey’s SelectableChannel channel() 方法得到channel,然后在channel执行工作。
注意:SelectionKey 也声明了Selector selector() 方法,返回key 为之创建的selector 。
当你完成channel的处理,你必须从keys 的set移除key;selector 不做这个工作。下次channel准备好的时候,Selector 会添加key到selected key set 。
以下代码为以上任务:
import java.io.IOException;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
/**
* @author @Jasu
* @date 2018-08-10 14:45
*/
public class SelectorDemo {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
//ServerSocketChannel scChannel = ServerSocketChannel.open();
//scChannel.configureBlocking(false);
while (true) {
int numReadyChannels = selector.select();
if (numReadyChannels == 0) {
continue;
}
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// A connection was accepted by a ServerSocketChannel
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel client = server.accept();
if (client == null) { // in case accept() returns null
continue;
}
client.configureBlocking(false);// must be nonblocking
// Register socket channel with selector for read operations.
client.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
// A socket channel is ready for reading.
SocketChannel client = (SocketChannel) key.channel();
// Perform work on the socket channel.
} else if (key.isWritable()) {
// A socket channel is ready for writing.
SocketChannel client = (SocketChannel) key.channel();
}
keyIterator.remove();
}
}
}
}
和用selector 注册server socket channel 一样,每个进来的client socket channel 也是用server socket channe 注册的。当 client socket channel 准备好读或写操作,对于关联的socket channel 的 key.isReadable() or key.isWritable() 都返回true, socket channel 可被读写。
一个key代表selectable channel 和selectable channel 之间的关系。这个关系可以调用 SelectionKey’s void cancel() 方法来终止。一旦返回,key会失效,会被已经添加到 selector’s cancelled-key set 。key会在下一次selection operation 从selector’s key sets 移除。
当你完成一个selector,调用Selector’s void close() 。如果这时一个线程在 selector’s selection 方法之一中阻塞了,线程被打断,就好像调用了selector’s wakeup() 方法一样。还和selector关联的uncancelled keys会失效,它们的channels被注销,和这个selector 关联的任何资源被释放。如果selector已经关闭,调用close() 无效。
Selector Demonstration
Selectors 通常用于 server applications 。Listing 8-1 表示了一个应用发送local time到clients。
Listing 8-1. Serving Time to Clients
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
/**
* @author @Jasu
* @date 2018-08-10 16:52
*/
public class SelectorServer {
final static int DEFAULT_PORT = 9999;
static ByteBuffer bb = ByteBuffer.allocateDirect(8);
public static void main(String[] args) throws IOException {
int port = DEFAULT_PORT;
if (args.length > 0) {
port = Integer.parseInt(args[0]);
}
System.out.println("Server starting ... listening on port " + port);
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress(port));
ssc.configureBlocking(false);
Selector s = Selector.open();
ssc.register(s, SelectionKey.OP_ACCEPT);
while (true) {
int n = s.select();
if (n == 0) {
continue;
}
Iterator<SelectionKey> iterator = s.selectedKeys().iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
if (key.isAcceptable()) {
SocketChannel sc;
sc = ((ServerSocketChannel) key.channel()).accept();
if (sc == null) {
continue;
}
System.out.println("Receiving connection");
bb.clear();
bb.putLong(System.currentTimeMillis());
bb.flip();
System.out.println("Writing current time");
while (bb.hasRemaining()) {
sc.write(bb);
}
sc.close();
}
iterator.remove();
}
}
}
}
After outputting a startup message that identifies the listening port, main() obtains a server socket channel followed by the underlying socket, which is bound to the specified port. The server socket channel is then configured for nonblocking mode in preparation for registering this channel with a selector.
new一个selector,server socket channel使用selector注册自己,因此selector可以知道channel什么时候准备好执行accept操作。返回的key没有保存,因为从来没被cancelled (selector 也从没被关闭)。
然后进入无限循环,先调用selector’s select() 方法。如果 server socket channel 还没就绪(select() returns 0 ),循环余下的被跳过。
selected keys 和迭代器被获得。然后内循环遍历。每个key的 isAcceptable() 被调用,找到准备好执行accept operation的server socket channel。如果是这种情况,channel 被获得,被转换为ServerSocketChannel ,ServerSocketChannel’s accept() 方法被调用来接收连接。
为了防止返回的SocketChannel实例为null的可能性(当server socket channel 为非阻塞模式并且没有连接可用于接收),检测这种情况当null被检测continue循环。
A message about receiving a connection is output and the byte buffer is cleared in preparation for storing the local time. After this long integer has been stored in the buffer, the buffer is flipped in preparation for draining. A message about writing the current time is output and the buffer is drained. The socket channel is then closed and the key is removed from the set of keys.
client测试server。
Listing 8-2. Receiving Time from the Server
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
import java.util.Date;
/**
* @author @Jasu
* @date 2018-08-10 17:34
*/
public class SelectorClient {
final static int DEFAULT_PORT = 9999;
static ByteBuffer bb = ByteBuffer.allocateDirect(8);
public static void main(String[] args) {
int port = DEFAULT_PORT;
if (args.length > 0) {
port = Integer.parseInt(args[0]);
}
try {
SocketChannel sc = SocketChannel.open();
InetSocketAddress addr = new InetSocketAddress("localhost", port);
sc.connect(addr);
long time = 0;
while (sc.read(bb) != -1) {
bb.flip();
while (bb.hasRemaining()) {
time <<= 8;
time |= bb.get() & 255;
}
bb.clear();
}
System.out.println(new Date(time));
sc.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
比server代码更简单,因为没有用selectors 。在这个简单的应用不需要selector 。当你的客户端和多个服务器在 client context交互的时候,会典型地使用selector。
代码里有趣的东西:
- bb.get() 返回32-bit integer 代表一个8-bit byte 。用于byte values的Sign extension 大于127 ,被认为是负值。因为 leading one bits 在 bitwise ORing them with time 后影响结果,它们通过 bitwise ANDing the integer with 255 被移除。
- time传入Date,然后println() 调用toString。
输出:
server
Receiving connection
Writing current time
client
Tue Jul 28 13:38:20 CDT 2015
EXERCISES
The following exercises are designed to test your understanding of Chapter 8’s content:
1. Define selector.
2. Identify the three main types that support selectors.
3. True or false: File channels can be used with selectors.
4. What does SelectionKey provide as a convenient alternative to the
expression key.readyOps() & OP_READ != 0?
Summary
A selector is an object created from a subclass of the abstract Selector class. The selector maintains a set of channels that it examines to determine which channels are ready for reading, writing, completing a connection sequence, accepting another connection, or some combination of these tasks.
Selectors are used with selectable channels, which are objects whose classes ultimately inherit from the abstract SelectableChannel class, which describes a channel that can be multiplexed by a selector.
One or more previously created selectable channels are registered with a selector. Each registration returns an instance of a subclass of the abstract SelectionKey class, which is a token signifying the relationship between one channel and the selector. When a selection method is invoked, the selector’s associated keys are updated by checking all channels registered with that selector. The application can then obtain a set of keys whose channels were found ready and iterate over these keys to service each channel that has become ready since the previous select method call.
Chapter 9 Regular Expressions
Pattern, PatternSyntaxException, and Matcher
java.util.regex.Pattern 。Regexes预编译提高性能。
Table 9-1. Pattern Methods
| Method | Description |
|---|---|
| static Pattern compile(String regex) | 编译 regex 。can throw java.util. regex.PatternSyntaxException |
| static Pattern compile(String regex,int flags) | 根据 given flags 编译(一个 bitset , Pattern’s CANON_EQ, CASE_INSENSITIVE, COMMENTS, DOTALL, LITERAL, MULTILINE, UNICODE_CASE, and UNIX_LINES 的组成)。 |
| int flags() | Return this Pattern object’s match flags 。 compile(String) 返回0, compile(String, int) 返回int |
| Matcher matcher(CharSequence input) | 返回 java.util.regex.Matcher 。 Matcher将与这个模式的编译后的正则表达式匹配 。 |
| static boolean matches(String regex, CharSequence input) | Compile regex and attempt to match input against the compiled regex。当有match返回true;否则false。是 Pattern.compile(regex). matcher(input).matches() 的方便方法。 |
| String pattern() | 返回Pattern未编译的 regex |
| static String quote(String s) | Quote s using “\Q” and “\E” so that all other metacharacters lose their special meaning. When the returned java.lang.String object is later compiled into a Pattern instance, it only can be matched literally 。 |
| String[] split(CharSequence input) | Split input around matches of this Pattern’s compiled regex and return an array containing the matches |
| String[] split(CharSequence input, int limit) | Split input around matches of this Pattern’s compiled regex; limit controls the number of times the compiled regex is applied and thus affects the length of the resulting array. |
| String toString() | Return this Pattern’s uncompiled regex |
上面展示了java.lang.CharSequence接口,任何实现这个接口的类(String, java.lang.StringBuffer, and java.lang. StringBuilder )可以被传入到带有CharSequence 参数的Pattern 方法(such as split(CharSequence) )。
Table 9-2. PatternSyntaxException Methods
| Method | Description |
|---|---|
| String getDescription() | Return a description of the syntax error |
| int getIndex() | Return the approximate index of where the syntax error occurred in the pattern or -1 when the index isn’t known. |
| String getMessage() | Return a multiline string containing the description of the syntax error and its index, the erroneous pattern, and a visual indication of the error index within the pattern |
| String getPattern() | Return the erroneous pattern. |
Matcher类:
- boolean matches(): Attempt to match the entire region against the pattern. When the match succeeds, more information can be obtained by calling Matcher’s start(), end(), and group() methods. For example, int start() returns the start index of the previous match, int end() returns the offset of the first character following the previous match, and String group() returns the input subsequence matched by the previous match. Each method throws java.lang. IllegalStateException when a match has not yet been attempted or the previous match attempt failed.
- boolean lookingAt(): Attempt to match the input sequence, starting at the beginning of the region, against the pattern. As with matches(), this method always starts at the beginning of the region. Unlike matches(), lookingAt() doesn’t require that the entire region be matched. When the match succeeds, more information can be obtained by calling Matcher’s start(), end(), and group() methods
- boolean find(): Attempt to find the next instance of the input sequence that matches the pattern. n. It can start at the beginning of this matcher’s region. Or, if a previous call to this method was successful and the matcher hasn’t since been reset (by calling Matcher’s Matcher reset() or Matcher reset(CharSequence input) method), it will start at the first character not matched by the previous match. When the match succeeds, more information can be obtained by calling Matcher’s start(), end(), and group() methods.
Note : A matcher finds matches in a subset of its input called the region. By default, the region contains all of the matcher’s input. The region can be modified by calling Matcher’s Matcher region(int start, int end) method (set the limits of this matcher’s region) and queried by calling Matcher’s int regionStart() and int regionEnd() methods.
Listing 9-1. Playing with Regular Expressions
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.regex.PatternSyntaxException;
public class RegExDemo {
public static void main(String[] args) {
if (args.length != 2) {
System.err.println("usage: java RegExDemo regex input");
return;
}
try {
System.out.println("regex = " + args[0]);
System.out.println("input = " + args[1]);
Pattern p = Pattern.compile(args[0]);
Matcher m = p.matcher(args[1]);
while (m.find())
System.out.println("Located [" + m.group() + "] starting at "
+ m.start() + " and ending at " +
(m.end() - 1));
} catch (PatternSyntaxException pse) {
System.err.println("Bad regex: " + pse.getMessage());
System.err.println("Description: " + pse.getDescription());
System.err.println("Index: " + pse.getIndex());
System.err.println("Incorrect pattern: " + pse.getPattern());
}
}
}
使用\\转义。
Character Classes
- [xyz]
- [^xyz] 非
- [a-z] 区间
- [abc[u-z]] 组合
- [a-c&&[c-f]] 和 结果是c
- [a-z&&[ ^x-z]]
Table 9-3. Predefined Character Classes
| Predefined Character Class | Description |
|---|---|
| \d | Match any digit character. \d is equivalent to [0-9]. |
| \D | Match any nondigit character. \D is equivalent to [ ^\d]. |
| \s | Match any whitespace character. \s is equivalent to [\t\n\x0B\f\r ]. |
| \S | Match any nonwhitespace character. \S is equivalent to [ ^\s]. |
| \w | Match any word character. \w is equivalent to [a-zA-Z0-9]. |
| \W | Match any nonword character. \W is equivalent to [ ^\w]. |
Capturing Groups
Boundary Matchers and Zero-Length Matches
Table 9-4. Boundary Matchers
| Boundary Matcher | Description |
|---|---|
| ^ | Match beginning of line. |
| $ | Match end of line. |
| \b | Match word boundary. |
| \B | Match nonword boundary |
| \A | Match beginning of text. |
| \G | Match end of previous match. |
| \Z | Match end of text except for line terminator (when present) |
| \z | Match end of text. |
Quantifiers
(.*) 匹配最长 ` (.*?) `匹配最短。
Practical Regular Expressions
java RegExDemo "(\(\d{3}\))?\s*\d{3}-\d{4}" "(800) 555-1212"
regex = (\(\d{3}\))?\s*\d{3}-\d{4}
input = (800) 555-1212
Located [(800) 555-1212] starting at 0 and ending at 13
java RegExDemo "(\(\d{3}\))?\s*\d{3}-\d{4}" 555-1212
regex = (\(\d{3}\))?\s*\d{3}-\d{4}
input = 555-1212
Located [555-1212] starting at 0 and ending at 7
Note : To learn more about regular expressions, check out “Lesson: Regular Expressions” at http://download.oracle.com/javase/tutorial/ essential/regex/index.html in The Java Tutorials.
EXERCISES
The following exercises are designed to test your understanding of Chapter 9’s content:
1. Define regular expression.
2. What does the Pattern class accomplish?
3. What do Pattern’s compile() methods do when they discover
illegal syntax in their regular expression arguments?
4. What does the Matcher class accomplish?
5. What is the difference between Matcher’s matches() and
lookingAt() methods?
6. Define character class.
7. Identify the various kinds of character classes.
8. True or false: An intersection character class consists of multiple
&&-separated nested character classes, where at least one nested
character class is a negation character class, and matches all
characters except for those indicated by the negation character
class/classes.
9. Define capturing group.
10. What is a zero-length match?
11. Define quantifier.
12. What is the difference between greedy and reluctant quantifiers?
13. How do possessive and greedy quantifiers differ?
14. Create a ReplaceText application that takes input text, a pattern
that specifies text to replace, and replacement text command-line
arguments, and uses Matcher’s String replaceAll(String
replacement) method to replace all matches of the pattern with
the replacement text (passed to replacement). For example,
java ReplaceText "too many embedded spaces"
"\s+" " " should output too many embedded spaces with
only a single space character between successive words.
Summary
Text-processing applications often need to match text against patterns. NIO includes regular expressions to help these applications perform pattern matching with high performance. Java supports regular expressions by providing the Pattern, PatternSyntaxException, and Matcher classes.
In this chapter, you explored Pattern, PatternSyntaxException, and Matcher. You then learned about character classes, capturing groups, boundary matchers and zero-length matches, and quantifiers. Finally, you observed a practical use case for regexes: phone number matching.
Chapter 10 Charsets
介绍java.nio.charset 包和java.lang.String 类有关的部分。
A Brief Review of the Fundamentals
Java使用Unicode来表示字符。Unicode是一个16位字符集标准 [实际上,更多的是编码标准,因为有些字符是由多个数值表示的;每个值都被称为代码点 ],目标是将世界上所有有意义的字符集合映射成一个全部包含的map。虽然这让使用不用语言的字符很容易,但不能全自动经常需要使用编码。在我深入探讨这个主题之前,您应该理解以下术语:
- Character: A meaningful symbol. For example, “$” and “E” are characters. These symbols predate the computer era(时代)。
- Character set: characters 的set。例如,大写英文字母A-Z可以被认为形成一个 character set。没有分配数字值。和Unicode, ASCII, EBCDIC 或任意字符集标准没关系。
- Coded character set: 一个character set 每个character 被分配为独立的数字值。标准体比如US-ASCII or ISO-8859-1 定义从字符到数字值的映射。
- Character-encoding scheme: coded character set的 numeric values到这些值代表的字节序列的encoding。一些encoding是一对一的。例如, ASCII ,A被映射为integer 65 ,使用integer 65 被encoded。一些其他的mappings是一对一或者一对多的。例如, UTF-8 编码Unicode 字符。每个数字值小于128的字符被编码为单字节,来和 ASCII兼容。其他Unicode characters被编码为wo-to-six-byte 序列。See www.ietf.org/rfc/rfc2279.txt for more information.
- Charset: 一个 coded character set 结合character-encoding scheme 。被描述为 java.nio.charset.Charset 抽象类。
虽然Unicode被大范围使用,其他character set standards也被使用。因为操作系统在byte级别执行I/O,文件用字节序列存储数据,有必要在 byte sequences 和要被编码为字节序列的characters 之间转化。
Working with Charsets
从JDK 1.4,JVMs 被要求支持一个标准的charset集合,可以支持额外charsets 。也支持default charset ,不需要是标准集的一个,在JVM启动时获得。Table 10-1 identifies and describes the standard charsets.
Table 10-1. Standard Charsets
| Charset Name | Description |
|---|---|
| US-ASCII | Seven-bit ASCII, which forms the American-English character set. Also known as the basic Latin block in Unicode. |
| ISO-8859-1 | The 8-bit character set used by most European languages. It’s a superset of ASCII and includes most non-English European characters. |
| UTF-8 | An 8-bit byte-oriented character encoding for Unicode. Characters are encoded in one to six bytes. |
| UTF-16BE | A 16-bit encoding using big-endian order for Unicode. Characters are encoded in two bytes with the high-order eight bits written first. |
| UTF-16LE | A 16-bit encoding using little-endian order for Unicode. Characters are encoded in two bytes with the low-order eight bits written first. |
| UTF-16 | A 16-bit encoding whose endian order is determined by an optional byte-order mark. |
Charset names不分大小写,由 Internet Assigned Names Authority (IANA)维护。
Listing 10-1. Using Charsets to Encode Characters into Byte Sequences
import java.nio.ByteBuffer;
import java.nio.charset.Charset;
/**
* @author @Jasu
* @date 2018-08-15 16:01
*/
public class CharsetDemo {
public static void main(String[] args) {
String msg = "façade touché";
String[] csNames =
{
"US-ASCII",
"ISO-8859-1",
"UTF-8",
"UTF-16BE",
"UTF-16LE",
"UTF-16"
};
encode(msg, Charset.defaultCharset());
for (String csName: csNames)
encode(msg, Charset.forName(csName));
}
static void encode(String msg, Charset cs) {
System.out.println("Charset: " + cs.toString());
System.out.println("Message: " + msg);
ByteBuffer buffer = cs.encode(msg);
System.out.println("Encoded: ");
for (int i = 0; buffer.hasRemaining(); i++) {
int _byte = buffer.get() & 255;
char ch = (char) _byte;
if (Character.isWhitespace(ch) || Character.isISOControl(ch)) {
ch = '\u0000';
}
System.out.printf("%2d: %02x (%c)%n", i, _byte, ch);
}
System.out.println();
}
}
main() next iterates over the bytes in the byte buffer, converting each byte to a character. It uses java.lang.Character’s isWhitespace() and isISOControl() methods to determine if the character is whitespace or a control character (neither is regarded as printable) and converts such a character to Unicode 0 (an empty string). (A carriage return or newline would screw up the output, for example.)
Finally, the index of the character, its hexadecimal value, and the character itself are printed to the standard output stream. I chose to use System.out. printf() for this task. You’ll learn about this method in the next chapter.
"C:\Program Files\Java\jdk1.8.0_161\bin\java.exe" "-javaagent:C:\Program Files\JetBrains\IntelliJ IDEA 2018.1.6\lib\idea_rt.jar=57257:C:\Program Files\JetBrains\IntelliJ IDEA 2018.1.6\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_161\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\cldrdata.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\jfxrt.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\nashorn.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\sunec.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\sunjce_provider.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\sunmscapi.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\sunpkcs11.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\ext\zipfs.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\javaws.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\jce.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\jfr.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\jfxswt.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\jsse.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\management-agent.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\plugin.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\resources.jar;C:\Program Files\Java\jdk1.8.0_161\jre\lib\rt.jar;E:\SpringSourceCode\target\classes;D:\Maven\repository\junit\junit\4.11\junit-4.11.jar;D:\Maven\repository\org\hamcrest\hamcrest-core\1.3\hamcrest-core-1.3.jar;D:\Maven\repository\org\springframework\spring-core\5.0.7.RELEASE\spring-core-5.0.7.RELEASE.jar;D:\Maven\repository\org\springframework\spring-jcl\5.0.7.RELEASE\spring-jcl-5.0.7.RELEASE.jar;D:\Maven\repository\org\springframework\spring-beans\5.0.7.RELEASE\spring-beans-5.0.7.RELEASE.jar;D:\Maven\repository\org\springframework\spring-context\5.0.7.RELEASE\spring-context-5.0.7.RELEASE.jar;D:\Maven\repository\org\springframework\spring-expression\5.0.7.RELEASE\spring-expression-5.0.7.RELEASE.jar;D:\Maven\repository\org\springframework\spring-aop\5.0.7.RELEASE\spring-aop-5.0.7.RELEASE.jar;D:\Maven\repository\org\springframework\spring-tx\5.0.7.RELEASE\spring-tx-5.0.7.RELEASE.jar;D:\Maven\repository\org\springframework\spring-aspects\5.0.7.RELEASE\spring-aspects-5.0.7.RELEASE.jar;D:\Maven\repository\org\aspectj\aspectjweaver\1.8.13\aspectjweaver-1.8.13.jar;D:\Maven\repository\org\springframework\spring-webmvc\5.0.7.RELEASE\spring-webmvc-5.0.7.RELEASE.jar;D:\Maven\repository\org\springframework\spring-web\5.0.7.RELEASE\spring-web-5.0.7.RELEASE.jar;D:\Maven\repository\org\springframework\spring-test\5.0.7.RELEASE\spring-test-5.0.7.RELEASE.jar;D:\Maven\repository\com\google\guava\guava\25.1-jre\guava-25.1-jre.jar;D:\Maven\repository\com\google\code\findbugs\jsr305\3.0.2\jsr305-3.0.2.jar;D:\Maven\repository\org\checkerframework\checker-qual\2.0.0\checker-qual-2.0.0.jar;D:\Maven\repository\com\google\errorprone\error_prone_annotations\2.1.3\error_prone_annotations-2.1.3.jar;D:\Maven\repository\com\google\j2objc\j2objc-annotations\1.1\j2objc-annotations-1.1.jar;D:\Maven\repository\org\codehaus\mojo\animal-sniffer-annotations\1.14\animal-sniffer-annotations-1.14.jar;D:\Maven\repository\javax\servlet\servlet-api\2.5\servlet-api-2.5.jar" com.jasu.nio._10_Charsets.CharsetDemo
Charset: UTF-8
Message: façade touché
Encoded:
0: 66 (f)
1: 61 (a)
2: c3 (Ã)
3: a7 (§)
4: 61 (a)
5: 64 (d)
6: 65 (e)
7: 20 ( )
8: 74 (t)
9: 6f (o)
10: 75 (u)
11: 63 (c)
12: 68 (h)
13: c3 (Ã)
14: a9 (©)
Charset: US-ASCII
Message: façade touché
Encoded:
0: 66 (f)
1: 61 (a)
2: 3f (?)
3: 61 (a)
4: 64 (d)
5: 65 (e)
6: 20 ( )
7: 74 (t)
8: 6f (o)
9: 75 (u)
10: 63 (c)
11: 68 (h)
12: 3f (?)
Charset: ISO-8859-1
Message: façade touché
Encoded:
0: 66 (f)
1: 61 (a)
2: e7 (ç)
3: 61 (a)
4: 64 (d)
5: 65 (e)
6: 20 ( )
7: 74 (t)
8: 6f (o)
9: 75 (u)
10: 63 (c)
11: 68 (h)
12: e9 (é)
Charset: UTF-8
Message: façade touché
Encoded:
0: 66 (f)
1: 61 (a)
2: c3 (Ã)
3: a7 (§)
4: 61 (a)
5: 64 (d)
6: 65 (e)
7: 20 ( )
8: 74 (t)
9: 6f (o)
10: 75 (u)
11: 63 (c)
12: 68 (h)
13: c3 (Ã)
14: a9 (©)
Charset: UTF-16BE
Message: façade touché
Encoded:
0: 00 ( )
1: 66 (f)
2: 00 ( )
3: 61 (a)
4: 00 ( )
5: e7 (ç)
6: 00 ( )
7: 61 (a)
8: 00 ( )
9: 64 (d)
10: 00 ( )
11: 65 (e)
12: 00 ( )
13: 20 ( )
14: 00 ( )
15: 74 (t)
16: 00 ( )
17: 6f (o)
18: 00 ( )
19: 75 (u)
20: 00 ( )
21: 63 (c)
22: 00 ( )
23: 68 (h)
24: 00 ( )
25: e9 (é)
Charset: UTF-16LE
Message: façade touché
Encoded:
0: 66 (f)
1: 00 ( )
2: 61 (a)
3: 00 ( )
4: e7 (ç)
5: 00 ( )
6: 61 (a)
7: 00 ( )
8: 64 (d)
9: 00 ( )
10: 65 (e)
11: 00 ( )
12: 20 ( )
13: 00 ( )
14: 74 (t)
15: 00 ( )
16: 6f (o)
17: 00 ( )
18: 75 (u)
19: 00 ( )
20: 63 (c)
21: 00 ( )
22: 68 (h)
23: 00 ( )
24: e9 (é)
25: 00 ( )
Charset: UTF-16
Message: façade touché
Encoded:
0: fe (þ)
1: ff (ÿ)
2: 00 ( )
3: 66 (f)
4: 00 ( )
5: 61 (a)
6: 00 ( )
7: e7 (ç)
8: 00 ( )
9: 61 (a)
10: 00 ( )
11: 64 (d)
12: 00 ( )
13: 65 (e)
14: 00 ( )
15: 20 ( )
16: 00 ( )
17: 74 (t)
18: 00 ( )
19: 6f (o)
20: 00 ( )
21: 75 (u)
22: 00 ( )
23: 63 (c)
24: 00 ( )
25: 68 (h)
26: 00 ( )
27: e9 (é)
Process finished with exit code 0
As well as providing encoding methods such as the aforementioned ByteBuffer encode(String s) method, Charset provides a complementary CharBuffer decode(ByteBuffer buffer) decoding method. The return type is java.nio.CharBuffer because byte sequences are decoded into characters.
Note ByteBuffer encode(String s) is a convenience method for specifying CharBuffer.wrap(s) and passing the result to the ByteBuffer encode(CharBuffer buffer) method.
If you dig deeper into Charset, you’ll encounter the following pair of methods:
- CharsetEncoder newEncoder()
- CharsetDecoder newDecoder()
These methods perform the actual work of encoding and decoding. Charset’s encode() and decode() methods delegate to the java.nio. charset.CharsetEncoder and java.nio.charset.CharsetDecoder objects returned from newEncoder() and newDecoder(), and invoke their encode() and decode() (along with additional) methods. (For brevity, I don’t discuss CharsetEncoder and CharsetDecoder.)
Charsets and the String Class
The String class describes a string as a sequence of characters. It declares constructors that can be passed byte arrays. Because a byte array contains an encoded character sequence, a charset is required to decode them. Here is a partial list of String constructors that work with charsets:
- String(byte[] data): Constructs a new String instance by decoding the specified array of bytes using the platform’s default charset.
- String(byte[] data, int offset, int byteCount): Constructs a new String instance by decoding the specified subsequence of the byte array using the platform’s default charset.
- String(byte[] data, String charsetName): Constructs a new String instance by decoding the specified array of bytes using the named charset.
Furthermore, String declares methods that encode its sequence of characters into a byte array with help from the default charset or a named charset. Two of these methods are described here:
- byte[] getBytes(): Returns a new byte array containing the characters of this string encoded using the platform’s default charset.
- byte[] getBytes(String charsetName): Returns a new byte array containing the characters of this string encoded using the named charset.
Note that String(byte[] data, String charsetName) and byte[] getBytes(String charsetName) throw java.io.UnsupportedEncodingException when the charset isn’t supported
I’ve created a small application that demonstrates String and charsets. Listing 10-2 presents the source code .
Listing 10-2. Using Charsets with String
import java.io.UnsupportedEncodingException;
public class CharsetDemo
{
public static void main(String[] args)
throws UnsupportedEncodingException
{
byte[] encodedMsg =
{
0x66, 0x61, (byte) 0xc3, (byte) 0xa7, 0x61, 0x64, 0x65, 0x20, 0x74,
0x6f, 0x75, 0x63, 0x68, (byte) 0xc3, (byte) 0xa9
};
String s = new String(encodedMsg, "UTF-8");
System.out.println(s);
System.out.println();
byte[] bytes = s.getBytes();
for (byte _byte: bytes)
System.out.print(Integer.toHexString(_byte & 255) + " ");
System.out.println();
}
}
Listing 10-2’s main() method first creates a byte array containing a UTF-8 encoded message. It then converts this array to a String object via the UTF-8 charset. After outputting the resulting String object, it extracts this object’s bytes into a new byte array and proceeds to output these bytes in hexadecimal format. As demonstrated earlier in this chapter, I bitwise AND each byte value with 255 to remove the 0xFF sign extension bytes for negative integers when the 8-bit byte integer value is converted to a 32-bit integer value. These sign extension bytes would otherwise be output.
façade touché
66 61 e7 61 64 65 20 74 6f 75 63 68 e9
You might be wondering why you observe e7 instead of c3 a7 (Latin small letter c with a cedilla [a hook or tail]) and e9 instead of c3 a9 (Latin small letter e with an acute accent). The answer is that I invoked the noargument getBytes() method to encode the string. This method uses the default charset, which is windows-1252 on my platform. According to this charset, e7 is equivalent to c3 a7 and e9 is equivalent to c3 a9. The result is a shorter encoded sequence.
EXERCISES
The following exercises are designed to test your understanding of Chapter 10’s content:
1. Define charset.
2. What is the purpose of the Charset class?
3. Identify the standard charsets supported by the JVM.
4. What is the purpose of the byte order mark?
5. How do you obtain the default charset?
6. What does Charset’s Charset forName(String charsetName)
factory method do when the desired charset isn’t supported by the JVM?
7. How would you typically encode a string via a Charset instance?
8. Identify the Charset methods that perform the actual encoding and
decoding tasks.
9. What does String’s byte[] getBytes() method accomplish?
10. Write an AvailCharsets application that obtains and outputs a
map of all charsets that the current JVM supports. (Hint: You’ll find the
method that returns this map in the Charset class.)
Summary
Charsets combine coded character sets with character-encoding schemes. They’re used to translate between byte sequences and the characters that are encoded into these sequences. Java supports charsets by providing Charset and related classes. It also uses charsets with the String class. Chapter 11 presents NIO’s java.util.Formatter class and related types.
Chapter 11 Formatter
JSR 51 (http://jcp.org/en/jsr/detail?id=51) 的描述了一个简单的printf风格的格式化工具被提议纳NIO。使printf()函数有用的一个特性是varargs ,传递可变数量的参数。因为JDK 5前不支持varargs ,JDK5添加了prinf()
Exploring Formatter
JDK5引入java.util.Formatter 作为interpreter 用于printf()-style format strings 。这个类支持layout justification and alignment(布局调整和对齐 ); numeric, string, and date/time data 的通用format;和更多。用的Java类型被支持(such as byte and java.math.BigDecimal )。
注意:java.lang.Appendable 接口描述了char values and character sequences 可以被添加的对象。format输出的类(例如StringBuilder )实现Appendable 。
It’s cumbersome to have to create and manage a Formatter object when all you want to do is achieve something equivalent to the C language’s printf() function. Java addresses this situation by adding format() and the equivalent printf() methods to the java.io.PrintStream class.
Of the various formatter-oriented methods added to PrintStream, you’ll often invoke PrintStream printf(String format, Object… args). After sending its formatted content to the print stream, this method returns a reference to this stream so that you can chain method calls together.
Listing 11-2. Formatting via printf()
public class FormatterDemo
{
public static void main(String[] args)
{
System.out.printf("%04X%n", 478);
System.out.printf("Current date: %1$tb %1$te, %1$tY%n",
System.currentTimeMillis());
}
}
01DE
Current date: Jul 28, 2015
Exploring Formattable and FormattableFlags
EXERCISES
The following exercises are designed to test your understanding of Chapter 11’s content:
1. Identify the three nonexception types that contribute to NIO’s
printf-style formatting facility.
2. How do you reference an argument from within a format specifier
string?
3. What does the %n format specifier accomplish?
4. Modify Listing 11-1 so that FormatterDemo’s output isn’t
concatenated into one long string.
Summary
JDK 5 introduced the Formatter class as an interpreter for printf()-style format strings. This class provides support for layout justification and alignment; common formats for numeric, string, and date/time data; and more. Commonly used Java types (such as byte and BigDecimal) are supported.
Formatter declares several constructors for creating Formatter objects. These constructors let you specify where you want formatted output to be sent. For example, Formatter() writes formatted output to an internal StringBuilder instance. You can access the destination by calling Formatter’s Appendable out() method.
After creating a Formatter object, call a format() method to format a varying number of values. For example, Formatter format(String format, Object… args) formats the args array according to the string of format specifiers passed to the format parameter, and returns a reference to the invoking Formatter so that you can chain the format() calls together.
It’s cumbersome to have to create and manage a Formatter object when all you want to do is achieve something equivalent to the C language’s printf() function. Java addresses this situation by adding format() and equivalent printf() methods (such as PrintStream printf(String format, Object… args)) to the PrintStream class.
Formatter is accompanied by a Formattable interface and a FormattableFlags class that collectively support limited formatting customization for arbitrary user-defined types. Formattable is implemented by any class that needs to perform custom formatting using Formatter’s “s” (format argument as string) conversion character.
Part IV More New I/O APIs
Chapter 12 Improved File System Interface
NIO.2 改进了file system interface。
Note A file system manages files, which are classified as regular files, directories, symbolic links (https://en.wikipedia.org/wiki/Symbolic_ link), and hard links (https://en.wikipedia.org/wiki/Hard_link).
Architecting a Better File Class
File-based file system是有问题的。以下是几个问题:
- 很多方法返回boolean而不抛异常。结果是你不知道为什么操作失败了。比如, delete() 返回false,你不知道为什么删不了
- File 不支持文件系统特定的symbolic links and hard links 。
- File只提供有限file attributes set的访问。例如,不支持访问access control lists (ACLs) (https://en.wikipedia.org/wiki/Access_ control_list)。
- File 不支持高效的文件属性访问。每个query 导致调用底层操作系统。
- File 不能扩展到大文件夹。请求文件大目录导致应用hang住。大文件夹也导致内存资源问题,导致拒绝服务。
- File 被限制在default file system (JVM 可以访问的file system )。不支持替代方案,比如基于内存的文件系统。
- File没提供file-copy or a file-move能力。renameTo() 方法,在文件移动上下文经常使用,在不同操作系统下结果不一致。
NIO.2 provides an improved file system interface that offers solutions to the previous problems. Some of its features are listed here:
- 方法抛出异常
- 支持symbolic links
- 对文件属性广泛和有效的支持
- Directory streams
- custom file system providers 支持alternative file systems
- 支持 file copying and file moving
- 支持walking the file tree /visiting files and watching directories
improved file system interface 主要由以下几个包实现:
- java.nio.file: 为访问文件系统和文件提供接口和类。
- java.nio.file.attribute: 为访问文件属性提供接口和类。
- java.nio.file.spi: 为创建文件系统实现提供类
These packages organize many types. FileSystem, FileSystems, and FileSystemProvider form the core of the improved file system interface.
File Systems and File System Providers
操作系统可以承载一个或多个文件系统 。例如,Unix/ Linux 结合所有安装的磁盘到一个虚拟文件系统。Windows将一个单独的文件系统与每个活动磁盘驱动器相关联; for example, FAT16 for drive A: and NTFS for drive C: 。
java.nio.file.FileSystem 类interfaces between Java code and a file system 。另外,FileSystem是一个工厂,可以得到很多类型的file system-related objects(比如file stores and paths )和services(such as watch services )。
FileSystem 不能实例化因为是抽象的。代替的是,java.nio.file.FileSystems util类通过工厂方法获得FileSystems。例如,FileSystem getDefault() 方法返回默认的 FileSystem 对象。
FileSystem fsDefault = FileSystems.getDefault();
FileSystems也声明了FileSystem getFileSystem(URI uri) 方法得到路径关联的FileSystem 。也声明了3个newFileSystem() 方法创建新FileSystems。
java.nio.file.spi.FileSystemProvider 类被FileSystems的工厂方法使用来获得或创建文件系统。一个具体的FileSystemProvider子类实现了很多方法用于 copying, moving, and deleting files;obtaining a path ;reading attributes and the targets of symbolic links ;creating directories, links, and symbolic links ;等等。
Figure 12-1 shows how FileSystem, FileSystems, and FileSystemProvider are related.
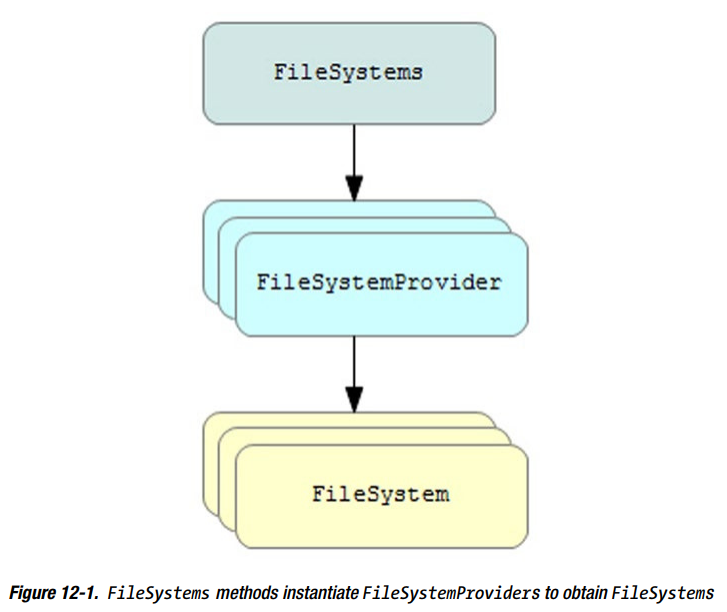
A Java implementation provides concrete FileSystemProvider subclasses that describe different kinds of file system providers. If you’re curious about the file system providers supported by your Java implementation, run the application whose source code appears in Listing 12-1.
Listing 12-1. Identifying Installed File System Providers
public class FileSystemDemo {
public static void main(String[] args) {
List<FileSystemProvider> fileSystemProviders = FileSystemProvider.installedProviders();
for (FileSystemProvider provider : fileSystemProviders) {
System.out.println(provider);
}
}
}
Listing 12-1 invokes FileSystemProvider’s List installedProviders() class method to obtain a list of the installed file system providers. It then iterates over this list, implicitly invoking each provider’s toString() method and outputting the resulting string.
un.nio.fs.WindowsFileSystem@5a07e868
sun.nio.fs.WindowsFileSystemProvider@279f2327
com.sun.nio.zipfs.ZipFileSystemProvider@2ff4acd0
This output tells me two things: FileSystems that interface to the file systems that are native to my Windows 7 operating system are obtained from the WindowsFileSystemProvider subclass. Also, I can obtain FileSystems that are based on ZIP files.
With few exceptions, NIO.2’s various types ultimately delegate to the foundational FileSystem, FileSystems, and FileSystemProvider types.
Locating Files with Paths
A file system stores files (definitely regular files and directories, and possibly symbolic links and hard links). Files are typically stored in hierarchies and are located by specifying paths, which are compact maps that navigate these hierarchies via separated name element sequences.
java.nio.file.Path 接口代表一个文件路径。
Note Path declares FileSystem getFileSystem() to return a reference to the FileSystem that created the file described by the Path object .
Path 可以表示root,root和name序列,或者一个或多个name元素。使用empty path 访问文件等同于访问file system’s default directory。
注意:File声明了File toFile() 返回代表路径的File 。当path对象没和默认provider关联抛出UnsupportedOperationException 。声明 Path toPath() 返回代表File object’s abstract path的Path对象。这些方法让你在源码里混合File和Path,您可以慢慢地将遗留的基于File的代码转换为使用改进的文件系统接口的代码。
Getting a Path and Accessing Its Name Elements
FileSystem 提供Path getPath(String first, String… more) 返回Path对象。第一个参数是 path string 的开头部分。可变参数是后面连接起来形成完整路径。
注意:当构建Path,name元素通常是用分隔符连接的(FileSystem’s String getSeparator() 返回)。The resulting path string represents a systemdependent file path。
Consider the following example:
Path path = fsDefault.getPath("x", "y");
This example constructs a Path with y subordinate to x. You could also construct this Path as follows:
Path path = fsDefault.getPath("x\\y");
Unlike in the former example, I’ve included the backslash () name-separator character (escaped to satisfy the Java compiler) that Windows understands.
路径必须符合语法。不合法InvalidPathException
NIO.2 提供更便利的工具类java.nio.file.Paths ,返回Path objects 的方法:
- Path get(String first, String… more)
- Path get(URI uri)
The first method is equivalent to calling getPath() on the default file system and returning the result:
return FileSystems.getDefault().getPath(first, more);
The second method is a bit more involved. It iterates over the installed file system providers to locate the provider that is identified by the given URI’s scheme component. When this provider is found for the file scheme, this method executes the following code:
return FileSystems.getDefault().provider().getPath(uri);
After obtaining the default file system, FileSystem’s FileSystemProvider provider() method is called to return the file system provider that created the FileSystem object. Then, FileSystemProvider’s Path getPath(URI uri) method is called to convert the URI argument to a Path object.
For any other scheme, the installed providers list is searched for the first provider with a matching scheme. getPath(uri) is called on the provider.
get(String, String…) throws InvalidPathException when a path cannot be constructed because of bad syntax. get(URI) throws java.nio.file. FileSystemNotFoundException when no FileSystem matches the scheme and java.lang.IllegalArgumentException for a bad URI.
Path declares several methods for accessing its name elements:
- Path getFileName(): 返回Filename的Path对象。
- Path getName(int index): 返回indexth name element The index starts at 0, which represents the element closest to the root. The element farthest from the root is identified by one less than the name count.
- int getNameCount(): Return the number of name elements in the path.
- Path getParent(): Return the parent path or null when there is no parent.
- Path getRoot(): Return the root name element in this path as a Path object or null when there is no root.
- Path subpath(int beginIndex, int endIndex): Return a relative path that is a subsequence of the name elements in this path. The first name element (closest to the root) is located at beginIndex and the last name element (farthest from the root) is located at one less than endIndex.
Relative and Absolute Paths
前面的路径示例演示了相对路径。 你可以调用Path’s boolean isAbsolute() 来证实。这个方法返回false表示路径不是绝对的。 创建一条绝对路径,您需要将根作为第一个名称元素。
调用FileSystem’s Iterable getRootDirectories() 获得file system’s root(s) ,它返回一个迭代器,而不是路径实例描述的ROOT。 Listing 12-3 presents the source code to an application that demonstrates this method and absolute path creation.
Listing 12-3. Demonstrating Root Directory Iteration and Absolute Path Creation
import java.nio.file.FileSystem;
import java.nio.file.FileSystems;
import java.nio.file.Path;
/**
* @author @Jasu
* @date 2018-08-17 18:13
*/
public class RelativePath {
public static void main(String[] args) {
FileSystem aDefault = FileSystems.getDefault();
Path path = aDefault.getPath("a", "b", "c");
System.out.println(path + " , " + path.isAbsolute());
System.out.println(path.getRoot());
Iterable<Path> rootDirectories = aDefault.getRootDirectories();
for (Path root : rootDirectories) {
path = aDefault.getPath(root.toString(), "a", "b", "c");
System.out.println(path + " , " + path.isAbsolute());
System.out.println(path.getRoot());
}
}
}
a\b\c , false
null
C:\a\b\c , true
C:\
D:\a\b\c , true
D:\
E:\a\b\c , true
E:\
F:\a\b\c , true
F:\
If you have a relative path, you can convert it to an absolute path by calling Path’s Path toAbsolutePath() method, as demonstrated in Listing 12-4.
Listing 12-4. Converting a Relative Path to an Absolute Path
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* @author @Jasu
* @date 2018-08-17 18:19
*/
public class AbsolutePathDemo {
public static void main(String[] args) {
Path path = Paths.get("a", "b", "c");
System.out.printf("Path: %s%n", path.toString());
System.out.printf("Absolute: %b%n", path.isAbsolute());
path = path.toAbsolutePath();
System.out.printf("Path: %s%n", path.toString());
System.out.printf("Absolute: %b%n", path.isAbsolute());
}
}
Compile Listing 12-4 (javac PathDemo.java) and run the resulting application (java PathDemo). I observe the following output:
Path: a\b\c
Absolute: false
Path: C:\prj\books\io\ch12\code\PathDemo\v3\a\b\c
Absolute: true
根据toAbsolutePath()’s JDK 文档,如果path已经是绝对路径,返回path。否则,方法用取决于实现的方式处理path,typically by resolving the path against a file system default directory. Depending on the implementation, this method may throw an I/O error when the file system isn’t accessible.
Normalization, Relativization, and Resolution
Path声明几个方法 来移除path冗余, to create a relative path between two paths, and to resolve (join) two paths:
- Path normalize()
- Path relativize(Path other)
- Path resolve(Path other)
- Path resolve(String other)
normalize()移除冗余,比如reports/./2015/jan 。-> reports/2015/jan.
relativize() 在两个path之间创建相对路径。比如,给定reports/2015/jan ,对于reports/2016/mar 的相对路径是 ../../2016/mar 。
resolve() 和relativize()是反过来的。加入一个局部路径到另一个path。例如,resolve apr 对reports/2015 结果是reports/2015/apr 。
另外,声明了下面方法对当前path的父path resolve a path string 。
- Path resolveSibling(Path other)
- Path resolveSibling(String other)
Listing 12-5. Normalizing, Relativizing, and Resolving Paths
import java.nio.file.FileSystems;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.Iterator;
/**
* @author @Jasu
* @date 2018-08-28 14:31
*/
public class NormalizationDemo {
public static void main(String[] args) {
Path path1 = Paths.get("reports", ".", "2015", "jan");
System.out.println(path1);
System.out.println(path1.normalize());
path1 = Paths.get("reports", "2015", "..", "jan");
System.out.println(path1);
System.out.println(path1.normalize());
System.out.println();
path1 = Paths.get("reports", "2015", "jan");
System.out.println(path1);
System.out.println(path1.relativize(Paths.get("reports", "2016", "mar")));
Iterator<Path> iterator = FileSystems.getDefault().getRootDirectories().iterator();
Path root = iterator.next();
try {
if (root != null) {
System.out.printf("Root: %s%n", root.toString());
Path path = Paths.get(root.toString(), "reports", "2016", "mar");
System.out.printf("Path: %s%n", path);
System.out.println(path1.relativize(path));
}
} catch (IllegalArgumentException e) {
e.printStackTrace();
}
System.out.println();
path1 = Paths.get("report", "2015");
System.out.println(path1);
System.out.println(path1.resolve("apr"));
System.out.println();
Path path2 = Paths.get("reports", "2015", "jan");
System.out.println(path2);
System.out.println(path2.getParent());
System.out.println(path2.resolveSibling(Paths.get("mar")));
System.out.println(path2.resolve(Paths.get("mar")));
}
}
reports\.\2015\jan
reports\2015\jan
reports\jan
reports\2015\jan
..\..\2016\mar
Root: C:\
Path: C:\reports\2016\mar
java.lang.IllegalArgumentException: 'other' is different type of Path
at sun.nio.fs.WindowsPath.relativize(WindowsPath.java:388)
at sun.nio.fs.WindowsPath.relativize(WindowsPath.java:44)
at PathDemo.main(PathDemo.java:29)
reports\2015
reports\2015\apr
reports\2015\jan
reports\2015
reports\2015\mar
reports\2015\jan\mar
其中一个Path含有root不能relativize()。
Additional Capabilities
Path提供了比较paths,决定确定path以另一个path开头或者结尾,转换path为java.net.URI (Uniform Resource Identifier) object 。等等。
Listing 12-6. Demonstrating Additional Path Methods
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* @author @Jasu
* @date 2018-08-28 15:29
*/
public class PathExtraDemo {
public static void main(String[] args) throws IOException {
Path path1 = Paths.get("a", "b", "c");
Path path2 = Paths.get("a", "b", "c", "d");
System.out.printf("path1: %s%n", path1.toString());
System.out.printf("path2: %s%n", path2.toString());
System.out.printf("path1.equals(path2): %b%n", path1.equals(path2));
System.out.printf("path1.equals(path2.subpath(0, 3)): %b%n",
path1.equals(path2.subpath(0, 3)));
System.out.printf("path1.compareTo(path2): %d%n",
path1.compareTo(path2));
System.out.printf("path1.startsWith(\"x\"): %b%n",
path1.startsWith("x"));
System.out.printf("path1.startsWith(Paths.get(\"a\"): %b%n",
path1.startsWith(Paths.get("a")));
System.out.printf("path2.endsWith(\"d\"): %b%n",
path2.startsWith("d"));
System.out.printf("path2.endsWith(Paths.get(\"c\", \"d\"): " +
"%b%n",
path2.endsWith(Paths.get("c", "d")));
System.out.printf("path2.toUri(): %s%n", path2.toUri());
Path path3 = Paths.get(".");
System.out.printf("path3: %s%n", path3.toString());
System.out.printf("path3.toRealPath(): %s%n", path3.toRealPath());
}
}
path1: a\b\c
path2: a\b\c\d
path1.equals(path2): false
path1.equals(path2.subpath(0, 3)): true
path1.compareTo(path2): -2
path1.startsWith("x"): false
path1.startsWith(Paths.get("a"): true
path2.endsWith("d"): false
path2.endsWith(Paths.get("c", "d"): true
path2.toUri(): file:///C:/prj/books/io/ch12/code/PathDemo/v5/a/b/c/d
path3: .
path3.toRealPath(): C:\prj\books\io\ch12\code\PathDemo\v5
Performing File System Tasks with Files
大多数情况,用FileSystem, FileSystems, and FileSystemProvider 就能执行很多文件系统任务,比如复制移动文件。然而,有一个更简单的方式执行这些任务:java.nio.file.Files 。
注意:Files不提供path-matching and directory-watching支持。然而,只有Files支持walking the file tree and visiting its files。
Accessing File Stores
FileSystem依赖java.nio.file.FileStore 类提供 file stores 的信息,它们是 storage pools, devices, partitions, volumes, concrete file systems, or other implementation-specific means of file storage 。一个 file store包含name,type,space amounts (in bytes), and other information。
Files 声明FileStore getFileStore(Path path) 返回FileStore ,代表存储path的file store 。拿到FileStore ,可以用以下方法:
- long getTotalSpace(): Return the size, in bytes, of the file store.
- long getUnallocatedSpace(): Return the number of unallocated bytes in the file store. 这是一个hint ,不是guarantee。
- long getUsableSpace(): Return the number of bytes available to this JVM on the file store. hint 。
- boolean isReadOnly(): Return true when this file store is read-only.
- String name(): Return the name of this file store. The returned string may differ from the string returned by the toString() method.
- String type(): Return the type of this file store. The format of the returned string is highly implementationspecific. It may indicate, for example, the format used or whether the file store is local or remote.
Listing 12-7. Accessing a File Store and Outputting File Store Details
import java.io.IOException;
import java.nio.file.FileStore;
import java.nio.file.Files;
import java.nio.file.Paths;
/**
* @author @Jasu
* @date 2018-08-28 17:45
*/
public class FileStoreDemo {
public static void main(String[] args) throws IOException {
FileStore fs = Files.getFileStore(Paths.get("."));
System.out.printf("Total space: %d%n", fs.getTotalSpace());
System.out.printf("Unallocated space: %d%n",
fs.getUnallocatedSpace());
System.out.printf("Usable space: %d%n",
fs.getUsableSpace());
System.out.printf("Read only: %b%n", fs.isReadOnly());
System.out.printf("Name: %s%n", fs.name());
System.out.printf("Type: %s%n%n", fs.type());
}
}
Total space: 144970526720
Unallocated space: 137414221824
Usable space: 137414221824
Read only: false
Name: 文档
Type: NTFS
使用 FileSystem’s Iterable getFileStores() 得到所有file store。
Listing 12-8. Iterating Over the Default File System’s File Stores
import java.nio.file.FileStore;
import java.nio.file.FileSystem;
import java.nio.file.FileSystems;
/**
* @author @Jasu
* @date 2018-08-28 17:51
*/
public class FileStoresDemo {
public static void main(String[] args) {
FileSystem fsDefault = FileSystems.getDefault();
for (FileStore fileStore : fsDefault.getFileStores()) {
System.out.printf("Filestore: %s%n", fileStore);
}
}
}
Filestore: (C:)
Filestore: 软件 (D:)
Filestore: 文档 (E:)
Filestore: work (F:)
Managing Attributes
File关联很多属性,比如size, last modification time, hidden, permissions, and owner 。 NIO.2 通过 java.nio.file.attribute 包的types和 Files 类的属性方法支持属性。
Attributes are grouped into views, 每个view对应一个特定文件系统实现。一些views提供readAttributes() 让你读大量属性。调用Files’s getAttribute() and setAttribute() 获取设置属性。
Views 由来自AttributeView 的接口描述, name() 方法返回view name。该接口被子类型FileAttributeView继承,它是和files关联的属性的view。FileAttributeView 没有方法。
FileAttributeView 被以下类继承:
- BasicFileAttributeView: 提供对大多数文件系统通用的文件基础属性集的view。
- FileOwnerAttributeView: 提供支持 reading or updating a file owner 。
- UserDefinedFileAttributeView: 提供用户定义的属性的view(也叫拓展属性)
BasicFileAttributeView 被以下接口继承:
- DosFileAttributeView: Provides a view of the legacy MS-DOS/PC-DOS file attributes
- PosixFileAttributeView: Provides a view of the file attributes commonly associated with files on file systems used by operating systems that implement the Portable Operating System Interface (POSIX) family of standards.
FileOwnerAttributeView 被以下接口继承:
- AclFileAttributeView: Provides support for reading or updating a file’s ACL or file owner attributes.
- PosixFileAttributeView
PosixFileAttributeView有2个直接的父接口;它是个专门的basic file attribute view 和owner attribute view 。Figure 12-2 clarifies this relationship along with other relationships among the view hierarchy’s interfaces.
Determining View Support
开始用viw前,确保是否支持。调用 FileSystem’s Set supportedFileAttributeViews() 方法。返回FileSystem 支持的view set strings。
Listing 12-9 presents the source code to an application that outputs the names of views supported by the default FileSystem.
Listing 12-9. Outputting the Names of Default File System-Supported File Attribute Views
import java.nio.file.FileSystem;
import java.nio.file.FileSystems;
import java.util.Set;
/**
* @author @Jasu
* @date 2018-08-29 16:47
*/
public class AttributeViewDemo {
public static void main(String[] args) {
FileSystem fsDefault = FileSystems.getDefault();
Set<String> set = fsDefault.supportedFileAttributeViews();
System.out.println(set);
}
}
[owner, dos, acl, basic, user]
注意:所有FileSystems 支持 basic file attribute view 。
你也可以用Files’s V getFileAttributeView(Path path, Class type, LinkOption… options) 来做。Listing 12-10 presents an application that uses this method in a utility method context to determine view support.
import java.nio.file.Files;
import java.nio.file.Paths;
import java.nio.file.attribute.AclFileAttributeView;
import java.nio.file.attribute.BasicFileAttributeView;
import java.nio.file.attribute.FileAttributeView;
import java.nio.file.attribute.PosixFileAttributeView;
/**
* @author @Jasu
* @date 2018-08-29 16:47
*/
public class AttributeViewDemo1 {
public static void main(String[] args) {
System.out.printf("Supports basic: %b%n",
isSupported(BasicFileAttributeView.class));
System.out.printf("Supports posix: %b%n",
isSupported(PosixFileAttributeView.class));
System.out.printf("Supports acl: %b%n",
isSupported(AclFileAttributeView.class));
}
static boolean isSupported(Class<? extends FileAttributeView> clazz)
{
return Files.getFileAttributeView(Paths.get("."), clazz) != null;
}
}
Supports basic: true
Supports posix: false
Supports acl: true
FileStore’s supportsFileAttributeView() :
- boolean supportsFileAttributeView(Class type)
- boolean supportsFileAttributeView(String name)
System.out.printf("supports basic file attribute view: %b%n",
fileStore.supportsFileAttributeView(BasicFileAttributeView.class));
System.out.printf("supports basic file attribute view: %b%n",
fileStore.supportsFileAttributeView("basic"));
Exploring the Basic View
BasicFileAttributeView接口支持几个基本属性。 The following list identifies each attribute in terms of its string name and type:
- creationTime (FileTime)
- fileKey (Object)
- isDirectory (Boolean)
- isOther (Boolean)
- isRegularFile (Boolean)
- isSymbolicLink (Boolean)
- lastAccessTime (FileTime)
- lastModifiedTime (FileTime)
- size (Long)
creationTime, lastAccessTime, and lastModifiedTime 为java.nio.file.attribute.FileTime 类型,一个不可变类代表了file’s timestamp 。fileKey 是Object 其余为Boolean Long。
BasicFileAttributeView declares the following methods:
- BasicFileAttributes readAttributes(): Read the basic file attributes as a bulk operation.
- void setTimes(FileTime lastModifiedTime, FileTime lastAccessTime, FileTime creationTime): Update any or all of the file’s lastModifiedTime, lastAccessTime, and creationTime attributes.
These methods throw IOException when an I/O error occurs.
readAttributes() 返回java.nio.file.attribute.BasicFileAttributes对象提供type-safe 方法读取属性值:
- FileTime creationTime()
- Object fileKey()
- boolean isDirectory()
- boolean isOther()
- boolean isRegularFile()
- boolean isSymbolicLink()
- FileTime lastAccessTime()
- FileTime lastModifiedTime()
- long size()
注意:在一些file systems ,使用标识符或组合的标识符来唯一地标识一个文件是可能的。这样的标识符叫 file keys 。File keys 对一些操作很重要,比如在支持 symbolic links 和支持file在多个文件夹作为entry的 文件系统file tree walks 。例如,在Unix-based file systems ,device ID and information node (inode) 被普遍使用。
Reading Basic File Attribute Values in Bulk
Listing 12-11 presents the source code to an application that shows how to read a file’s basic file attributes in bulk.
Listing 12-11. Reading Basic File Attributes in Bulk
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.BasicFileAttributes;
/**
* @author @Jasu
* @date 2018-08-30 10:35
*/
public class BFAVDemo {
public static void main(String[] args) throws IOException {
Path path = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\BFAVDemo.java");
BasicFileAttributes bfa;
bfa = Files.readAttributes(path, BasicFileAttributes.class);
System.out.printf("Creation time: %s%n", bfa.creationTime());
System.out.printf("File key: %s%n", bfa.fileKey());
System.out.printf("Is directory: %b%n", bfa.isDirectory());
System.out.printf("Is other: %b%n", bfa.isOther());
System.out.printf("Is regular file: %b%n", bfa.isRegularFile());
System.out.printf("Is symbolic link: %b%n", bfa.isSymbolicLink());
System.out.printf("Last access time: %s%n", bfa.lastAccessTime());
System.out.printf("Last modified time: %s%n", bfa.lastModifiedTime());
System.out.printf("Size: %d%n", bfa.size());
}
}
通过Files’s A readAttributes(Path path, Class type, LinkOption… options) 方法获取属性。
Getting and Setting Single Basic File Attribute Values
Files声明 getAttribute() and setAttribute() 方法来获取设置单个属性:
- Object getAttribute(Path path, String attribute, LinkOption… options)
- Path setAttribute(Path path, String attribute, Object value, LinkOption… options)
LinkOption… options 对于指定symbolic link file LinkOption.NOFOLLOW_LINKS 。如果你想要最终目标的属性忽略这个参数。
属性遵循下面语法:
[view-name:]attribute-name
view-name默认是basic,attribute-name 是属性名。
Listing 12-12 presents the source code to an application that shows how to get and set single basic file attribute values.
Listing 12-12. Getting and Setting Single Basic File Attribute Values
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.FileTime;
import java.time.Instant;
/**
* @author @Jasu
* @date 2018-08-30 10:49
*/
public class BFAVDemo1 {
public static void main(String[] args) throws IOException {
Path path = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\BFAVDemo1.java");
System.out.printf("Creation time: %s%n",
Files.getAttribute(path, "creationTime"));
System.out.printf("File key: %s%n",
Files.getAttribute(path, "fileKey"));
System.out.printf("Is directory: %b%n",
Files.getAttribute(path, "isDirectory"));
System.out.printf("Is other: %b%n",
Files.getAttribute(path, "isOther"));
System.out.printf("Is regular file: %b%n",
Files.getAttribute(path, "isRegularFile"));
System.out.printf("Is symbolic link: %b%n",
Files.getAttribute(path, "isSymbolicLink"));
System.out.printf("Last access time: %s%n",
Files.getAttribute(path, "lastAccessTime"));
System.out.printf("Last modified time: %s%n",
Files.getAttribute(path, "lastModifiedTime"));
System.out.printf("Size: %d%n", Files.getAttribute(path, "size"));
Files.setAttribute(path, "lastModifiedTime",
FileTime.from(Instant.now().plusSeconds(60)));
System.out.printf("Last modified time: %s%n",
Files.getAttribute(path, "lastModifiedTime"));
}
}
Creation time: 2018-08-30T02:49:48.108115Z
File key: null
Is directory: false
Is other: false
Is regular file: true
Is symbolic link: false
Last access time: 2018-08-30T02:52:07.971115Z
Last modified time: 2018-08-30T02:53:09.08Z
Size: 1709
Last modified time: 2018-08-30T06:54:49.655Z
Tip Use BasicFileAttributeView’s setTimes() method to set the creation time, last access time, and last modified time in one method call.
Files declares several convenience methods for accessing specific basic file attributes:
- FileTime getLastModifiedTime(Path path, LinkOption… options)
- boolean isRegularFile(Path path, LinkOption… options)
- boolean isSymbolicLink(Path path)
- Path setLastModifiedTime(Path path, FileTime time)
- long size(Path path)
Exploring the DOS View
DosFileAttributeView 接口继承BasicFileAttributeView 和支持以下4个MS-DOS/PC-DOS file attributes :
- archive (Boolean)
- hidden (Boolean)
- readonly (Boolean)
- system (Boolean)
DosFileAttributeView 声明以下方法:
- DosFileAttributes readAttributes(): 读DOS file attributes 。bulk operation
- void setArchive(boolean value): Update the value of the archive attribute.
- void setHidden(boolean value): Update the value of the hidden attribute.
- void setReadOnly(boolean value): Update the value of the readonly attribute.
- void setSystem(boolean value): Update the value of the system attribute.
readAttributes() 返回java.nio.file.attribute.DosFileAttributes 对象提供type-safe methods 读取属性值:
- boolean isArchive()
- boolean isHidden()
- boolean isReadOnly()
- boolean isSystem()
Reading DOS File Attribute Values in Bulk
Listing 12-13 presents the source code to an application that shows how to read a file’s DOS file attributes in bulk.
Listing 12-13. Reading DOS File Attributes in Bulk
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.DosFileAttributes;
/**
* @author @Jasu
* @date 2018-08-30 17:19
*/
public class DFAVDemo {
public static void main(String[] args) throws IOException {
Path path = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\DFAVDemo.java");
DosFileAttributes dfa;
dfa = Files.readAttributes(path, DosFileAttributes.class);
System.out.printf("Is archive: %b%n", dfa.isArchive());
System.out.printf("Is hidden: %b%n", dfa.isHidden());
System.out.printf("Is readonly: %b%n", dfa.isReadOnly());
System.out.printf("Is system: %b%n", dfa.isSystem());
}
}
Is archive: true
Is hidden: false
Is readonly: false
Is system: false
Getting and Setting Single DOS File Attribute Values
Listing 12-14 presents the source code to an application that shows how to get and set single DOS file attribute values.
Listing 12-14. Getting and Setting Single DOS File Attribute Values
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* @author @Jasu
* @date 2018-08-30 17:19
*/
public class DFAVDemo1 {
public static void main(String[] args) throws IOException {
Path path = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\DFAVDemo1.java");
System.out.printf("Is archive: %b%n",
Files.getAttribute(path, "dos:archive"));
System.out.printf("Is hidden: %b%n",
Files.getAttribute(path, "dos:hidden"));
System.out.printf("Is readonly: %b%n",
Files.getAttribute(path, "dos:readonly"));
System.out.printf("Is system: %b%n",
Files.getAttribute(path, "dos:system"));
Files.setAttribute(path, "dos:system", true);
System.out.printf("Is system: %s%n",
Files.getAttribute(path, "dos:system"));
}
}
Is archive: true
Is hidden: false
Is readonly: false
Is system: false
Is system: true
Exploring the POSIX View
PosixFileAttributeView 接口继承BasicFileAttributeView 支持POSIX group owner and nine access permissions attributes:
- group (GroupPrincipal)
- permissions (Set
<PosixFilePermission>)
PosixFileAttributeView 声明以下方法:
- PosixFileAttributes readAttributes(): Read the POSIX file attributes as a bulk operation.
- void setGroup(GroupPrincipal group): Update the file group-owner.
- void setPermissions(Set perms): Update the file permissions.
java.nio.file.attribute.PosixFilePermission 为枚举,包含GROUP_EXECUTE, GROUP_READ, GROUP_WRITE, OTHERS_EXECUTE, OTHERS_READ, OTHERS_WRITE, OWNER_EXECUTE, OWNER_READ, and OWNER_WRITE 常量。
readAttributes() 返回java.nio.file.attribute.PosixFileAttributes 对象提供type-safe methods for reading attribute values:
- GroupPrincipal group()
- UserPrincipal owner()
- Set permissions()
空接口java.nio.file.attribute.UserPrincipal 代表an identity for determining access rights to objects in a file system and extends java.security.Principal. The empty java.nio.file.attribute. GroupPrincipal interface represents a group identity and extends UserPrincipal.
Reading POSIX File Attribute Values in Bulk
Listing 12-15 presents the source code to an application that shows how to read a file’s POSIX file attributes in bulk.
Listing 12-15. Reading POSIX File Attributes in Bulk
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.PosixFileAttributes;
import java.nio.file.attribute.PosixFilePermission;
/**
* @author @Jasu
* @date 2018-08-31 14:03
*/
public class PFAVDemo {
public static void main(String[] args) throws IOException {
Path path = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\PFAVDemo.java");
PosixFileAttributes pfa;
pfa = Files.readAttributes(path, PosixFileAttributes.class);
System.out.printf("Group: %s%n", pfa.group());
for (PosixFilePermission perm : pfa.permissions()) {
System.out.printf("Permission: %s%n", perm);
}
}
}
Getting and Setting Single POSIX File Attribute Values
Listing 12-16 presents the source code to an application that shows how to get and set single POSIX file attribute values.
Listing 12-16. Getting and Setting Single POSIX File Attribute Values
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.GroupPrincipal;
import java.nio.file.attribute.PosixFilePermission;
import java.util.Set;
/**
* @author @Jasu
* @date 2018-08-31 14:03
*/
public class PFAVDemo1 {
public static void main(String[] args) throws IOException {
Path path = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\PFAVDemo1.java");
System.out.printf("Group: %b%n",
Files.getAttribute(path, "posix:group"));
@SuppressWarnings("unchecked")
Set<PosixFilePermission> perms =
(Set<PosixFilePermission>)
Files.getAttribute(path, "posix: permissions");
for (PosixFilePermission perm: perms)
System.out.printf("Permission: %s%n", perm);
GroupPrincipal gp = path.getFileSystem().
getUserPrincipalLookupService().
lookupPrincipalByGroupName(args[1]);
Files.setAttribute(path, "posix:group", gp);
System.out.printf("Group: %b%n",
Files.getAttribute(path, "posix:group"));
}
}
To change the group attribute, you need to obtain a new GroupPrincipal object that corresponds to the specified group name command-line argument. This task is accomplished by following these steps:
- Calling Path’s FileSystem getFileSystem() method to return the FileSystem that created the Path object.
- Calling FileSystem’s UserPrincipalLookupService getUserPrincipalLookupService() method to return the java.nio.file.attribute.UserPrincipalLookupService object for obtaining UserPrincipals and GroupPrincipals.
- Calling UserPrincipalLookupService’s GroupPrincipal lookupPrincipalByGroupName(String group) method to return the desired GroupPrincipal object.
Files类声明了便捷方法来getting and setting the POSIX permissions attribute:
- Set getPosixFilePermissions (Path path, LinkOption… options)
- Path setPosixFilePermissions(Path path, Set perms)
例如:
Set<PosixFilePermission> perms =
(Set<PosixFilePermission>)
Files.getAttribute(path, "posix: permissions");
//代替
Set<PosixFilePermission> perms = Files.getPosixFilePermissions(path);
Exploring the File Owner View
很多文件系统支持file ownership 的概念。NIO.2通过FileOwnerAttributeView 接口支持,支持以下属性:
- owner (UserPrincipal)
FileOwnerAttributeView 声明以下方法访问属性:
- UserPrincipal getOwner(): Read the file owner.
- void setOwner(UserPrincipal owner): Update the file owner
Files的便捷方法:
- UserPrincipal getOwner(Path path, LinkOption… options)
- Path setOwner(Path path, UserPrincipal owner)
Note You can also access the file owner attribute via Files.getAttribute() or Files.setAttribute(). You will need to specify owner:owner for the view prefix and attribute name
Listing 12-17 presents the source code to an application that demonstrates getOwner() and setOwner().
Listing 12-17. Getting and Setting File Ownership
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.UserPrincipal;
/**
* @author @Jasu
* @date 2018-08-31 15:04
*/
public class FOAVDemo {
public static void main(String[] args) throws IOException {
Path path = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\FOAVDemo.java");
System.out.printf("Owner: %s%n", Files.getOwner(path));
UserPrincipal up = path.getFileSystem().
getUserPrincipalLookupService().
lookupPrincipalByName("Judy");
System.out.println(up);
Files.setOwner(path, up);
System.out.printf("Owner: %s%n", Files.getOwner(path));
}
}
Owner: BUILTIN\Administrators (Alias)
Judy-PC\Judy (User)
Owner: Judy-PC\Judy (User)
Note POSIXFileAttributeView extends FileOwnerAttributeView, inheriting the owner attribute. Files on a POSIX file system have a file owner in addition to a group owner and access permissions.
Exploring the ACL View
AclFileAttributeView 继承FileOwnerAttributeView 支持以下属性:
- acl (List)
AclFileAttributeView 声明以下方法访问属性:
- List getAcl(): Read the ACL into a java.util.List of java.nio.file.attribute.AclEntrys.
- void setAcl(List acl): Update (replace) the ACL.
AclEntry 类describes an entry in an ACL. It has four components:
- type ,确定条目是否授予或拒绝访问 。调用AclEntryType type() 获得。java.nio.file.attribute.AclEntryType 枚举类定义了ALARM (generate an alarm, in a system-dependent way, for the access specified in the permissions component of the ACL entry), ALLOW (explicitly grant access to a regular file or directory), AUDIT (log, in a systemdependent way, the access specified in the permissions component of the ACL entry), and DENY (explicitly deny access to a regular file or directory entry) 4个常量。
- principal, 有时叫 who 组件,是一个对应的UserPrincipal 调用UserPrincipal principal() 方法获得。
- permissions is a set of permissions. 调用Set permissions() 获得。 java.nio.file.attribute.AclEntryPermission 枚举类定义APPEND_DATA (permission to append data to a file), DELETE (permission to delete the file), DELETE_CHILD (permission to delete a file in a directory), EXECUTE (permission to execute a regular file), READ_ACL (permission to read the ACL attribute), READ_ATTRIBUTES (the ability to read nonACL file attributes), READ_DATA (permission to read the file’s data), READ_NAMED_ATTRS (permission to read the file’s named attributes), SYNCHRONIZE (permission to access the file locally at the server with synchronous reads and writes), WRITE_ ACL (permission to write the ACL attribute), WRITE_ ATTRIBUTES (the ability to write nonACL file attributes), WRITE_DATA (permission to modify the file’s data), WRITE_NAMED_ATTRS (permission to write the file’s named attributes), and WRITE_OWNER (permission to change the owner) 常量。
- flags is a set of flags that indicate how entries are inherited and propagated. 调用Set
<AclEntryFlag>flags() 获得。java.nio. file.attribute.AclEntryFlag 枚举类定义 DIRECTORY_ INHERIT (can be placed on a directory and indicates that the ACL entry should be added to each new directory created), FILE_INHERIT (can be placed on a directory and indicates that the ACL entry should be added to each new nondirectory file created), INHERIT_ONLY (can be placed on a directory but does not apply to the directory, only to newly-created files/directories as specified by the FILE_INHERIT and DIRECTORY_INHERIT flags), and NO_PROPAGATE_INHERIT (can be placed on a directory to indicate that the ACL entry should not be placed on the newly-created directory, which is inheritable by subdirectories of the created directory)
Listing 12-18 presents the source code to an application that demonstrates reading the acl and inherited owner attributes.
Listing 12-18. Reading and Outputting a File’s Owner and ACL Information
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.AclEntry;
import java.util.List;
/**
* @author @Jasu
* @date 2018-08-31 16:46
*/
public class ACLAVDemo {
public static void main(String[] args) throws IOException {
Path path = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\ManageAttribute\\ACLAVDemo.java");
System.out.printf("Owner: %s%n%n",
Files.getAttribute(path, "acl:owner"));
@SuppressWarnings("unchecked")
List<AclEntry> aclentries =
(List<AclEntry>) Files.getAttribute(path, "acl:acl");
for (AclEntry aclentry: aclentries)
System.out.printf("%s%n%n", aclentry);
}
}
Exploring the User-Defined View
使用UserDefinedFileAttributeView 接口:
- void delete(String name): Delete a user-defined attribute.
- List list(): Return a list of user-defined attribute names.
- int read(String name, ByteBuffer dst): Read the value of a user-defined attribute into a buffer.
- int size(String name): Return the size of the value of a user-defined attribute.
- int write(String name, ByteBuffer src): Write the value of a user-defined attribute from a buffer
使用 FileStore’s supportsFileAttributeView() 查看是否支持:
FileStore fs = Files.getFileStore(path);
if (!fs.supportsFileAttributeView(UserDefinedFileAttributeView.class))
System.out.println("User-defined attributes are supported.");
else
System.out.println("User-defined attributes are not supported.");
Listing 12-19 presents the source code to an application that demonstrates a user-defined file.description attribute for associating a description with a file.
Listing 12-19. Associating a Description with a File
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.UserDefinedFileAttributeView;
/**
* @author @Jasu
* @date 2018-08-31 17:10
*/
public class UDAVDemo {
public static void main(String[] args) throws IOException {
Path path = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\ManageAttribute\\UDAVDemo.java");
UserDefinedFileAttributeView udfav =
Files.getFileAttributeView(path,
UserDefinedFileAttributeView.class);
switch (args[0].charAt(0))
{
case 'W':
case 'w': udfav.write("file.description",
Charset.defaultCharset().encode("sample"));
break;
case 'L':
case 'l': for (String name: udfav.list())
System.out.println(name);
break;
case 'R':
case 'r': int size = udfav.size("file.description");
ByteBuffer buf = ByteBuffer.allocateDirect(size);
udfav.read("file.description", buf);
buf.flip();
System.out.println(Charset.defaultCharset().decode(buf));
break;
case 'D':
case 'd': udfav.delete("file.description");
}
}
}
Owner: BUILTIN\Administrators (Alias)
BUILTIN\Administrators:READ_DATA/WRITE_DATA/APPEND_DATA/READ_NAMED_ATTRS/WRITE_NAMED_ATTRS/EXECUTE/DELETE_CHILD/READ_ATTRIBUTES/WRITE_ATTRIBUTES/DELETE/READ_ACL/WRITE_ACL/WRITE_OWNER/SYNCHRONIZE:ALLOW
NT AUTHORITY\SYSTEM:READ_DATA/WRITE_DATA/APPEND_DATA/READ_NAMED_ATTRS/WRITE_NAMED_ATTRS/EXECUTE/DELETE_CHILD/READ_ATTRIBUTES/WRITE_ATTRIBUTES/DELETE/READ_ACL/WRITE_ACL/WRITE_OWNER/SYNCHRONIZE:ALLOW
NT AUTHORITY\Authenticated Users:READ_DATA/WRITE_DATA/APPEND_DATA/READ_NAMED_ATTRS/WRITE_NAMED_ATTRS/EXECUTE/READ_ATTRIBUTES/WRITE_ATTRIBUTES/DELETE/READ_ACL/SYNCHRONIZE:ALLOW
BUILTIN\Users:READ_DATA/READ_NAMED_ATTRS/EXECUTE/READ_ATTRIBUTES/READ_ACL/SYNCHRONIZE:ALLOW
Exploring the File Store View
AttributeView 也被java.nio.file.attribute. FileStoreAttributeView继承,是一个空的接口。file store 有totalSpace, unallocatedSpace, and usableSpace 属性。调用FileStore’s getAttribute() 获取属性。
getAttribute() 方法也可以带指定属性的string参数view-name:attribute-name 。对于WindowsFileStore 子类,对于totalSpace、 unallocatedSpace 和usableSpace 不需要带view name:
System.out.printf("total space: %d%n",
fileStore.getAttribute("totalSpace"));
System.out.printf("unallocated space: %d%n",
fileStore.getAttribute("unallocatedSpace"));
System.out.printf("usable space: %d%n",
fileStore.getAttribute("usableSpace"));
Note Instead of accessing totalSpace, unallocatedSpace, and usableSpace via getAttribute(), it’s better to use FileStore’s type-safe getTotalSpace(), getUnallocatedSpace(), and getUsableSpace() methods, which I demonstrated earlier in this chapter.
In contrast, you need to specify volume as the view-name when accessing the Windows-specific vsn, isRemovable, and isCdrom attributes:
System.out.printf("volume serial number: %b%n",
fileStore.getAttribute("volume:vsn"));
System.out.printf("is removable: %b%n",
fileStore.getAttribute("volume:isRemovable"));
System.out.printf("is CD-ROM: %b%n",
fileStore.getAttribute("volume:isCdrom"));
Managing Files and Directories
Paths 让你定位文件。..
Checking Paths
Files 声明2个方法表达文件存不存在:
- boolean exists(Path path, LinkOption… options): 检查path代表的文件是否存在。 By default, symbolic links are followed, but if you pass LinkOption.NOFOLLOW_LINKS to options, symbolic links are not followed.
- boolean notExists(Path path, LinkOption… options):
注意:!exists(path) 是不等于notExists(path)的。因为 !exists() 不是原子性的((executed as a single operation ),notExists() 是原子性的。当exists() 和notExists() 返回false,文件的存在不能被证实。
Files 类也声明了几个is开头的方法检查额外条件:
- boolean isDirectory(Path path, LinkOption… options): 检查path 代表文件夹。 Specify LinkOption.NOFOLLOW_LINKS when you don’t want this method to follow symbolic links
- boolean isExecutable(Path path): 检查是否可执行。
- boolean isHidden(Path path): 检查是不是隐藏文件。准确的hidden定义是依赖于操作系统的。Unix 是句号开头,Windos是不是文件夹和 DOS hidden attribute 。
- boolean isReadable(Path path): 检查是否可读,
- boolean isRegularFile(Path path, LinkOption… options): 检查是否是常规文件。
- boolean isSameFile(Path path1, Path path2): 检查是不是同一个文件。如果是两个 file system providers ,返回false。
- boolean isWritable(Path path): 检查是否可写。
isExecutable(), isReadable(), and isWritable() 检查文件是否存在,JVM有读写执行权限。根据实现,方法可能需要读取 file permissions, ACLs, or other file attributes to check the effective access to the file。因此,对于其他操作系统方法可能不是原子性的。
exists(), notExists(), isExecutable(), isReadable(), and isWritable() 的返回值是立即过时的。这个race condition 被叫做time-of-check-to-time-of-use (TOCTTOU) 。Check out https:// en.wikipedia.org/wiki/Time_of_check_to_time_of_use for more information.
Listing 12-20 presents the source code to an application that demonstrates these path-checking methods.
Listing 12-20. Checking Paths for Various Conditions
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* @author @Jasu
* @date 2018-08-31 17:52
*/
public class FilesAndDirectoriesDemo {
public static void main(String[] args) {
Path path1 = Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\FilesAndDirectoriesDemo.java");
System.out.printf("Path1: %s%n", path1);
System.out.printf("Exists: %b%n", Files.exists(path1));
System.out.printf("Not exists: %b%n", Files.notExists(path1));
System.out.printf("Is directory: %b%n", Files.isDirectory(path1));
System.out.printf("Is executable: %b%n", Files.isExecutable(path1));
try
{
System.out.printf("Hidden: %b%n", Files.isHidden(path1));
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
System.out.printf("Is readable: %b%n", Files.isReadable(path1));
System.out.printf("Is regular file: %b%n",
Files.isRegularFile(path1));
System.out.printf("Is writable: %b%n",
Files.isWritable(path1));
try {
System.out.println("Is Same" + Files.isSameFile(path1, Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\FileStoreDemo.java")));
} catch (IOException e) {
e.printStackTrace();
}
}
}
Path1: E:\SpringSourceCode\src\main\java\com\jasu\nio\_12_NIO2\_02_Files\FilesAndDirectoriesDemo.java
Exists: true
Not exists: false
Is directory: false
Is executable: true
Hidden: false
Is readable: true
Is regular file: true
Is writable: true
Is Samefalse
Creating Files
通过Files的Path createFile(Path path, FileAttribute… attrs) 创建文件。需要指定path 和属性。
attrs 参数指定了属性对象列表。属性实现了java.nio.file.attribute.FileAttribute 接口。
createFile() 成功返回文件的Path。可抛出UnsupportedOperationException java.nio.file. FileAlreadyExistsException 。IOException 。
注意:FileAlreadyExistsException 是一个optional specific exception 。底层操作系统检测特定error导致这个异常。如果error没被检测,抛出IOException 。
Listing 12-21 presents the source code to an application that demonstrates createFile() without file attributes.
Listing 12-21. Creating an Empty File
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* @author @Jasu
* @date 2018-08-31 17:52
*/
public class FilesAndDirectoriesDemo {
public static void main(String[] args) throws IOException {
createFiles();
}
static void createFiles() throws IOException {
Files.createFile(Paths.get("C:/a.jpg"));
}
}
Creating and Deleting Temporary Files
应用经常需要创建和使用临时常规文件。例如,内存密集型视频编辑应用。以及外部排序的应用。
你可以用2种方法创建临时文件:
- Path createTempFile(Path dir, String prefix, String suffix, FileAttribute… attrs)
- Path createTempFile(String prefix, String suffix, FileAttribute… attrs)
第一个方法创建在dir 文件夹,第二个创建在默认的临时文件夹( java.io.tmpdir )。当suffix 是null,为.tmp。
成功返回Path。
Listing 12-22 presents the source code to an application that demonstrates the first createTempFile() method (without file attributes).
Listing 12-22. Creating an Empty Temporary File
public class FilesAndDirectoriesDemo {
public static void main(String[] args) throws IOException {
System.out.println(System.getProperty("java.io.tmpdir"));
}
static void createTempFiles() throws IOException {
Files.createTempFile("test", null);
}
}
test6818290517221982513.tmp
Demo运行完临时文件不消失,不用最好删除,3种方式:
- Add a shutdown hook (一种运行时机制,JVM关闭前清楚资源或保存数据),通过java.lang.Runtime 的addShutdownHook(Thread hook) 方法。
- 转变返回的Path为File,调用deleteOnExit()
- 使用Files类的newOutputStream() 方法和 NIO.2’s DELETE_ON_CLOSE 常数。
示例
static void createTempFiles() throws IOException {
Path path = Files.createTempFile("test", null);
path.toFile().deleteOnExit();
}
Reading Files
Files类支持读取常规文件内容,声明下面的方法读取所有字节或文本到内存:
- byte[] readAllBytes(Path path)
- List readAllLines(Path path)
- List readAllLines(Path path, Charset cs)
readAllBytes(Path path) 读取文件内容返回字节数组。确保读取完毕后关闭文件。OutOfMemoryError (超过2G)。用于简单的场景,不用于读取大文件。
readAllLines(Path path) ,等同于readAllLines(path, java.nio.charset.StandardCharsets.UTF_8);. 。
readAllLines(Path path, Charset cs) 指定编码。用于简单的操作,不用于读大文件。
Listing 12-24 describes an application that uses readAllLines(Path path) to read all lines from a text file. These lines are subsequently output.
Listing 12-24. Dumping a Text File to the Standard Output Stream
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
/**
* @author @Jasu
* @date 2018-09-03 15:39
*/
public class ReadingFilesDemo {
public static void main(String[] args) throws IOException {
List<String> stringList = Files.readAllLines(Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\ReadingFilesDemo.java"));
for (String s : stringList) {
System.out.println(s);
}
}
}
If you try to dump a binary file, you will probably discover a java.nio.charset.MalformedInputException message instead.
前面的方法仅限于将较小的文件读入内存。 对于大文件,Files提供下面的方法:
- BufferedReader newBufferedReader(Path path)
- BufferedReader newBufferedReader(Path path, Charset cs)
- InputStream newInputStream(Path path, OpenOption… options)
newBufferedReader(Path path) 等同于 Files.new BufferedReader(path, StandardCharsets.UTF_8) 。
newBufferedReader(Path path, Charset cs) 返回java.io.BufferedReader (with the default buffer size) ,指定编码。
newInputStream(Path path, OpenOption… options) 返回java.io.InputStream ,stream 不会被buffered,不用支持mark()或者reset()。stream 对多线程的访问是安全的。从头开始读。
可以传入java.nio.file.OpenOptions的可变参数列表。这些options配置了如何创建和打开文件。java.nio.file. StandardOpenOption 枚举类实现了这个接口并提供下面的常量:
- APPEND: 如果文件为了写打开,写字节到文件末尾而不是开头
- CREATE 文件不存在就创建文件
- CREATE_NEW: 创建新文件,文件存在时失败
- DELETE_ON_CLOSE: 当file关闭时,最大努力删除文件。
- DSYNC: 要求每次对文件内容的更新同步到底层储存设备
- READ: Open the file for read access.
- SPARSE: Open a sparse file (https://en.wikipedia.org/ wiki/Sparse_file). 当使用CREATE_NEW,SPARSE提供了一个暗示,新建的文件是sparse。操作系统不支持会忽略。
- SYNC: 要求文件内容或者metadata的更新同步到底层储存设备。
- TRUNCATE_EXISTING: Truncate 存在的用WRITE访问打开的文件的长度到0。
- WRITE: Open the file for write access.
不是全都适用 newInputStream() ,一些适用 newOutputStream() 。
Listing 12-25 describes an application that demonstrates newBufferedReader(Path path).
Listing 12-25. Dumping a Text File to the Standard Output Stream, Revisited
import java.io.BufferedReader;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
/**
* @author @Jasu
* @date 2018-09-03 16:34
*/
public class NewBufferedReaderDemo {
public static void main(String[] args) throws IOException {
BufferedReader reader = Files.newBufferedReader(Paths.get("E:\\SpringSourceCode\\src\\main\\java\\com\\jasu\\nio\\_12_NIO2\\_02_Files\\NewBufferedReaderDemo.java"));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
}
}
Writing Files
Files提供了写字节或文本的方法:
- Path write(Path path, byte[] bytes, OpenOption… options)
- Path write(Path path, Iterable lines, Charset cs, OpenOption… options)
- Path write(Path path, Iterable lines, OpenOption… options)
write(Path path, byte[] bytes, OpenOption… options) 写字节到path。如果没传入就是 CREATE, TRUNCATE_EXISTING, and WRITE 。
write(Path path, Iterable lines, Charset cs, OpenOption… options) 写lines到path。系统指定的换行符line.separator 。指定了编码。没传option为 CREATE, TRUNCATE_EXISTING, and WRITE 。
write(Path path, Iterable lines, OpenOption… options) behaves as if you specified Files.write(path, lines, StandardCharsets.UTF_8, options);.
Listing 12-26 describes an application that reads a web page and saves its HTML text to a file named page.html.
Listing 12-26. Saving Web Page HTML to a Text File
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
/**
* @author @Jasu
* @date 2018-09-03 16:50
*/
public class NewBufferedWriterDemo {
public static void main(String[] args) throws IOException {
URL url = new URL("https://www.baidu.com");
InputStreamReader inputStreamReader = new InputStreamReader(url.openStream());
BufferedReader reader = new BufferedReader(inputStreamReader);
List<String> lines = new ArrayList<>();
String line;
while ((line = reader.readLine()) != null) {
lines.add(line);
}
Files.write(Paths.get("C:/page.html"), lines);
}
}
前面的方法限制于写小数量的内容到文件。对于大量内容,Files提供下面的方法:
- BufferedWriter newBufferedWriter(Path path, Charset cs, OpenOption… options)
- BufferedWriter newBufferedWriter(Path path, OpenOption… options)
- OutputStream newOutputStream(Path path, OpenOption… options)
newBufferedWriter(Path path, Charset cs, OpenOption… options) 打开或创建一个文件,返回java.io.BufferedWriter (with the default buffer size) 。指定了编码。默认option为 CREATE, TRUNCATE_EXISTING, and WRITE 。
newBufferedWriter(Path path, OpenOption… options) behaves as if you specified Files.newBufferedWriter(path, StandardCharsets.UTF_8, options);
newOutputStream(Path path, OpenOption… options) 返回java.io.OutputStream 。stream 不被buffered,写是线程安全的。默认option为 CREATE, TRUNCATE_EXISTING, and WRITE 。
Listing 12-27 describes an application that demonstrates newBufferedWriter(Path path, OpenOption… options).
Listing 12-27. Saving Web Page HTML to a Text File, Revisited
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
/**
* @author @Jasu
* @date 2018-09-03 16:50
*/
public class NewBufferedWriterDemo {
public static void main(String[] args) throws IOException {
URL url = new URL("https://www.baidu.com");
InputStreamReader inputStreamReader = new InputStreamReader(url.openStream());
BufferedReader reader = new BufferedReader(inputStreamReader);
BufferedWriter writer = Files.newBufferedWriter(Paths.get("C:/page.html"));
List<String> lines = new ArrayList<>();
String line;
while ((line = reader.readLine()) != null) {
writer.write(line, 0, line.length());
writer.newLine();
}
writer.close();
}
}
Randomly Accessing Files
第三章介绍了java.io.RandomAccessFile 。NIO.2 提供了等价的java.nio.channels.SeekableByteChannel 接口。
SeekableByteChannel 继承java.nio.channels.ByteChannel 接口,描述一个byte channel 维护一个当前position,允许position被改变。Table 12-1 presents its methods.
Table 12-1. The Methods That Define a Seekable Byte Channel
| Method | Description |
|---|---|
| long position() | 返回该channel的position, 从seekable entity的起始位置到当前位置的非负字节计数。 |
| SeekableByteChannel position(long newPosition) | 设置channel的position到newPosition。设置position超出当前size是合法的,不会改变实体的size。 |
| int read(ByteBuffer dst) | Read a sequence of bytes from this channel into the given buffer. |
| long size() | Return the current size (in bytes) of the entity to which this channel is connected. |
| SeekableByteChannel truncate(long size) | Truncate the entity to which this channel is connected to size. |
| int write(ByteBuffer src) | Write a sequence of bytes to this channel from the given buffer |
JDK 7 重构java.nio.channels.FileChannel 实现了SeekableByteChannel 。SeekableByteChannel 文档建议方法返回的类型实现了SeekableByteChannel ,然后chain在一起。
Files类让你接收SeekableByteChannel :
- SeekableByteChannel newByteChannel(Path path, OpenOption… options)
- SeekableByteChannel newByteChannel(Path path, Set options, FileAttribute… attrs)
I’ve created an application that demonstrates SeekableByteChannel in a FileChannel context and also in a more generic context. Listing 12-28 presents the application’s source code.
Listing 12-28. Demonstrating SeekableByteChannel
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.channels.SeekableByteChannel;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.EnumSet;
import static java.nio.file.StandardOpenOption.*;
/**
* @author @Jasu
* @date 2018-09-04 11:15
*/
public class SeekableByteChannelDemo {
final static int REC_LEN = 50;
public static void main(String[] args) throws IOException {
Path path = Paths.get("emp");
FileChannel fc;
fc = FileChannel.open(path, CREATE, WRITE, SYNC).position(REC_LEN * 2);
ByteBuffer buffer = ByteBuffer.wrap("John Smith".getBytes());
fc.write(buffer);
buffer.clear();
SeekableByteChannel sbc;
sbc = Files.newByteChannel(path, EnumSet.of(READ)).position(REC_LEN * 2);
sbc.read(buffer);
sbc.close();
System.out.println(new String(buffer.array()));
}
}
先创建path,然后在文件上open一个channel。
注意:NIO.2添加了FileChannel open(Path path, OpenOption… options) and FileChannel open(Path path, Set options, FileAttribute… attrs)方法到FileChannel类,你不需要依赖传统i/o方式得到file channel。
open()方法带有CREATE, WRITE, SYNC options。
成功获得 seekable file channel后,main() 在channel调用position()设置读取position,2倍的recode(假设emp是a flat file database,被分隔为records,每个record 长度为REC_LEN)。
调用java.nio.ByteBuffer’s ByteBuffer wrap(byte[] array) 方法包装字节数组,buffer然后写入到channel,然后关闭。emp文件应该在100的位置开始有字节序列。
然后newByteChannel() and SeekableByteChannel。不把FileChannel硬编码在源码,使用SeekableByteChannel更有利。
关闭seekable byte channel后,调用ByteBuffer’s byte[] array()返回字节数组。放入new String。
Creating Directories
调用 Files类的Path createDirectory(Path dir, FileAttribute… attrs)方法。当创建文件夹,指定path和属性的可变参数列表。
createDirectory()成功返回path。
Listing 12-29 presents the source code to an application that demonstrates createDirectory() without file attributes.
Listing 12-29. Creating an Empty Directory
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
/**
* @author @Jasu
* @date 2018-09-04 17:05
*/
public class CreateDirectoriesDemo {
public static void main(String[] args) throws IOException {
Files.createDirectory(Paths.get("C:/test"));
}
}
使用 Path createDirectories(Path dir, FileAttribute…attrs)创建层级文件夹。不会抛FileAlreadyExistsException。
FileAttribute是PosixFilePermissions class’s File Attribute> asFileAttribute(Set perms)的返回类型。你可以在POSIX file system上这么做:
Set<PosixFilePermission> perms =
PosixFilePermissions.fromString("rw-------");
FileAttribute<Set<PosixFilePermission>> fa =
PosixFilePermissions.asFileAttribute(perms);
Files.createDirectory(Paths.get("images"), fa);
Creating and Deleting Temporary Directories
创建临时文件夹:
- Path createTempDirectory(Path dir, String prefix, FileAttribute… attrs)
- Path createTempDirectory(String prefix,FileAttribute… attrs)
第二个创建在系统属性java.io.tmpdir文件夹,成功返回path。
Listing 12-30 presents the source code to an application that demonstrates the first createTempDirectory() method (without file attributes).
Listing 12-30. Creating an Empty Temporary Directory
Files.createTempDirectory(Paths.get("C:/test"), "test");
程序执行结束,临时文件夹还在,2种方法删除:
- Add a shutdown hook via the Runtime class’s void addShutdownHook(Thread hook) method.
- Convert the returned Path object to a File object (via Path’s toFile() method) and invoke File’s void deleteOnExit() method on the File object.
Listing 12-31 expands on Listing 12-30 by using a shutdown hook to remove a temporary directory before the JVM shuts down.
Listing 12-31. Using a Shutdown Hook to Remove a Temporary Directory on JVM Exit
Path path = Files.createTempDirectory(Paths.get("C:/test"), "test");
Runtime.getRuntime().addShutdownHook(new Thread(()->{
try {
Files.delete(path);
} catch (IOException e) {
e.printStackTrace();
}
}));
}
Listing Directory Content
NIO.2提供了java.nio.file.DirectoryStream<T>接口来得到文件夹条目。DirectoryStream继承java.lang.Iterable。
DirectoryStream也继承java.io.Closeable,它继承java.lang.AutoCloseable。因此可以用 try-with-resources自动关闭directory stream。
注意:当不使用try-with-resources,迭代后调用directory stream的close()方法释放打开文件夹持有的资源。stream当程序结束自动关闭。
DirectoryStream继承了 Iterable’s Iterator iterator()方法。声明了内置的Filter<T>接口。
调用Files类的下面方法获取DirectoryStream:
- DirectoryStream newDirectoryStream(Path dir)
- DirectoryStream newDirectoryStream(Path dir, DirectoryStream.Filter filter)
- DirectoryStream newDirectoryStream(Path dir, String glob)
Listing 12-32 presents an application that obtains and outputs all entries in the specified directory.
Listing 12-32. Obtaining and Outputting All Entries in a Directory
Path path = Paths.get("C:/windows");
DirectoryStream<Path> paths = Files.newDirectoryStream(path, p->p.getFileName().toString().endsWith("exe"));
for (Path path1 : paths) {
System.out.println(path1);
}
没有用try-with-resource,因为执行完就结束了。传入了一个filter(lambda)。
newDirectoryStream(Path dir, String glob),使用 globbing pattern。
try (DirectoryStream<Path> ps = Files.newDirectoryStream(path, "*.exe")) {
for (Path p : ps) {
System.out.println(p);
}
} catch (Exception e) {
e.printStackTrace();
}
Copying Files
File类的一个痛点就是没有copy()方法。Files提供了:
-
long copy(InputStream in, Path target, CopyOption… options): Copy from a classic I/O input stream to a path.
- long copy(Path source, OutputStream out): Copy from a path to a classic I/O output stream.
- Path copy(Path source, Path target, CopyOption… options): Copy from one path to another.
第一个方法复制所有字节到path。On return, the input stream will be at end-of-stream.
可能会传入 java.nio.file.CopyOption可变参数。java.nio.file.StandardCopyOption枚举类实现了接口提供下面的常量。
- ATOMIC_MOVE:作为一个原子文件系统操作执行move。copy方法不使用这个参数,在复制上下文没意义。
- COPY_ATTRIBUTES: 复制属性与内容
- REPLACE_EXISTING: 替换存在的目标
LinkOption也实现了CopyOption,它提供了NOFOLLOW_LINKS常量(don’t follow symbolic links)。
默认,当目标存在或是symbolic link,复制操作失败。如果指定 REPLACE_EXISTING,目标也存在了,目标会被替换(除非是非空文件夹)。如果target存在且是symbolic link,符号连接被替换。
返回读/写的字节数。
Caution: 如果读写发生i/o错误,导致输入流不在end-of-stream,可能处于不一致状态。强烈建议发生I/O错误马上关闭输入流。
Listing 12-35 refactors Listing 12-27’s SavePage application to use copy(InputStream in, Path target, CopyOption… options) to copy a web page to a file
Listing 12-35. Saving Web Page HTML via copy(InputStream, Path, CopyOption…)
第二个方法从path复制字节到输出流。如果给定输出流是 flushable的,这个方法结束时要调用flush(),可以flush到任何buffered输出。方法返回读或写的字节数。
Caution: 读、写的时候发生I/O错误,强烈建议在I/O错误后关输出流。
Listing 12-36 presents the source code to an application that copies all bytes from a source path to a file output stream.
Listing 12-36. Copying from a Source Path to a File Output Stream
Files.copy(Paths.get("page.html"), new FileOutputStream("copy.bak"));
第三个方法从path到path,默认target存在或者是一个符号连接操作会失败。然而,当source和target一样,不执行复制。
一些额外注意的地方:
- 属性不一定需要辅助到目标
- 当支持符号连接,source是一个符号连接,连接的最终目标被复制。
你可能需要指定下面的复制属性: -
- COPY_ATTRIBUTES:
- NOFOLLOW_LINKS: 不跟踪符号连接。当source是符号连接,链接本事被复制,而不是连接指向的目标。COPY_ATTRIBUTES在复制符号连接时忽略。
- REPLACE_EXISTING: target存在时,覆盖target
方法返回path。
Listing 12-37 presents the source code to an application that copies all bytes from a source path to a target path.
Listing 12-37. Copying from a Source Path to a Target Path
Files.copy(Paths.get("page.html"), Paths.get("copy.bak"), StandardCopyOption.REPLACE_EXISTING);
Moving Files
文件移动也是File类的痛点,Files提供了 Path move(Path source, Path target, CopyOption… options)。
当target存在移动失败,除非source和target同名,这种情况下方法无效。如果source是符号链接,移动的符号而不是target。
支持下面的移动option:
- ATOMIC_MOVE:这个move作为一个原子文件系统操作执行,所有其他option都被忽略。当target存在,要么被替换要么抛异常。
- REPLACE_EXISTING: target存在被替换(非空文件夹不替换)。如果是符号链接就是移动的符号链接,不是链接的target。
move会复制 lastModifiedTime属性到target。复制时间戳可能导致精度损失。move()的实现也可能尝试复制其他属性。当它们不能被复制时,不需要失败。
注意:move可以用于移动空文件夹。当移动非空文件夹,当目录不需要移动文件夹的条目时,就会移动文件夹。当需要移动条目,方法失败。
Files.move(Paths.get("page.html"), Paths.get("p.html"));
Deleting Files
Files删除的2个方法:
- void delete(Path path)
- boolean deleteIfExists(Path path)
delete(Path path),如果是文件夹,必须是空的。如果是符号链接,删除的符号链接,不是target。
deleteIfExists(Path path),如果是符号链接,删除链接。当被删除返回true;否则false。
Listing 12-39 presents the source code to an application that demonstrates deleteIfExists().
Listing 12-39. Deleting a File When It Exists
Files.deleteIfExists(Paths.get("page.html"));
Managing Symbolic and Hard Links
文件系统储存文件,文件夹,和links,链接是指向其他真实文件,文件夹,或者其他链接的文件。links分为符号(软)链接和硬链接。Files有几个方法管理符号链接,也提供了一个创建硬链接的方法。
Managing Symbolic Links
符号链接是引用其他文件的特殊文件。 Figure 12-3 illustrates a symbolic link
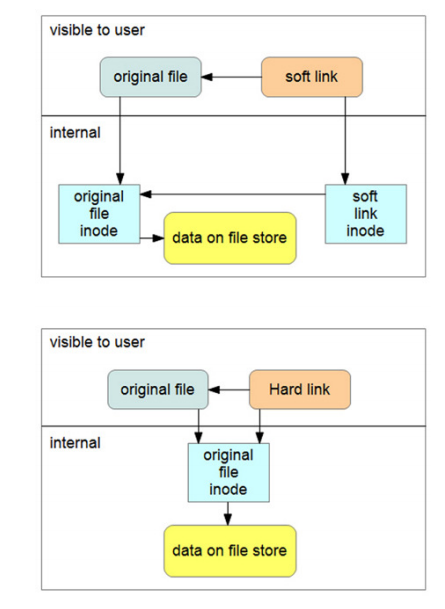
许多文件系统广泛使用符号链接。然后,符号链接可能产生一个循环引用。当递归地遍历文件树时,循环引用可能会有问题,这是将在本章后面讨论。然而,NIO.2’s file tree-walking考虑到了这点。
Files类提供Path createSymbolicLink(Path link, Path target, FileAttribute… attrs)方法对target创建符号连接。
Listing 12-40 presents the source code to an application that demonstrates symbolic link creation.
Listing 12-40. Creating a Symbolic Link
Files.createSymbolicLink(Paths.get("D:/clicker"), Paths.get("D:/clicker.link"));
Files.isSymbolicLink(Paths.get("D:/clicker.link"));
isSymbolicLink是否是符号链接。
readSymbolicLink(Path link)读取符号连接的target。成功返回target的Path。
Files.readSymbolicLink(Paths.get("D:/clicker.link"));
Managing Hard Links
硬链接是一个目录条目,它将名字与文件系统上的文件关联起来。它基本上和原始文件是一样的。所有属性都是相同的:它们具有相同的文件权限、时间戳等。图12-4区分了软链接和硬链接。

上面是用户感知,下面是实际情况。
对于一个软链接,文件指向一个inode,而软链接指向另一个inode。软链接inode引用文件inode,它指向文件存储中的数据。于一个硬链接,文件和硬链接都指向文件inode,指向文件存储中的数据。
硬链接比软链接更有限制:
- 链接的目标必须存在。
- 目录中通常不允许硬链接。
- 硬链接不允许跨分区或卷。换句话说,它们不能跨文件系统存在。
- 一个硬链接看起来和行为就像一个普通的文件,所以很难找到。
Files类提供Path createLink(Path link, Path existing)方法创建硬链接。
Listing 12-43 presents the source code to an application that demonstrates hard link creation.
Listing 12-43. Creating a Hard Link
Files.createLink(Paths.get(args[0]), Paths.get(args[1]));
Walking the File Tree
Files类的copy(), move(), and delete()不能处理多个对象。当结合 NIO.2’s File Tree-Walking API,可以处理层级文件。
Exploring the File Tree-Walking API
File Tree-Walking API能让你walk a file tree和访问它的所有文件 (regular files, directories, and links)。除了提供执行walk的私有实现,也给应用提供了public接口。
public接口的中心是java.nio.file.FileVisitor<T>,被描述为一个visitor。在walk时,File Tree-Walking的实现调用接口的方法通知visitor遇到了文件和提供其他通知:
- FileVisitResult postVisitDirectory(T dir, IOException ioe)
- FileVisitResult preVisitDirectory(T dir, BasicFileAttributes attrs)
- FileVisitResult visitFile(T file, BasicFileAttributes attrs)
- FileVisitResult visitFileFailed(T file, IOException ioe)
每个方法带有应用代码可以查询的参数被调用。当方法完成,返回声明在java.nio.file.FileVisitResult枚举类型之一:
- CONTINUE: 继续walk。当从preVisitDirectory()返回,表明文件夹的目录也要被访问。
- SKIP_SIBLINGS:继续,不访问文件的兄弟姐妹。如果从preVisitDirectory()返回,文件夹的目录也被跳过, postVisitDirectory() 不被调用。
- SKIP_SUBTREE:不访问文件夹的目录,继续。只从 preVisitDirectory()返回才有用。否则和 CONTINUE一样。
- TERMINATE:终结walk。
FileVisitResult postVisitDirectory(T dir, IOException ioe)用于目录dir调用,在文件夹的目录和所有子节点被访问后。当目录迭代提前完成,也会被调用(通过 visitFile()返回 SKIP_SIBLINGS或遍历目录的I/O错误)。当文件夹迭代无错误完成,ioe为null;否则是异常。
FileVisitResult preVisitDirectory(T dir, BasicFileAttributes attrs)用于文件夹dir调用,在文件夹的目录被访问之前。如果返回CONTINUE,文件夹的目录被访问。如果返回 SKIP_SUBTREE or SKIP_SIBLINGS,文件夹里的目录或者子节点不会访问。对于SKIP_SIBLINGS,postVisitDirectory()不被调用。传给attrs的值表明了文件夹的基础属性。
FileVisitResult visitFile(T file, BasicFileAttributes attrs)用于文件夹里面的非文件夹文件调用。attrs代表文件基础属性。
FileVisitResult visitFileFailed(T file, IOException ioe)用于不能被访问文件的调用,因为属性不能被读取,是文件夹不能打开,或者其他的原因。ioe代表阻止访问file的异常。
Each method throws IOException when an I/O error occurs.
java.nio.file.SimpleFileVisitor<T>类实现了所有4个方法,提供访问所有文件和重新抛出i/o错误的默认行为。除了visitFileFailed()每个方法返回 CONTINUE;visitFileFailed()重新抛出导致无法访问的异常。
SimpleFileVisitor声明了protected构造器,不能直接实例化。必须继承SimpleFileVisitor,如下:
class DoNothingVisitor extends SimpleFileVisitor<Path> {
}
实现visitor类后,传递这个类的实例和一个Path对象到下面的方法:
Path walkFileTree(Path start, FileVisitor<? super Path> visitor)
方法启动一个整个root为start的file tree的depth-first的walk。需要时调用visitor的方法。如果其中一个抛异常,walkFileTree()也抛异常。下面的例子展示了从当前目录开始的walk:
Files.walkFileTree(Paths.get("."), new DoNothingVisitor());
Don’t expect to see any output. Instead, you will need to codify the visitor methods to generate output. This task is demonstrated in Listing 12-44.
Listing 12-44. Visiting a File Tree and Reporting Last Modified Times and Sizes
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
/**
* @author @Jasu
* @date 2018-09-11 17:29
*/
public class FileWalkDemo {
public static void main(String[] args) throws IOException {
Files.walkFileTree(Paths.get("D:/bin"), new DoNothingFileVisitor());
}
static class DoNothingFileVisitor extends SimpleFileVisitor<Path> {
/**
* Initializes a new instance of this class.
*/
protected DoNothingFileVisitor() {
super();
}
/**
* Invoked for a directory before entries in the directory are visited.
*
* <p> Unless overridden, this method returns {@link FileVisitResult#CONTINUE
* CONTINUE}.
*
* @param dir
* @param attrs
*/
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.printf("preVisitDirectory: %s%n", dir);
System.out.printf(" lastModifiedTime: %s%n",
attrs.lastModifiedTime());
System.out.printf(" size: %d%n%n", attrs.size());
return super.preVisitDirectory(dir, attrs);
}
/**
* Invoked for a file in a directory.
*
* <p> Unless overridden, this method returns {@link FileVisitResult#CONTINUE
* CONTINUE}.
*
* @param file
* @param attrs
*/
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.printf("visitFile: %s%n%n", file);
System.out.printf(" lastModifiedTime: %s%n",
attrs.lastModifiedTime());
System.out.printf(" size: %d%n%n", attrs.size());
return super.visitFile(file, attrs);
}
/**
* Invoked for a file that could not be visited.
*
* <p> Unless overridden, this method re-throws the I/O exception that prevented
* the file from being visited.
*
* @param file
* @param exc
*/
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException {
System.out.printf("visitFileFailed: %s %s%n%n", file, exc);
return super.visitFileFailed(file, exc);
}
/**
* Invoked for a directory after entries in the directory, and all of their
* descendants, have been visited.
*
* <p> Unless overridden, this method returns {@link FileVisitResult#CONTINUE
* CONTINUE} if the directory iteration completes without an I/O exception;
* otherwise this method re-throws the I/O exception that caused the iteration
* of the directory to terminate prematurely.
*
* @param dir
* @param exc
*/
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
System.out.printf("postVisitDirectory: %s %s%n%n", dir, exc);
return super.postVisitDirectory(dir, exc);
}
}
}
walkFileTree(Path start, FileVisitor visitor)方法是下面方法的快捷方式:
Path walkFileTree(Path start, Set<FileVisitOption> options, int maxDepth,
FileVisitor<? super Path> visitor)
不仅需要path和visitor,也要options和int。FileVisitOption是声明文件访问选项常数的枚举。当前仅支持的选项是FOLLOW_LINKS(follow symbolic links)。int代表的是walk的最大文件夹层级。Integer.MAX_VALUE表明walk到底。
如果options参数有 FOLLOW_LINKS option,方法跟踪访问的文件夹,因此可以检测cycle。cycle出现在文件夹的入口是文件夹的祖先。Cycle检测是通过记录文件夹的keys执行的,或者当keys不可用时,调用 isSameFile()来测试是否是祖先文件。当检测到cycle,被认为是 I/O error, visitFileFailed()被调用,带有java.nio.file.FileSystemLoopException参数。
The former walkFileTree() method invokes this walkFileTree() method as follows (it doesn’t follow symbolic links and visits all levels of the file tree):
walkFileTree(start, EnumSet.noneOf(FileVisitOption.class),
Integer.MAX_VALUE, visitor)
Copying a File Tree
The File Tree-Walking API can be used to copy a file tree. Listing 12-45 presents the source code to an application that accomplishes this task.
Listing 12-45. Copying a File Tree
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.EnumSet;
/**
* @author @Jasu
* @date 2018-09-11 18:00
*/
public class CopyFileTreeDemo {
public static void main(String[] args) throws IOException {
Path source = Paths.get("D:/Bin");
Path target = Paths.get("D:/BinCp");
if (!Files.exists(source)) {
System.err.printf("%s source path doesn't exist%n", source);
return;
}
if (!Files.isDirectory(source)) // Is source a nondirectory?
{
if (Files.exists(target))
if (Files.isDirectory(target)) // Is target a directory?
target = target.resolve(source.getFileName());
try {
Files.copy(source, target, StandardCopyOption.REPLACE_EXISTING);
} catch (IOException ioe) {
System.err.printf("I/O error: %s%n", ioe.getMessage());
}
return;
}
if (Files.exists(target) && !Files.isDirectory(target)) // Is target an existing file?
{
System.err.printf("%s is not a directory%n", target);
return;
}
EnumSet<FileVisitOption> options
= EnumSet.of(FileVisitOption.FOLLOW_LINKS);
CopyVisitor copier = new CopyVisitor(source, target);
Files.walkFileTree(source, options, Integer.MAX_VALUE, copier);
}
public static class CopyVisitor extends SimpleFileVisitor<Path> {
private Path fromPath;
private Path toPath;
private StandardCopyOption copyOption = StandardCopyOption.REPLACE_EXISTING;
public CopyVisitor(Path fromPath, Path toPath) {
this.fromPath = fromPath;
this.toPath = toPath;
}
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.println("dir = " + dir);
System.out.println("fromPath = " + fromPath);
System.out.println("toPath = " + toPath);
System.out.println("fromPath.relativize(dir) = " +
fromPath.relativize(dir));
System.out.println("toPath.resolve(fromPath.relativize(dir)) = " +
toPath.resolve(fromPath.relativize(dir)));
Path targetPath = toPath.resolve(fromPath.relativize(dir));
if (!Files.exists(targetPath))
Files.createDirectory(targetPath);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("file = " + file);
System.out.println("fromPath = " + fromPath);
System.out.println("toPath = " + toPath);
System.out.println("fromPath.relativize(file) = " +
fromPath.relativize(file));
System.out.println("toPath.resolve(fromPath.relativize(file)) = " +
toPath.resolve(fromPath.relativize(file)));
Files.copy(file, toPath.resolve(fromPath.relativize(file)),
copyOption);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException {
System.err.println(exc);
return super.visitFileFailed(file, exc);
}
}
}
Deleting a File Tree
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
/**
* @author @Jasu
* @date 2018-09-12 17:14
*/
public class DeletingFileTreeDemo {
public static void main(String[] args) throws IOException {
Path path = Files.walkFileTree(Paths.get("D:/BinCp"), new DeleteVisitor());
}
static class DeleteVisitor extends SimpleFileVisitor<Path> {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
Files.deleteIfExists(file);
return super.visitFile(file, attrs);
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
Files.deleteIfExists(dir);
return super.postVisitDirectory(dir, exc);
}
}
}
Note Delete is designed to delete symbolic links and not their targets.
Moving a File Tree
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
/**
* @author @Jasu
* @date 2018-09-12 17:25
*/
public class MovingFileTreeDemo {
public static void main(String[] args) throws IOException {
Files.walkFileTree(Paths.get("F:\\store"), new MoveVisitor(Paths.get("F:\\store"), Paths.get("F:\\storage")));
}
static class MoveVisitor extends SimpleFileVisitor<Path> {
private Path from, to;
public MoveVisitor(Path from, Path to) {
this.from = from;
this.to = to;
}
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
Files.copy(dir, to.resolve(from.relativize(dir)));
return super.preVisitDirectory(dir, attrs);
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
Files.move(file, to.resolve(from.relativize(file)));
return super.visitFile(file, attrs);
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
Files.delete(dir);
return super.postVisitDirectory(dir, exc);
}
}
}
Working with Additional Capabilities
Files类方法大概全了,还剩一组方法。这些方法是用于Java 8’s Streams API and lambda expressions的。
- Stream find(Path start, int maxDepth,BiPredicate matcher,FileVisitOption… options)
- Stream lines(Path path)
- Stream lines(Path path, Charset cs)
- Stream list(Path dir)
- Stream walk(Path start, FileVisitOption…options)
- Stream walk(Path start, int maxDepth, FileVisitOption… options)
find方法。 Listing 12-48 presents the source code to an application that demonstrates find() and BiPredicate。
Listing 12-48. Streaming and Outputting the Paths of All Files That Match a File Extension
Stream<Path> pathStream = Files.find(Paths.get("F:/storage"), 100, (path, basicFileAttributes) -> "logo.jpg".equals(path.getFileName().toString()));
pathStream.forEach(System.out::println);
Files.list(Paths.get("C:/")).forEach(System.out::println);
Stream<String> lines = Files.lines(Paths.get("E:\\bocai/pom.xml"));
System.out.println(lines.count());
Files.walk(Paths.get("D:/Bin"), 2).forEach(System.out::println);
Using Path Matchers and Watch Services
File没有提供 handle path-matching and watch services的方法,你必须用 FileSystem来完成。
Matching Paths
我们通常用pattern matching来过滤,比如ls -l *.html (Unix/Linux) or dir *.html。
NIO.2提供java.nio.file.PathMatcher来支持,一个方法boolean matches(Path path)
FileSystem’s PathMatcher getPathMatcher(String syntaxAndPattern)方法返回PathMatcher对象,用pattern匹配path,形式是syntaxAndPattern, syntax:pattern。
支持两种pattern语言,regex and glob。例如:([^\s]+(\.(?i)(png|jpg))$)匹配所有.png and .jpg文件。
也可以用glob,比regex局限,类似正则但是更简单。例如:*.java *.* *.{java,class} foo.? /home/*/* /home/** C:\\*
Watching Directories
改进的文件系统接口包括一个用于监视已注册目录的Watch Service API ,用于监听更改和事件。比如监听文件夹内容改变来更新目录。
Watch Service API 在java.nio.file包由以下类型组成:
- Watchable:
- WatchEvent:
- WatchEvent.Kind:
- WatchEvent.Modifier:
- WatchKey:
- WatchService:
- StandardWatchEventKinds:
- ClosedWatchServiceException:
…
…
Listing 12-51. Watching a Directory for Creations, Deletions, and Modifications
import java.io.IOException;
import java.nio.file.*;
import static java.nio.file.StandardWatchEventKinds.*;
/**
* @author @Jasu
* @date 2018-09-13 17:23
*/
public class WatchServiceApiDemo {
public static void main(String[] args) throws IOException {
FileSystem fileSystem = FileSystems.getDefault();
WatchService watchService = fileSystem.newWatchService();
Path dir = fileSystem.getPath("D:/bin");
dir.register(watchService, ENTRY_CREATE, ENTRY_DELETE, ENTRY_MODIFY);
for (; ; ) {
WatchKey key;
try {
key = watchService.take();
} catch (InterruptedException e) {
return;
}
for (WatchEvent event : key.pollEvents()) {
WatchEvent.Kind kind = event.kind();
if (kind == OVERFLOW) {
System.out.println("overflow");
continue;
}
WatchEvent watchEvent = event;
Path path = (Path) watchEvent.context();
System.out.printf("%s: %s%n", watchEvent.kind(), path);
}
boolean valid = key.reset();
if (!valid)
break;
}
}
}
Exercise
The following exercises are designed to test your understanding of Chapter 12’s content:
1. Define file system and file.
2. The File-based file system interface is problematic. For example,
File’s delete() method returns false when it cannot delete a file.
Why is this behavior a problem?
3. Identify the packages that implement the improved file system
interface.
4. Identify the types that form the core of the improved file system
interface.
5. How do you obtain a reference to the default file system?
6. How would you create a new file system?
7. Define path.
8. True or false: The Path interface represents a hierarchical path to a
file that must exist.
9. Describe the element layout of a Path object.
10. What methods do Path and File provide for converting from Path to
File and from File to Path?
11. Identify the FileSystem method that returns a Path object.
12. What happens when you attempt to create a Path object using syntax
that doesn’t conform to the syntax that is parsed by the file system
provider that created the FileSystem responsible for creating the
Path object?
13. Which methods does the Paths class provide for more conveniently
returning Path objects?
14. Identify Path’s methods for returning its name elements.
15. True or false: Path’s boolean isRelative() method returns
false to signify an absolute path.
16. How do you obtain a file system’s root(s)?
17. How do you convert a relative path to an absolute path?
18. Identify Path’s method for removing path redundancies, creating a
relative path between two paths, and resolving (joining) two paths.
19. How do you resolve a path string against the current path’s parent path?
20. How do you convert the current Path instance to a URI object?
21. What does the Path toRealPath(LinkOption... options)
method accomplish?
22. True or false: The Files class provides static methods for
performing path-matching and directory-watching tasks.
23. Define file store.
24. What method does the Files class provide for obtaining a file store?
25. What information can you obtain about a file store?
26. How can you access all available file stores for a given file system?
27. What support does NIO.2 offer for working with attributes?
28. How are attributes organized?
29. Describe the attribute type hierarchy.
30. How can you identify all supported attribute views for a given file
system?
31. What are basic attributes? Identify the view for managing basic
attributes and name the basic attributes.
32. True or false: You can read basic attributes in bulk by calling
BasicFileAttributeView’s BasicFileAttributes
readAttributes() method.
33. Define file key.
34. When you call the Files class’s getAttribute() or
setAttribute() method to get or set a basic or other kind of
attribute value, what syntax must you follow for identifying the
attribute?
35. What do the UserPrincipal and GroupPrincipal interfaces
represent?
36. When would FileOwnerAttributeView’s setOwner() method
throw FileSystemException on a Windows operating system?
37. The AclEntry class describes an entry in an ACL. Identify its
components.
38. True or false: You can define your own file attributes.
39. Identity the attributes supported by FileStoreAttributeView.
40. True or false: !exists(path) is equivalent to notExists(path).
41. What is the isDirectory() method’s default policy on
symbolic links?
42. Why should you be careful when using the return values from
exists(), notExists(),isExecutable(), isReadable(), and
isWritable()?
43. What does the createFile() method do when called to create a file
that already exists?
44. Define optional specific exception.
45. How would you set POSIX file permissions when creating a file?
46. In which directory does Path createTempFile(String prefix,
String suffix, FileAttribute<?>... attrs) create a
temporary file?
47. Identify three ways to delete a temporary file before an application exits.
48. Identify NIO.2’s three methods for reading all bytes or lines of text from
a regular file into memory.
49. The methods in the previous exercise are great for reading the
contents of small regular files into memory. What methods would you
use to read very large files (whose contents probably don’t fit into
memory)?
50. The newInputStream() method supports a varargs list of open
options. Identify and describe the open options supported by the
StandardOpenOption enum. (Not all of these options apply to
newInputStream().)
51. Identify NIO.2’s three methods for writing all bytes or lines of text from
memory to a regular file.
52. The methods in the previous exercise are great for writing the contents
of memory to small regular files. What methods would you use to write
very large amounts of content (which probably doesn’t fit into memory)
to regular files?
53. True or false: When no options are specified, newOutputStream()
works as if the CREATE, TRUNCATE_EXISTING, and WRITE options
are present.
54. What is the purpose of the SeekableByteChannel interface?
55. The FileChannel class implements SeekableByteChannel. Why
does it specify FileChannel position(long newPosition)
and FileChannel truncate(long size) instead of specifying
SeekableByteChannel position(long newPosition) and
SeekableByteChannel truncate(long size)?
56. How do you obtain a SeekableByteChannel object?
57. What did NIO.2 add to the FileChannel class so that you would no
longer have to rely on a classic I/O type (such as RandomAccessFile)
to obtain a file channel?
58. What method does the Files class provide for creating a directory?
59. True or false: The Files class’s directory-creation method
automatically creates nonexistent ancestor directories of the directory
being created.
60. Identify the Files class’s methods for creating temporary directories.
61. What does NIO.2 provide for obtaining a list of a directory’s entries?
62. How do you filter a list of directory entries so that only desired entries
are returned?
63. What methods does Files provide to copy a file to another file?
64. Two of the copy() methods support a varargs list of copy options.
Identify and describe the copy options supported by the
StandardCopyOption enum.
65. What other copy option can be passed to these copy() methods?
66. What method does Files provide to move a file to another file?
67. What copy options are supported by this file-movement method?
68. Identify the Files methods for deleting files.
69. Define symbolic link and circular reference.
70. Identify the Files method for creating a symbolic link to a target.
71. How do you determine if an arbitrary path represents a symbolic link?
72. How do you read the target of a symbolic link?
73. Define hard link.
74. In what ways are hard links more restrictive than soft links?
75. Identify the Files method for creating a hard link for an existing file.
76. Describe the File Tree-Walking API.
77. Identify the types that comprise the public portion of the File
Tree-Walking API.
78. True or false: SKIP_SUBTREE is only meaningful when returned from
the preVisitDirectory() method; otherwise, this result type is the
same as CONTINUE.
79. What methods does the Files class provide for walking the file tree?
80. What does the Stream<Path> find(Path start, int
maxDepth, BiPredicate<Path,BasicFileAttributes>
matcher, FileVisitOption... options) method accomplish?
81. How does NIO.2 support path-matching?
82. What is the purpose of the Watch Service API?
83. Identify and describe the types that comprise the Watch Service API.
84. Exercise 22 in Chapter 2 asked you to create a Touch application.
Rewrite this application to use NIO.2 types.
Summary
NIO.2 improves the file system interface that was previously limited to the File class. The improved file system interface features methods throwing exceptions, support for symbolic links, broad and efficient support for file attributes, directory streams, support for alternative file systems via custom file system providers, support for file copying and file moving, support for walking the file tree/visiting files and watching directories, and more. The improved file system interface is implemented mainly by the various types in the java.nio.file, java.nio.file.attribute, and java.nio.file.spi packages. FileSystem, FileSystems, and FileSystemProvider form the core of the improved file system interface.
Chapter 13 Asynchronous I/O
NIO提供了multiplexed I/O(非阻塞I/O和readiness selection的组合,前7章讨论后8章讨论)让高可伸缩服务器的创建更容易。客户端代码用一个selector注册一个socket channel,当channel准备开始I/O时,会通知它。
NIO.2提供了 asynchronous I/O,让客户端启动一个I/O操作然后当操作完成时通知客户端。类似于multiplexed I/O,asynchronous I/O也通常用于促进高可伸缩服务器的创建。
注意:Multiplexed I/O通常用于提供高度可伸缩和高性能的轮询接口的操作系统如Linux and Solaris。Asynchronous I/O通常用于提供高度可伸缩和高性能的异步I/O设备——比如newer Windows operating systems。
本章首先介绍了异步输入输出的概述。然后探索asynchronous file channels, socket channels, and channel groups。
Asynchronous I/O Overview
java.nio.channels.AsynchronousChannel接口描述了asynchronous channel,是一个支持异步I/O操作的(读写等等)channel。调用一个返回future或者需要completion handler参数的方法来启动I/O操作:
Future<V> operation(...): V是操作结果。Future方法可以被调用去检查i/o是否完成,等待完成和接收结果。void operation(... A attachment, CompletionHandler handler):调用operation,带有参数attachment(一个连接到i/o操作的对象当消费结果时提供context)和参数handler是java.nio.channels.CompletionHandler<V, A>接口的实例。A是attachment,V是i/o操作的结果。attachment对用无状态CompletionHandler对象消耗大量i/o操作的结果的情况很重要。当i/o操作完成或失败,handler被调用来消费操作的结果。
CompletionHandler声明下面的方法消费操作成功完成的result,并且得知操作失败原因和采取适当动作:
- void completed(V result, A attachment): 当操作成功完成被调用。操作的结果是result。attachment是操作启动时连接到操作的对象。
- void failed(Throwable t, A attachment): 当操作失败被调用。t是操作失败原因。attachment是..
被调用后,方法立即返回。然后你调用Future方法或者在CompletionHandler实现里提供了解更多i/o操作状态或执行操作结果的代码。
CANCELLATION
Future声明了boolean cancel(boolean mayInterruptIfRunning)方法来取消执行。这个方法导致所有等待i/o操作结果的线程抛出java.util.concurrent.CancellationException。底层I / O操作是否被取消是高度特定于实现的,因此没详细说明。如果取消让连接的channel或者实体处于不一致状态,channel被放入一个特定于实现的error state,阻止再次尝试发起与被取消操作类似的i/o操作。例如,如果一个操作被取消了,但是实现不能保证字节没有从通道读取,它将在通道放入错误error state。再次尝试会导致未指定的运行时异常被抛出。类似地,如果一个操作被取消了,但是实现不能保证字节没有被写入通道,那么启动一个操作的后续尝试将会以一个未指明的运行时异常失败。
如果 cancel()的参数mayInterruptIfRunning是true,i/o操作可能通过关闭channel被打断。这种情况下,所有等待i/o操作的线程导致抛出 CancellationException,这个channel上的其他i/o操作抛出 java.nio.channels.AsynchronousCloseException完成。
当 cancel()被调用于取消读写,推荐操作用的所有buffers被discarded,这样做是为了确保在通道保持打开状态时不会访问buffer。
______________________________________________________________________________
AsynchronousChannel继承java.nio.channels.Channel接口,继承了isOpen() and close()。 close()方法要遵循下面的附加规定:这个通道上的任何未完成的异步操作都将抛出AsynchronousCloseException objects完成。channel关闭后,启动i/o异步的尝试会立刻导致java.nio.channels.ClosedChannelException。
注意:Asynchronous channels对多线程是安全的。一些channel实现可能支持并发读写,但在任何给定的时间,可能不允许超过一个线程读和一个线程写。
java.nio.channels.AsynchronousByteChannel继承AsynchronousChannel。有4个方法:
Future<Integer> read(ByteBuffer dst):从这个通道读取一个字节序列到byte buffer。返回Future当可用时访问字节。<A> void read(ByteBuffer dst, A attachment, CompletionHandler<Integer,? super A> handler):Future<Integer> write(ByteBuffer src):从byte buffer写字节序列到channel。返回Future。<A> void write(ByteBuffer src, A attachment, CompletionHandler<Integer,? super A> handler):
read()抛出java.nio.channels.ReadPendingException,当前一个读未完成且不允许超过一个线程读。write抛出 java.nio.channels.WritePendingException。
警告:java.nio.ByteBuffer不是线程安全的。当读或写启动,注意必须保证操作结束前buffer不被访问。
Asynchronous File Channels
抽象java.nio.channels.AsynchronousFileChannel类描述了一个 asynchronous channel用于读写操作文件。调用下面方法创建AsynchronousFileChannel’s open():
AsynchronousFileChannel ch;
ch = AsynchronousFileChannel.open(Paths.get("somefile"));
该文件包含一个可变长度的字节序列,可以读取和写入,并且可以查询其当前大小。当字节超出当前大小时,文件的大小会增加;当文件被截断时,大小会减少。
调用AsynchronousFileChannel’s read() and write()方法来读写文件。
警告:AsynchronousFileChannel实现AsynchronousChannel而不是AsynchronousByteChannel,因为这个类的读写方法带有position,AsynchronousByteChannel读写方法没有position概念。
asynchronous file channel在文件中没有current position。代替的是,file position作为参数传递给启动异步操作的每个read和write方法。
注意:read() and write()必须提供绝对position(相对与0)。没有一个点让读写去相对这个点因为读写操作可以在之前的操作完成之前启动,不能保证顺序。相同原因,AsynchronousFileChannel类也没设置和查询当前position的方法。
除了支持读写外,AsynchronousFileChannel定义了下面的操作:
- force(boolean metaData)。文件更新强制发送到底层储存设备,确保数据不丢失。
- 文件的一个区域被锁住。调用lock() and tryLock()完成。两个方法返回Future,CompletionHandler作为参数。
I’ve created an AFCDemo application that uses AsynchronousFileChannel to open a file and read up to the first 1024 bytes in a Future context. Listing 13-1 presents the source code.
Listing 13-1. Reading Bytes from a File and Polling the Returned Future for Completion
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousFileChannel;
import java.nio.file.Paths;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
/**
* @author @Jasu
* @date 2018-09-14 18:09
*/
public class AsyncFileChannelDemo {
public static void main(String[] args) throws InterruptedException, IOException, ExecutionException {
AsynchronousFileChannel channel = AsynchronousFileChannel.open(Paths.get("page.html"));
ByteBuffer buffer = ByteBuffer.allocate(1024);
Future<Integer> result = channel.read(buffer, 0);
while (!result.isDone()) {
System.out.println("waiting done");
TimeUnit.MILLISECONDS.sleep(1);
}
System.out.println("Finished = " + result.isDone());
System.out.println("Bytes read = " + result.get());
channel.close();
}
}
NOTE: AsynchronousFileChannel open(Path file, OpenOption… options)尝试打开或创建文件用于读/写,返回asynchronous file channel来访问文件。可能传入java.nio.file.OpenOption接口描述的参数,是java.nio.file.StandardOpenOption实现的。没有指定参数, open()尝试打开存在的文件来read。
假设一个存在的文件已经被成功打开,分配了一个byte buffer,读操作在position 0启动。返回的Future对象的isDone()方法反复被调用。直到操作完成。
I’ve also created a second AFCDemo application that uses AsynchronousFileChannel to open a file and read up to the first 1024 bytes in a CompletionHandler context. Listing 13-2 presents the source code.
Listing 13-2. Reading Bytes from a File and Displaying the Results in a Completion Handler
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousFileChannel;
import java.nio.channels.CompletionHandler;
import java.nio.file.Paths;
/**
* @author @Jasu
* @date 2018-09-14 18:09
*/
public class AsyncFileChannelDemo1 {
public static void main(String[] args) throws IOException {
AsynchronousFileChannel channel = AsynchronousFileChannel.open(Paths.get("page.html"));
ByteBuffer buffer = ByteBuffer.allocate(1024);
Thread ct = Thread.currentThread();
channel.read(buffer, 0, null, new CompletionHandler<Integer, Void>() {
@Override
public void completed(Integer result, Void attachment) {
System.out.println("Byte read: " + result);
ct.interrupt();
}
@Override
public void failed(Throwable exc, Void attachment) {
System.out.println("failed: " + exc.toString());
ct.interrupt();
}
});
System.out.println("waiting for completion");
try {
ct.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
channel.close();
}
}
Asynchronous Socket Channels
抽象类java.nio.channels.AsynchronousServerSocketChannel描述了asynchronous channel for stream-oriented listening sockets。stream-oriented connecting sockets的对应channel由抽象类java.nio.channels.AsynchronousSocketChannel描述。
Note:AsynchronousServerSocketChannel实现AsynchronousChannel而不是AsynchronousByteChannel,因为没声明read()/write()。AsynchronousSocketChannel实现了AsynchronousByteChannel。
AsynchronousServerSocketChannel
调用AsynchronousServerSocketChannel open()获取。
AsynchronousServerSocketChannel ch;
ch = AsynchronousServerSocketChannel.open();
根据AsynchronousServerSocketChannel的文档,这个方法返回绑定到默认group的asynchronous server socket channel。可选的 AsynchronousServerSocketChannel open(AsynchronousChannelGroup group) 方法返回绑定到指定group的channel。随后讨论asynchronous channel groups。
调用 AsynchronousServerSocketChannel setOption(SocketOption name,
T value)方法配置asynchronous server socket channel。目前只有 SO_RCVBUF and SO_REUSEADDR。
一个新建的可能配置过的asynchronous server socket channel是打开了但还没绑定到本地地址。可以被绑定到本地地址来配置监听连接,通过调用 bind() 。一旦绑定,任意accept()方法返回Future。没有绑定去accept抛出java.nio.channels.NotYetBoundException。
Note:Asynchronous server socket channels多线程是线程安全的,虽然在任意时刻最多只有一个accept操作可以停留。如果一个线程在前一个accept操作结束前启动accept操作,抛出java.nio.channels.AcceptPendingException。
To demonstrate AsynchronousServerSocketChannel, I’ve created a Server application consisting of Server, Attachment, ConnectionHandler, and ReadWriteHandler classes. Listing 13-3 presents Server’s source code.
Listing 13-3. Launching a Server That Handles Connections and Reads/Writes Asynchronously
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.AsynchronousServerSocketChannel;
/**
* @author @Jasu
* @date 2018-09-17 16:23
*/
public class Server {
private final static int PORT = 9090;
private final static String HOST = "localhost";
public static void main(String[] args) {
AsynchronousServerSocketChannel channelServer;
try {
channelServer = AsynchronousServerSocketChannel.open();
channelServer.bind(new InetSocketAddress(HOST, PORT));
System.out.printf("Server listening at %s%n",
channelServer.getLocalAddress());
} catch (IOException e) {
System.err.println("Unable to open or bind server socket channel");
return;
}
Attachment attachment = new Attachment();
attachment.channelServer = channelServer;
channelServer.accept(attachment, new ConnectionHandler());
try {
Thread.currentThread().join();
} catch (InterruptedException e) {
System.out.println("Server terminating");
}
}
}
import java.net.SocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousServerSocketChannel;
import java.nio.channels.AsynchronousSocketChannel;
/**
* @author @Jasu
* @date 2018-09-17 16:29
*/
public class Attachment {
public AsynchronousServerSocketChannel channelServer;
public AsynchronousSocketChannel channelClient;
public boolean isReadMode;
public ByteBuffer buffer;
public SocketAddress clientAddr;
}
import java.io.IOException;
import java.net.SocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousSocketChannel;
import java.nio.channels.CompletionHandler;
/**
* @author @Jasu
* @date 2018-09-17 16:31
*/
public class ConnectionHandler implements CompletionHandler<AsynchronousSocketChannel, Attachment> {
@Override
public void completed(AsynchronousSocketChannel channelClient, Attachment attachment) {
SocketAddress clientAddr = null;
try {
clientAddr = channelClient.getRemoteAddress();
System.out.printf("Accepted connection from %s%n", clientAddr);
attachment.channelServer.accept(attachment, this);
Attachment newAtt = new Attachment();
newAtt.channelServer = attachment.channelServer;
newAtt.channelClient = channelClient;
newAtt.isReadMode = true;
newAtt.buffer = ByteBuffer.allocate(2048);
newAtt.clientAddr = clientAddr;
ReadWriteHandler rwh = new ReadWriteHandler();
channelClient.read(newAtt.buffer, newAtt, rwh);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void failed(Throwable exc, Attachment attachment) {
System.out.println("Failed to accept connection");
}
}
import java.io.IOException;
import java.nio.channels.CompletionHandler;
/**
* @author @Jasu
* @date 2018-09-17 16:38
*/
public class ReadWriteHandler implements CompletionHandler<Integer, Attachment> {
@Override
public void completed(Integer result, Attachment att) {
if (result == -1) {
try {
att.channelClient.close();
System.out.printf("Stopped listening to client %s%n",
att.clientAddr);
} catch (IOException ioe) {
ioe.printStackTrace();
}
return;
}
if (att.isReadMode) {
att.buffer.flip();
int limit = att.buffer.limit();
byte[] bytes = new byte[limit];
att.buffer.get(bytes, 0, limit);
System.out.printf("Client at %s sends message: %s%n",
att.clientAddr,
new String(bytes));
att.isReadMode = false;
att.buffer.rewind();
att.channelClient.write(att.buffer, att, this);
} else {
att.isReadMode = true;
att.buffer.clear();
att.channelClient.read(att.buffer, att, this);
}
}
@Override
public void failed(Throwable exc, Attachment attachment) {
System.out.println("Connection with client broken");
}
}
AsynchronousSocketChannel
调用 AsynchronousSocketChannel open()获取:
AsynchronousSocketChannel ch = AsynchronousSocketChannel.open();
根据AsynchronousSocketChannel的文档,返回绑定到默认group的asynchronous socket channel。也可以使用另一个重载方法指定线程组。
可以使用setOption(SocketOption name, T value)方法配置,支持SO_RCVBUF, SO_SNDBUF, SO_KEEPALIVE, SO_REUSEADDR, and TCP_NODELAY。
新建和配置的channel还未连接,要连接到 asynchronous server socket channel的socket。不可能为一个任意存在的socket创建asynchronous socket channel。
通过connect()连接。一旦连接,就会保持连接状态直到被关闭。是不是连接了可以调用SocketAddress getRemoteAddress()方法来知道,没连接是null。没连接就尝试调用i/o操作导致NotYetConnectedException.
Note:Asynchronous socket channels是线程安全的。最多同时存在一个读和一个写操作。
To demonstrate AsynchronousSocketChannel, I’ve created a Client application consisting of the Client, Attachment, and ReadWriteHandler classes. Listing 13-7 presents Client’s source code.
Listing 13-7. Launching a Client That Handles Reads/Writes Asynchronously
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousSocketChannel;
import java.nio.charset.Charset;
import java.util.concurrent.ExecutionException;
/**
* @author @Jasu
* @date 2018-09-17 17:58
*/
public class Client {
private final static Charset CSUTF8 = Charset.forName("UTF-8");
private final static int PORT = 9090;
private final static String HOST = "localhost";
public static void main(String[] args) {
AsynchronousSocketChannel channel;
try {
channel = AsynchronousSocketChannel.open();
} catch (IOException e) {
System.err.println("Unable to open client socket channel");
return;
}
try {
channel.connect(new InetSocketAddress(HOST, PORT)).get();
System.out.printf("Client at %s connected%n",
channel.getLocalAddress());
} catch (InterruptedException | ExecutionException e) {
System.err.println("Server not responding");
return;
}catch (IOException e) {
System.err.println("Unable to obtain client socket channel's " +
"local address");
return;
}
Attachment attachment = new Attachment();
attachment.channel = channel;
attachment.isReadMode = false;
attachment.buffer = ByteBuffer.allocate(2048);
attachment.mainThd = Thread.currentThread();
byte[] data = "Hello".getBytes();
attachment.buffer.put(data);
attachment.buffer.flip();
channel.write(attachment.buffer, attachment, new ReadWriteHandler());
try {
attachment.mainThd.join();
} catch (InterruptedException e) {
System.out.println("Client terminating");
}
}
}
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousSocketChannel;
/**
* @author @Jasu
* @date 2018-09-17 18:02
*/
public class Attachment {
public AsynchronousSocketChannel channel;
public boolean isReadMode;
public ByteBuffer buffer;
public Thread mainThd;
}
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.channels.CompletionHandler;
import java.nio.charset.Charset;
/**
* @author @Jasu
* @date 2018-09-17 18:06
*/
public class ReadWriteHandler implements CompletionHandler<Integer, Attachment> {
private BufferedReader conReader =
new BufferedReader(new InputStreamReader(System.in));
@Override
public void completed(Integer result, Attachment attachment) {
if (attachment.isReadMode) {
attachment.buffer.flip();
int limit = attachment.buffer.limit();
byte[] bytes = new byte[limit];
attachment.buffer.get(bytes, 0, limit);
String msg = new String(bytes, Charset.defaultCharset());
System.out.printf("Server responded: %s%n", msg);
try {
msg = "";
while (msg.length() == 0) {
System.out.print("Enter message (\"end\" to quit): ");
msg = conReader.readLine();
}
if (msg.equalsIgnoreCase("end")) {
attachment.mainThd.interrupt();
return;
}
} catch (IOException e) {
System.err.println("Unable to read from console");
}
attachment.isReadMode = false;
attachment.buffer.clear();
byte[] data = msg.getBytes();
attachment.buffer.put(data);
attachment.buffer.flip();
attachment.channel.write(attachment.buffer, attachment, this);
} else {
attachment.isReadMode = true;
attachment.buffer.clear();
attachment.channel.read(attachment.buffer, attachment, this);
}
}
@Override
public void failed(Throwable exc, Attachment attachment) {
System.err.println("Server not responding");
System.exit(1);
}
}
Asynchronous Channel Groups
抽象java.nio.channels.AsynchronousChannelGroup类描述了一组目的为资源共享的asynchronous channels。一个group和一个thread pool关联,tasks被提交到线程池,来处理 I/O事件和dispatch to completion handlers来消费在group’s channels执行异步操作的结果。
Note :相关的 thread pool由group拥有;group的终止会导致关联的线程池shut down。
AsynchronousServerSocketChannels and AsynchronousSocketChannels 附属于group。当你使用无参方法创建这两种channel,是绑定到默认group的,是system-wide channel group自动由JVM构造和维护。default group有一个关联的线程池,需要时创建线程。你可以用以下系统属性在JVM启动时配置默认组:
-
java.nio.channels.DefaultThreadPool.threadFactory:是java.util.concurrent.ThreadFactory的具体类的全限定名。此类使用系统类加载器加载实例化。factory的 newThread(Runnable r) 方法为默认group的线程池创建线程。如果加载实例化属性的过程失败,在构建默认组的时候抛出未指定error。(如果默认组的 ThreadFactory 没配置,默认组的pooled threads是守护线程。)
-
java.nio.channels.DefaultThreadPool.initialSize:指定default group’s thread pool的初始size。
你可能更想定义自己的channel group,这会让你更多服务I/O operations线程的控制权。另外,提供了shut down线程和等待终止的机制。你可以调用下面方法创建自己的asynchronous channel group:
- AsynchronousChannelGroup withCachedThreadPool(ExecutorService executor, int initialSize): 使用指定thread pool创建
- AsynchronousChannelGroup withFixedThreadPool(int nThreads, ThreadFactory threadFactory):使用一个 fixed thread pool创建。
- AsynchronousChannelGroup withThreadPool (ExecutorService executor):使用指定thread pool创建。
The following example creates a new channel group that has a fixed pool of 20 threads. Each thread is constructed with the default thread factory from the java.util.concurrent.Executors class:
AsynchronousChannelGroup group;
group = AsynchronousChannelGroup.withFixedThreadPool(20, Executors.defaultThreadFactory());
创建后,你需要把asynchronous server socket channel and an asynchronous socket channel绑定到group上:
- AsynchronousServerSocketChannel open(AsynchronousChannelGroup group)
- AsynchronousSocketChannel open(AsynchronousChannelGroup group)
The following example creates an asynchronous server socket channel and an asynchronous socket channel that are bound to the previously-created group:
AsynchronousServerSocketChannel chServer;
chServer = AsynchronousServerSocketChannel.open(group);
AsynchronousSocketChannel chClient = AsynchronousSocketChannel.open(group);
Note :当写completion handler,避免操作阻塞线程很重要。当所有线程被阻塞时,整个应用程序可能会阻塞。对于custom or cached thread pool,queue可能变得非常大无限增长导致oom。
绑定到group便于关闭和终止。void shutdown()方法启动一个group的顺序关闭。isShutdown() 方法查看是否关闭。关闭的group不能创建channel。
一旦shut down,group终止会在下面操作完成后终止——所有绑定到group的asynchronous channels关闭,所有活跃的executing completion handlers完结,group使用的资源释放。不会尝试停止或中断正在执行completion handlers的线程。isTerminated()检查是否终止。 boolean awaitTermination(long timeout, TimeUnit unit)用于在关闭前阻塞。
shutdownNow()强制关闭group。 除了顺序shut down,会调用group里open channels的close()方法。
The following example demonstrates the aforementioned methods:
// Initiate an I/O operation that isn't satisfied.
channel.accept(null, completionHandler);
// After the operation has begun, the channel group is used to control
// the shutdown.
if (!group.isShutdown())
{
// After the group is shut down, no more channels can be bound to it.
group.shutdown();
}
if (!group.isTerminated())
{
// Forcibly shut down the group. The channel is closed and the
// accept operation aborts.
group.shutdownNow();
}
// The group should be able to terminate; wait for 10 seconds maximum.
group.awaitTermination(10, TimeUnit.SECONDS);
What About AsynchronousFileChannel?
AsynchronousFileChannels不附属于group。然而,和一个线程池关联来提交task,执行i/o event和dispatch to completion handlers消费channel操作的结果。在channel启动用于执行i/o操作的completion handler保证会被线程池的一个线程调用,这就确保了 completion handler是由一个带有预期标识的线程运行的。如果i/o操作立即完成了,启动线程本事是线程池的线程,completion handler直接被启动线程调用。
当asynchronous file channel没指定线程池,使用基于系统的默认线程池,可能和其他的channels共享。默认线程池由 AsynchronousChannelGroup定义的系统属性配置
AsynchronousFileChannel’s AsynchronousFileChannel open(Path file, OpenOption… options)创建的 asynchronous file channel 和默认线程池关联。调用 AsynchronousFileChannel open(Path file, Set options, ExecutorService executor, FileAttribute... attrs)指定线程池。
EXERCISES
The following exercises are designed to test your understanding of Chapter 13’s content:
1. Define asynchronous channel.
2. Identify the two ways to initiate an I/O operation with an asynchronous
channel.
3. True or false: After a channel is closed, further attempts to initiate
asynchronous I/O operations complete immediately with cause
AsynchronousCloseException.
4. Identify the methods declared by the AsynchronousByteChannel
interface.
5. True or false: The ByteBuffer object is safe for use by multiple
concurrent threads.
6. Identify the class for reading, writing, and manipulating a file
asynchronously.
7. True or false: An asynchronous file channel doesn’t have a current
position within a file.
8. If you pass no options to AsynchronousFileChannel’s
AsynchronousFileChannel open(Path file, OpenOption...
options) method, what is this method’s default behavior?
9. How do you obtain an AsynchronousServerSocketChannel object
or an AsynchronousSocketChannel object?
10. Identify AsynchronousServerSocketChannel's documented
socket options.
11. After obtaining an AsynchronousServerSocketChannel object,
what must you do before you can call either of its accept() methods?
12. After obtaining an AsynchronousSocketChannel object, what must
you do before you can perform reads and writes?
13. How do you determine if an asynchronous socket channel is connected
to an asynchronous server socket channel?
14. True or false: Asynchronous socket channels are safe for use by
multiple concurrent threads.
15. What is the purpose of the AsynchronousChannelGroup class?
16. What does a group use for task submission?
17. Identify the system properties for configuring the default group.
18. Describe AsynchronousChannelGroup’s shutDownNow() method.
19. True or false: AsynchronousFileChannels belong to groups.
20. Write a Copy application that uses AsynchronousFileChannel to
copy a source file to a destination file asynchronously
Summary
Asynchronous I/O让客户端代码启动I/O操作,随后操作完成时通知客户端。The AsynchronousChannel interface describes an asynchronous channel that supports asynchronous I/O operations (reads, writes, and so on). An I/O operation is initiated by calling a method that returns a Future or requires a CompletionHandler argument.
CompletionHandler declares a completed() method to consume the result of an operation when it completes successfully. It also declares a failed() method to report operation failure (in terms of an exception) and allow an application to take appropriate action.
The AsynchronousByteChannel interface extends AsynchronousChannel and declares a pair of read() methods and a pair of write() methods. Each pair consists of a method that returns a Future and a method that requires a CompletionHandler argument.
The abstract AsynchronousFileChannel class describes an asynchronous channel for reading, writing, and manipulating a file. The abstract AsynchronousServerSocketChannel class describes an asynchronous channel for stream-oriented listening sockets. Its counterpart channel for stream-oriented connecting sockets is described by the abstract AsynchronousSocketChannel class
The abstract AsynchronousChannelGroup class describes a grouping of asynchronous channels for the purpose of resource sharing. A group has an associated thread pool to which tasks are submitted, to handle I/O events and to dispatch to completion handlers that consume the results of asynchronous operations performed on the group’s channels
AsynchronousServerSocketChannels and AsynchronousSocketChannels created via their noargument open() methods are bound to the default group. They can be bound to groups created from AsynchronousChannelGroup’s class methods by passing these group objects to their open(AsynchronousChannelGroup) methods.
Chapter 14 Completion of Socket Channel Functionality
JDK 7最终补全了NIO.2的 socket channel功能。绑定到channel的socket,get/set socket的option,你必须调用socket()方法获取 peer socket。
Binding and Option Configuration
socket channel and socket APIs的违反直觉的组合存在是因为JDK1.4的时间不足。JDK引入java.nio.channels.NetworkChannel接口解决这个问题。
NetworkChannel代表代表一个到network socketd channel.接口被DatagramChannel, ServerSocketChannel, SocketChannel, java.nio.channels.AsynchronousServerSocketChannel,java.nio.channels.AsynchronousSocketChannel 实现。
Table 14-1 presents NetworkChannel’s methods.
Table 14-1. The Methods that Define a Network Channel
| Method | Description |
| ——————————————————— | ———————————————————— |
| NetworkChannel bind(SocketAddress local) | 绑定直到关闭 |
| SocketAddress getLocalAddress() | Return the socket address to which this channel’ s socket is bound. |
| T getOption<br/>(SocketOption name) | |
| NetworkChannel<br/>setOption
(SocketOption name,
T value) | |
| Set><br/>supportedOptions() | |
option是JDK添加的java.net.StandardSocketOptions,有比如:SO_RCVBUF (size of socket receive buffer) and TCP_NODELAY (disable the Nagle algorithm)。
可以使用哪些option是根据该类的具体实现的。
JDK7也更新了 DatagramChannel, ServerSocketChannel, and SocketChannel的几个方法:
- DatagramChannel加了 SocketAddress getRemoteAddress()
- ServerSocketChannel加了ServerSocketChannel bind(SocketAddress local, int backlog)
- SocketChannel加了 SocketChannel shutdownInput() and SocketChannel shutdownOutput()。也有SocketAddress getRemoteAddress()
Listing 7-7’s ChannelServer application had to invoke socket() when binding the channel’s socket to a local address, obtaining the local address, and obtaining the remote address. Listing 14-1 simplifies this code by making it NetworkChannel-compliant and using getRemoteAddress().
Listing 14-1. Demonstrating the Improved ServerSocketChannel
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
/**
* @author @Jasu
* @date 2018-09-25 14:48
*/
public class ChannelServer {
public static void main(String[] args) throws IOException {
System.out.println("Starting server..");
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(9999));
ssc.configureBlocking(false);
String msg = "Local address: " + ssc.getLocalAddress();
ByteBuffer buffer = ByteBuffer.wrap(msg.getBytes());
while (true)
{
System.out.print(".");
SocketChannel sc = ssc.accept();
if (sc != null)
{
System.out.println();
System.out.println("Received connection from " +
sc.getRemoteAddress());
buffer.rewind();
sc.write(buffer);
sc.close();
}
else
try
{
Thread.sleep(1000);
}
catch (InterruptedException ie)
{
assert false; // shouldn't happen
}
}
}
}
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.SocketOption;
import java.net.StandardSocketOptions;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
import java.util.Set;
/**
* @author @Jasu
* @date 2018-09-25 15:06
*/
public class ChannelClient {
public static void main(String[] args) throws IOException {
SocketChannel sc = SocketChannel.open();
Set<SocketOption<?>> socketOptions = sc.supportedOptions();
for (SocketOption<?> socketOption : socketOptions) {
System.out.println(socketOption);
}
System.out.println(sc.getOption(StandardSocketOptions.SO_RCVBUF));
sc.configureBlocking(false);
InetSocketAddress addr = new InetSocketAddress("localhost", 9999);
sc.connect(addr);
while (!sc.finishConnect()) {
System.out.println("waiting to finish connection");
}
ByteBuffer buffer = ByteBuffer.allocate(200);
while (sc.read(buffer) >= 0) {
buffer.flip();
while (buffer.hasRemaining())
System.out.print((char) buffer.get());
buffer.clear();
}
sc.close();
}
}
Channel-Based Multicasting
JDK 7 引入channel-based IP multicasting支持,传输IP的数据报文到group。数据来自一个源。
D IP address类代表group,是一个 multicast group IPv4 address从224.0.0.1到 239.255.255.255。新的receiver (client)通过连接group ip加入到组。
JDK 7 引入 java.nio.channels.MulticastChannel接口支持multicasting。继承NetworkChannel,被DatagramChannel实现。声明了join()方法和 close()方法。
receiver调用 MembershipKey join(InetAddress group, NetworkInterface ni)加入group。
Note:network interface由类java.net. NetworkInterface实例描述,调用 NetworkInterface getByInetAddress(InetAddress addr)获取。
调用 MembershipKey join(InetAddress group, NetworkInterface ni, InetAddress source)从source接收。
Note:第一个join是类似有线电视,订阅packages of channels。第二个是订阅你感兴趣的。
MembershipKey声明几个方法:
- MembershipKey block(InetAddress source):屏蔽source
- MulticastChannel channel():
- void drop():
- InetAddress group():
- boolean isValid():
- NetworkInterface networkInterface():
- InetAddress sourceAddress():
- MembershipKey unblock(InetAddress source):
To create a multicast server or multicast client, there are three important items to keep in mind:
- 指定 protocol family
- 调用DatagramChannel’s DatagramChannel open(ProtocolFamily family)创建 datagram channel。
- channel’s socket应该绑定到 wildcard address。
- …
I’ve created multicast server and client applications that demonstrate channel-based multicasting. Listing 14-3 presents the server.
Listing 14-3. Demonstrating a Channel-Based Multicast Server
public class DatagramServer {
final static int PORT = 9999;
public static void main(String[] args) throws IOException {
NetworkInterface ni;
ni = NetworkInterface.getByInetAddress(InetAddress.getLocalHost());
DatagramChannel dc;
dc = DatagramChannel.open(StandardProtocolFamily.INET)
.setOption(StandardSocketOptions.SO_REUSEADDR, true)
.bind(new InetSocketAddress(PORT)).setOption(StandardSocketOptions.IP_MULTICAST_IF, ni);
InetAddress group = InetAddress.getByName("239.255.0.1");
int i = 0;
while (true)
{
ByteBuffer bb = ByteBuffer.wrap(("line " + i).getBytes());
dc.send(bb, new InetSocketAddress(group, PORT));
i++;
}
}
}
import java.io.IOException;
import java.net.*;
import java.nio.ByteBuffer;
import java.nio.channels.DatagramChannel;
import java.nio.channels.MembershipKey;
/**
* @author @Jasu
* @date 2018-09-26 10:23
*/
public class DatagramClient {
final static int PORT = 9999;
public static void main(String[] args) throws IOException {
NetworkInterface ni;
ni = NetworkInterface.getByInetAddress(InetAddress.getLocalHost());
DatagramChannel dc;
dc = DatagramChannel.open(StandardProtocolFamily.INET)
.setOption(StandardSocketOptions.SO_REUSEADDR, true).bind(new InetSocketAddress(PORT))
.setOption(StandardSocketOptions.IP_MULTICAST_IF, ni);
InetAddress group = InetAddress.getByName("239.255.0.1");
MembershipKey membershipKey = dc.join(group, ni);
ByteBuffer response = ByteBuffer.allocate(50);
while (true) {
dc.receive(response);
response.flip();
while (response.hasRemaining()) {
System.out.print((char) response.get());
}
System.out.println();
response.clear();
}
}
}
Appendix B Sockets and Network Interfaces
7章节引入peer socket概念,是一个关联一个channel的socket。14章引入network interface的概念。附录介绍sockets, network interfaces, and 和这些功能交互的APIs,
Note:网络是一组相互连接的节点(诸如平板电脑之类的计算设备,以及扫描仪或激光打印机等外围设备),可在网络用户之间共享。网络在节点之间使用 TCP/IP交流。Transmission Control Protocol (TCP),是一种面向连接的协议; User Datagram Protocol (UDP),是无连接协议;Internet Protocol (IP),是基础协议,TCP和UDP通过他执行任务。
java.net package提供了进程间TCP/IP的类型支持。
Sockets
两个进程之间sockets方式交流,sockets是两个进程之间communications link的endpoints。每个endpoint IP代表host,port代表host的端口号
**P ADDRESSES AND PORT NUMBERS。**·`
IP地址是一个32位或128位的无符号整数,惟一地标识一个网络主机或其他网络节点(例如,一个路由器)。
通常使用32bit IP,一个32位的IP地址通常被称为 Internet Protocol Version 4 (IPv4)地址。
也通常用128-bit IP address,8个16-bit integer。每个组件都是一个十六进制整数,从0到FFFF,通过冒号与下一个组件分离。such as 1080:0:0:0:8:800:200C:417A。A 128-bit IP address is often referred to as an Internet Protocol Version 6 (IPv6) address 。一个端口号是一个16位的整数,它唯一地标识一个进程,它是消息的最终来源或接收者。小于1024的端口号是为标准流程保留的。例如,端口25传统上标识了简单的邮件发送电子邮件的传输协议(SMTP)过程,尽管端口号587已经在很大程度上淘汰了这个旧的端口号。
一个进程写message(字节序列)到socket。底层平台的网络管理软件部分将消息分解成一系列数据包(可寻址的消息块,通常称为IP数据报),把它们转发到另一个进程的socket,将它们重新组合为原始信息进行处理。

在图B-1的上下文中,假设进程A想要发送一条消息给进程B。A发消息到它的socket,附有B的目标socket地址。主机A的network management software(通常被称为协议栈)获得message,将其简化为一系列信息包,每个包包含目标主机的IP地址和端口号。然后 network management software通过A主机的 Network Interface Card(NIC)到主机B。
Note:网卡(NIC)的各种网络接口是计算机和网络之间的连接。
B主机的协议栈通过NIC接收包并重组为原始message(数据包可能无序),然后通过socket对进程B可用。当进程B与进程a通信时,这个场景会发生逆转。
网络管理软件使用TCP在两个主机之间创建一个正在进行的对话,其中消息被来回发送。在此对话发生之前,这些主机之间建立了连接。在建立连接之后,TCP进入一个模式,在这个模式中,它发送消息数据包并等待它们正确到达的应答(或者由于某个网络问题而没有到达,超时过期)。这种模式重复并保证了可靠的连接。有关此模式的详细信息,请访问http://en.wikipedia.org/wiki/tcpreceivewindowflowcontrol。
因为建立一个连接需要时间,发送数据包也需要时间(因为有必要接收应答确认和超时),TCP是缓慢的。另一方面,UDP不需要连接和包确认,它的速度要快得多。缺点是UDP不可靠,因为没有确认(虽然UDP使用校验和来验证数据是否正确,但并不能保证包的交付、排序或对重复数据包的保护)。此外,UDP仅限于单包会话。
java.net包提供Socket, ServerSocket和其他Socket后缀的类用于执行执行基于tcp的或基于udp的通信。在研究这些类之前,您需要了解socket addresses和socket options。
Socket Addresses
一个Socket后缀类的实例和一个socket address关联,由IP和端口组成。这些类通常依赖InetAddress类代表socket address的IPv4 or IPv6 address portion;端口号是单独表示的。
Note: InetAddress依赖Inet4Address子类代表IPv4 address和Inet6Address代表IPv6 address。
InetAddress声明了几个方法获取InetAddress实例。这些方法包括:
- InetAddress[] getAllByName(String host) 返回InetAddresses的数组,储存了关联HOST的IP addresses。您可以将一个域名(如“tutortutor.ca”)或IP地址(如“70.33.247.10”)传递给这个参数。 (To learn about domain names, check out Wikipedia’s “Domain name” entry [http://en.wikipedia.org/wiki/Domain_name].) 传null获取的InetAddress实例储存了 loopback interface的IP address(一个基于软件的网络接口,输出的数据作为输入的数据返回)。当无法找到指定主机的IP地址时,或者为全局IPv6地址指定范围标识符时抛出UnknownHostException。
- InetAddress getByAddress(byte[] addr) 返回给定 raw IP address的InetAddress对象。数组遵循网络字节顺序(最重要的字节是第一位的)。 IPv4必须4字节,IPv6必须16字节。
- InetAddress getByAddress(String hostName, byte[] ipAddress)
- InetAddress getByName(String host) 返回一个InetAddress实例基于host,host可能是个machine name(such as “tutortutor.ca”)或者它的IP地址的文本表示。
- InetAddress getLocalHost() 返回 local host。 127.0.0.1 (IPv4) or ::1 (IPv6)
获得InetAddress对象后,调用getAddress()返回raw IP,以及boolean isLoopbackAddress(),代表是不是 loopback address。
Java 1.4 引入抽象类SocketAddress,代表with no protocol attachment的socket address(这个类的创建者可能已经预料到Java最终会支持低级别的通信协议而不是广受欢迎的互联网协议)。
SocketAddress被子类InetSocketAddress继承,把socket address表示为 IP address and a port number。它还可以表示主机名和端口号,并尝试解析主机名。
调用InetSocketAddress(InetAddress addr, int port)获取InetSocketAddress实例。然后调用 InetAddress getAddress() and int getPort() 等方法。
Socket Options
Socket后缀类的实例共享套接字选项的概念,是配置套接字行为的参数。Socket options是声明在SocketOptions接口的常数:
-
IP_MULTICAST_IF:用于确定组播(multicast)的网络接口。选项值类型为
InetAddress -
IP_MULTICAST_IF2:同#IP_MULTICAST_IF,但是可以设IPV4或IPV6地址。
-
IP_MULTICAST_LOOP:这个选项用于组播。其中“local loopback”的意思是组播包会同时发送给自己(即发送方可以收到自己发出去的数据)。
-
IP_TOS:用于设置IP包TOS部分的值。UDP可以在bind之后任意更改设置,TCP在bind前设置。
-
SO_BINDADDR:
- 只能通过
getOption读取,不能通过setOption设置。因为地址绑定发生在Socket初始化的时候,后面就不能更改了。 - 默认值为
INADDR_ANY。如果用于ServerSocket,即在“multi-homed host(同一主机上有多个网络地址)”的情况下,socket接收所有网络接口发过来的数据。设置了指定的Address,那么就接收指定接口的数据;如果用于Socket,设置了指定的Address表示向该地址发送数据。 - 该选项值的类型为
InetAddress
- 只能通过
-
SO_BROADCAST:决定了socket是否可以发广播。仅用于支持广播的网络。
-
SO_KEEPALIVE:启用时,当tcp连接中没有数据流动超过2小时时,系统主动发送一个keepalive探寻包(probe)给对方,对方必须响应这个包。收到ack的时候表示连接正常。满足以下条件时视为连接关闭:1、对方返回了RST;2、对方没有任何返回。
-
SO_LINGER:设置了一个大于0的值给
SO_LINGER,表示当关闭这个TCP socket时,如果发送队列里还有数据,那么堵塞等待一段时间( linger interval)。如果超时了,那么强制关闭连接。设置等于0 的值表示直接强制关闭连接。超时上限为65535。 -
SO_OOBINLINE:该选项默认disable,当enable时,表示urgent data直接在接收方read()操作中返回(和普通数据混在一起), 否则接收方直接忽略该数据。
-
SO_RCVBUF: 设置
SO_RCVBUF表示向内核建议socket接收缓冲区的大小。获取SO_RCVBUF一定返回实际接收缓冲区的大小。单位字节。 -
SO_REUSEADDR:仅用于
DatagramSocket(UDP)。一般来说,一个端口释放后会等待两分钟之后才能再被使用,SO_REUSEADDR是让端口释放后立即就可以被再次使用。 -
SO_SNDBUF:设置
SO_SNDBUF表示向内核建议socket发送缓冲区的大小。获取SO_SNDBUF一定返回实际发送缓冲区的大小。单位字节。 -
SO_TIMEOUT:
SO_TIMEOUT选项用于对read()操作设置timeout,单位为毫秒。当timeout发生时,会抛出InterruptedIOException。设置不大于0的值会令read()操作永远堵塞。 -
TCP_NODELAY:纳格算法(Nagle’s algorithm)的工作方式是合并(coalescing)一定数量的输出资料后一次送出。 当某application不断地发送小单位的数据时,tcp会缓存一定量的数据再进行发送。具体算法如下所示:
if there is new data to send if the window size >= MSS and available data is >= MSS send complete MSS segment now else if there is unconfirmed data still in the pipe enqueue data in the buffer until an acknowledge is received else send data immediately end if end if end if注:按照算法,是尚未收到前一次ack或未达到指定累积大小前缓存接下来的数据。TCP专用 综上,
TCP_NODELAY如果为true,那么数据就不进行缓存(等待上一个ack或达到指定累积大小)。
SocketOptions声明了get set方法。:
- void setOption(int optID, Object value)
- Object getOption(int optID)
不能直接调用,使用Socket后缀类的线程安全方法。
Socket and ServerSocket
Socket and ServerSocket classes支持客户端进程之间(比如在平板电脑上运行的应用程序)和服务端进程之间的基于tcp的通信。因为Socket和java.io.InputStream and java.io.OutputStream类关联,基于Socket类的sockets通常被称为stream sockets。
Socket支持客户端sockets的创建。下面有其中2个构造器:
- Socket(InetAddress dstAddress, int dstPort) 创建stream socket,连接到指定IP的端口。端口0 through 65535。
- Socket(String dstName, int dstPort)
Socket实例创建后,在remote host socket address的连接建立前,它被绑定到任意的local host socket address。Binding使 client socket address对 server socket可用,然后server进程可以通过server socket和客户端进程交流。
Socket提供额外构造器,比如Socket()未绑定,Socket(Proxy proxy)未连接。要使用这些,必须绑定到本地 socket addresses,调用void bind(SocketAddress localAddr),然后必须连接,调用 connect()方法。
Note:proxy是一个host,为了安全目的,处于内部网和Internet之间。 Proxy settings通过Proxy类的实例来表示,帮助套接字通过代理进行通信。
另一个构造器Socket(InetAddress dstAddress, int dstPort, InetAddress localAddr, int localPort),指定local host socket address,然后连接指定IP端口。
创建实例后,可能在实例上调用 bind() and connect(),调用Socket’s InputStream getInputStream() and OutputStream getOutputStream()用于读写。不需要I/O的时候调用Socket’s void close()关闭socket。
下面的例子演示了如何在本地主机上创建一个绑定到9999的socket,然后访问它的输入和输出流——为了简洁起见,忽略了异常:
Socket socket = new Socket("localhost", 9999);
InputStream is = socket.getInputStream();
OutputStream os = socket.getOutputStream();
// Do some work with the socket.
socket.close();
ServerSocket支持服务端sockets的创建,4个构造器:
- ServerSocket() 创建未绑定的server socket。你可以把它绑定到指定socket address。Binding使server socket address对客户端socket可用。
- ServerSocket(int port)创建server socket绑定到指定端口和与主机的一个nic相关联的IP地址。传0会选择任意的端口。getLocalPort()获取。来自客户端的传入的连接请求的最大队列长度为50。queue满了,连接被拒绝。
- ServerSocket(int port, int backlog) 设置传入连接的maximum queue length
- ServerSocket(int port, int backlog, InetAddress localAddress) 指定 IP address。多网卡时有用。
server socket创建后,server应用开始循环,先调用Socket accept()监听连接请求。然后通信,最后关闭。
Note: ServerSocket声明 close()来关闭server socket 。应用终止会自动关闭未关闭的socket。
下面的例子演示了如何创建一个服务器套接字,它被绑定到当前主机上的9999端口,监听传入的连接请求,返回它们的套接字,在这些套接字上执行工作,并关闭socket;为了简洁起见,忽略了异常:
ServerSocket ss = new ServerSocket(9999);
while (true)
{
Socket socket = ss.accept();
// obtain socket input/output streams and communicate with socket
socket.close();
}
accept()方法调用在连接可用之前阻塞,然后返回 Socket object和客户端通信。
这个例子假设套接字通信发生在服务器应用程序的主线程上,当处理需要时间来执行时,因为服务器响应时间对传入的连接请求减少是一个问题。
为了提高响应时间,通常需要与worker线程上的socket进行通信。如下面的例子所示:
ServerSocket ss = new ServerSocket(9999);
while (true)
{
final Socket s = ss.accept();
new Thread(new Runnable()
{
@Override
public void run()
{
// obtain socket input/output streams and
// communicate with socket
try { s.close(); } catch (IOException ioe) {}
}
}).start();
}
每次连接请求到来,accept()返回Socket实例,创建一个线程,在线程上访问socket和使用socket通信。
I’ve created EchoClient and EchoServer applications that demonstrate Socket and ServerSocket. Listing B-1 presents EchoClient’s source code.
Listing B-1. Echoing Data to and Receiving It Back from a Server
import java.io.*;
import java.net.Inet4Address;
import java.net.Socket;
/**
* @author @Jasu
* @date 2018-09-26 17:28
*/
public class EchoClient {
public static void main(String[] args) {
try {
Socket socket = new Socket(Inet4Address.getLocalHost(), 34343);
OutputStream os = socket.getOutputStream();
OutputStreamWriter writer = new OutputStreamWriter(os);
PrintWriter pw = new PrintWriter(writer);
pw.println("66666");
pw.flush();
InputStream is = socket.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
System.out.println(br.readLine());
} catch (IOException e) {
e.printStackTrace();
}
}
}
Note:长时间运行的应用要显示close socket。
server
Listing B-2. Receiving Data from and Echoing It Back to a Client
import java.io.*;
import java.net.Inet4Address;
import java.net.ServerSocket;
import java.net.Socket;
/**
* @author @Jasu
* @date 2018-09-26 17:37
*/
public class EchoServer {
public static void main(String[] args) throws IOException {
System.out.println("Starting echo server...");
ServerSocket ss = new ServerSocket(34343, 50, Inet4Address.getLocalHost());
while (true) {
Socket s = ss.accept();
try {
InputStream is = s.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String msg = br.readLine();
System.out.println(msg);
OutputStream os = s.getOutputStream();
OutputStreamWriter osw = new OutputStreamWriter(os);
PrintWriter writer = new PrintWriter(osw);
writer.println(msg);
writer.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
s.close();
} catch (IOException e) {
assert false;//should not happen in this context
}
}
}
}
}
DatagramSocket and MulticastSocket
DatagramSocket and MulticastSocket类让你执行UDP通信。
DatagramPacket构造:
byte[] buffer = new byte[100];
DatagramPacket dgp = new DatagramPacket(buffer, buffer.length);
DatagramSocket描述了用于客户端或者服务端UDP连接的socket。
Listing B-3 demonstrates DatagramPacket and DatagramSocket in a server context.
Listing B-3. Receiving Datagram Packets from and Echoing Them Back to ClientsListing B-3. Receiving Datagram Packets from and Echoing Them Back to Clients
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.SocketException;
/**
* @author @Jasu
* @date 2018-09-27 10:46
*/
public class DGServer {
final static int PORT = 10000;
public static void main(String[] args) throws SocketException {
System.out.println("Server is starting");
DatagramSocket dgs = new DatagramSocket(PORT);
try {
System.out.println("Send buffer size = " +
dgs.getSendBufferSize());
System.out.println("Receive buffer size = " +
dgs.getReceiveBufferSize());
byte[] data = new byte[50];
DatagramPacket dgp = new DatagramPacket(data, data.length);
while (true) {
dgs.receive(dgp);
System.out.println(new String(data));
dgs.send(dgp);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
虽然可以调用void setReceiveBufferSize(int size) and void setSendBufferSize(int size)挑整buffer size。来提高性能。但对于UDP有一个实际的限制。可以被发送接收的UDP包最大为65,507字节,在IPV4,它来自于从65,535中减去8字节的UDP头和20字节的IP头值
Listing B-4 demonstrates DatagramPacket and DatagramSocket in a client context. Listing B-4. Sending a Datagram Packet to and Receiving It Back from a Server
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
import java.net.SocketException;
/**
* @author @Jasu
* @date 2018-09-27 11:06
*/
public class DGClient {
final static int PORT = 10001;
final static String ADDR = "localhost";
public static void main(String[] args) throws SocketException {
System.out.println("client is starting");
DatagramSocket dgs = new DatagramSocket();
try {
byte[] buffer;
buffer = "Send me a datagram".getBytes();
InetAddress ia = InetAddress.getByName(ADDR);
DatagramPacket dgp = new DatagramPacket(buffer, buffer.length, InetAddress.getLocalHost(), PORT);
dgs.send(dgp);
byte[] buffer2 = new byte[100];
dgp = new DatagramPacket(buffer2, buffer.length, InetAddress.getLocalHost(), PORT);
dgs.receive(dgp);
System.out.println(new String(buffer2));
} catch (IOException e) {
e.printStackTrace();
}
}
}
MulticastSocket类描述了基于UDP的多播会话。
WHAT IS MULTICASTING?
前面的例子已经演示了单播,当服务器向单个客户端发送一条消息时发生。然而,也有可能向多个客户广播相同的信息。
IPv4 addresses 224.0.0.1 to 239.255.255.255 (inclusive) are reserved for use as multicast
group addresses.
Listing B-5 presents a multicasting server. Listing B-5. Multicasting Datagram Packets
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.InetAddress;
import java.net.MulticastSocket;
/**
* @author @Jasu
* @date 2018-09-27 13:49
*/
public class MCServer {
final static int port = 9999;
public static void main(String[] args) {
try {
MulticastSocket multicastSocket = new MulticastSocket();
InetAddress group = InetAddress.getByName("231.0.0.1");
byte[] dummy = new byte[0];
DatagramPacket dp = new DatagramPacket(dummy, 0, group, port);
int i = 0;
while (true) {
byte[] buffer = ("line " + i).getBytes();
dp.setData(buffer);
dp.setLength(buffer.length);
multicastSocket.send(dp);
i++;
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.InetAddress;
import java.net.MulticastSocket;
/**
* @author @Jasu
* @date 2018-09-27 13:54
*/
public class MCClient {
final static int port = 9999;
public static void main(String[] args) {
try {
MulticastSocket mcs = new MulticastSocket(port);
InetAddress group = InetAddress.getByName("231.0.0.1");
mcs.joinGroup(group);
for (int i = 0; i < 10; i++) {
byte[] buffer = new byte[256];
DatagramPacket dgp = new DatagramPacket(buffer, buffer.length);
mcs.receive(dgp);
byte[] buffer2 = new byte[dgp.getLength()];
System.arraycopy(dgp.getData(), 0, buffer2, 0, dgp.getLength());
System.out.println(new String(buffer2));
}
mcs.leaveGroup(group);
} catch (IOException e) {
e.printStackTrace();
}
}
}
Network Interfaces
略
« 深入理解 Java 虚拟机第三版
Java 并发编程实战 »